DD-012 Your Group-Relative Advantage Is Biased
arXiv: 2601.08521 Upvotes: 147 | Comments: 7 순위: 이번 주 Top 2
논문 리뷰: Your Group-Relative Advantage Is Biased (arXiv: 2601.08521)
1. 왜 이 논문이 중요한가?
DeepSeek-R1의 성공 이후, 대규모 언어 모델(LLM)의 추론 능력을 향상시키기 위해 **GRPO(Group Relative Policy Optimization)**와 같은 그룹 기반 강화 학습(RL) 방법이 표준처럼 쓰이고 있습니다. 기존 방법은 별도의 비평가(Critic) 모델 없이 그룹 내 평균 보상만으로 학습하지만, 이 논문은 이 접근법이 **“어려운 문제는 어렷게, 쉬운 문제는 쉽게” 판단하는 근본적인 편향(Bias)**을 가지고 있음을 수학적으로 증명했습니다. 이 논문은 단순히 성능을 높이는 것을 넘어, 현재 가장 핫한 LLM 학습 패러다임(RLVR)의 숨겨진 결함을 해부하고 과거 이력을 활용해 이 편향을 교정하는 HA-DW라는 강력한 해결책을 제시했다는 점에서 매우 중요합니다.
2. 핵심 아이디어 쉽게 이해하기
🎯 일상생활 비유: “너그러운 교사님 vs 엄격한 교사님”
이 논문의 핵심을 이해하려면 **‘시험을 치르는 학생과 채점하는 교사’**의 상황을 상상해 보세요.
-
기존 방식 (GRPO)의 문제점 - “기준이 없는 교사”: 교사가 시험 문제를 그룹별로 내줍니다.
- 상황 A (쉬운 문제): 그룹의 모든 학생이 100점을 맞았습니다. 교사는 “평균이 100점이니까, 100점 맞은 애는 그냥 보통이네?”라고 생각하며 **너무 높은 점수(과대평가)**를 줍니다. 학생들은 쉬운 문제만 계속 풀려고 합니다.
- 상황 B (어려운 문제): 아무도 못 풀고 한 학생만 겨우 10점을 받았습니다. 교사는 “이 그룹 평균이 2점이니까, 10점은 꽤 잘했네?”라고 생각할 수 있지만, 통계적으로 그룹 내 분산이 낮아서 진짜 실력보다 점수를 깎아(과소평가) 버립니다. 학생은 “어려운 문제를 풀어도 별 보상이 없구나”라고 느껴 포기합니다.
- 결과: 모델은 쉬운 문제에만 집착하고 어려운 문제는 외면하게 됩니다.
-
제안 방식 (HA-DW)의 해결책 - “성적부가 있는 교사”: 이 교사는 **지난 수년간의 학급 성적(이력, History)**을 가지고 있습니다.
- Evolutionary Difficulty Anchor (진화하는 난이도 기준): 교사는 “지금까지 우리 학급 실력이 보통 70점이었어”라는 **기준점(Anchor)**을 가지고 있습니다.
- Adaptive Reweighting (적응형 가중치 조정): 이번 시험에서 갑자기 문제가 너무 어려워서 점수가 10점 나왔더라도, **과거 이력(70점 실력)**을 고려해 “오늘 문제가 웬일이지 엄청 어려웠구나! 10점 맞은 애는 사실 실력이 100점이나 다름없어!”라고 판단하고 보상을 올려줍니다. 반대로 너무 쉬운 시험이면 보상을 낮춰줍니다.
⚙️ 단계별 동작 원리
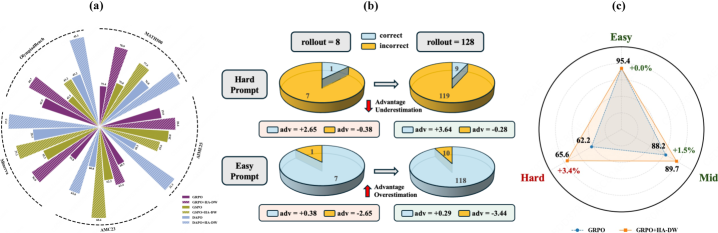
- 문제 발생 (Bias Identification): 기존 GRPO 알고리즘은 ‘그룹 내 평균’을 기준(Baseline)으로 삼는데, 이는 샘플링 수(G)가 적을 때 어려운 문제에서는 어드밴티지(이득)를 과소평가하고 쉬운 문제에서는 과대평가하는 편향을 만듭니다.
- 이력 기준 설정 (History-Aware Anchor): 모델이 학습하면서 과거에 얼마나 잘 풀었는지를 추적합니다. 마치 칼만 필터(Kalman Filter)처럼 현재 배치의 성적($y_t$)과 과거의 믿음($C_t^-$)을 섞어 모델의 현재 실력($C_t^+$)을 추정합니다.
- $$C_t^+ = (1-\eta_t)C_t^- + \eta_t y_t$$
- ($\eta_t$: 민감도 조절 계수)
- 난이도 보상 조정 (Adaptive Difficulty Weighting): 현재 추정된 모델 실력($C_t$)과 현재 문제의 성공 확률을 비교하여, 문제가 예상보다 어렵다면 가중치를 높여주고 쉽다면 낮춰줍니다. 이로써 왜곡된 어드밴티지를 편향되지 않은 상태로 보정합니다.
3. 실험 결과 분석
연구진은 수학 추론 벤치마크에서 Qwen3-4B-Base 모델을 사용해 성능을 검증했습니다.
- 테스트 벤치마크: MATH500, AIME25 (미국 수학 올림피아드 수준), AMC23, Minerva, OlympiadBench 등 고난도 수학 문제들입니다.
- 주요 성과 (구체적 수치 및 비교):
- 기존 GRPO 대비 향상: HA-DW를 적용한 GRPO는 일반 GRPO 대비 전체적인 평균 성능(AVG)에서 유의미한 향상을 보였습니다. 특히 AIME25와 같은超高난도 문제에서 성능 상승폭이 두드러졌습니다.
- 난이도별 분석 (Stratified Results): 논문의 Figure 1(c)를 보면, HA-DW는 특히 Hard(어려운) 레벨의 문제에서 기존 GRPO보다 훨씬 높은 정답률을 기록했습니다. 이는 앞서 설명한 “어려운 문제의 어드밴티지를 보정”하는 메커니즘이 실제로 작동했음을 증명합니다.
- 샘플 효율성: 적은 수의 롤아웃(rollouts, 생성 시도)에서도 편향을 줄여주어, 계산 비용을 늘리지 않고도 성능을 끌어올렸습니다.
4. 한계점과 향후 연구 방향
- 저자가 언급한 한계:
- 추가적인 하이퍼파라미터(기울기 조절, 이력 버퍼 크기 등)가 필요하여 튜닝이 다소 까다로울 수 있습니다.
- 완전한 비편향(Unbiased) 상태를 보장하기 위해서는 충분한 롤아웃 수가 필요하며, 극단적으로 적은 샘플에서는 여전히 불안정할 수 있습니다.
- 향후 연구 방향:
- HA-DW를 다른 GRPO 변형 알고리즘(GSPO, DAPO 등)과 결합하여 성능을 극대화하는 연구.
- 수학뿐만 아니라 코딩(Code)이나 논리적 추론이 필요한 다른 도메인으로의 일반화 가능성 확인.
5. 실무 적용 가능성
- 적용 분야:
- LLM 추론 능력 강화: 수학, 코딩, 복잡한 논리 질의를 다루는 LLM을 사후 학습(Post-training)시키는 모든 분야에 즉시 적용 가능합니다. 특히 “DeepSeek-R1”과 같은 추론 전문 모델을 학습시킬 때 필수적인 기술이 될 것입니다.
- 필요한 리소스:
- 추가 모델 불필요: Critic 모델을 따로 두는 PPO와 달리, GRPO 기반이므로 학습에 필요한 GPU 메모리가 상대적으로 적습니다.
- 데이터: RLVR(Verifier Rewards) 훈련이 가능한 데이터셋(보상을 줄 수 있는 환경 또는 검증 모델)이 필요합니다.
- 구현 난이도: 기존 GRPO 코드에 비해 상대적으로 단순한 수식(가중치 업데이트)만 추가하면 되므로, 엔지니어링 관점에서 구현 부담이 크지 않습니다.
6. 이 논문을 이해하기 위한 사전 지식
- RLHF (Reinforcement Learning from Human Feedback): 인간의 피드백이나 보상 신호를 통해 LLM을 인간이 선호하는 방향으로 튜닝하는 기법.
- PPO (Proximal Policy Optimization): OpenAI가 사용한 대표적인 강화 학습 알고리즘으로, 정책 업데이트가 너무 크지 않도록 제약하는 안정적인 알고리즘.
- GRPO (Group Relative Policy Optimization): PPO에서 비평가(Critic) 모델을 없애고, 같은 질문에 대한 여러 답변(그룹)의 평균 보상을 기준으로 삼아 메모리 효율을 극대화한 최신 알고리즘.
- Advantage Estimation (어드밴티지 추정): 특정 행동이 기준선(Baseline)보다 얼마나 더 좋았는지를 측정하는 값으로, 강화 학습에서 정책을 업데이트하는 방향을 결정하는 핵심 지표.
- Bias-Variance Tradeoff (편향-분산 트레이드오프): 모델이 학습 데이터에 너무 과적합되거나(분산), 너무 단순해져서(편향) 실제 성능이 떨어지는 현상 사이의 균형.
- Outcome Reward Model (ORM): 모델이 생성한 최종 결과(답)만 보고 점수를 매기는 보상 모델로, 추론 과정을 평가할 때 자주 쓰임.
- Kalman Filter (칼만 필터): 시스템의 상태를 추정하기 위해 과거의 데이터와 현재의 측정값을 결합하여 최적의 상태를 예측하는 알고리즘 (논문에서 이력을 관리하는 데 사용됨).
📚 이번 주 관련 Deep Dive
| 순위 | 논문 | Deep Dive |
|---|---|---|
| 🥇 | Agentic Reasoning for Large Languag… | DD-011 |
| 🥈 | Your Group-Relative Advantage Is Bi… | 📍 현재 문서 |
| 🥉 | EvoCUA: Evolving Computer Use Agent… | DD-013 |
| 4. | LLM-in-Sandbox Elicits General Agen… | DD-014 |
| 5. | Being-H0.5: Scaling Human-Centric R… | DD-015 |
📅 생성일: 2026-02-02 | 🤖 GLM-4.7 Deep Dive