📚 2026-03-02 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 dLLM: Simple Diffusion Language Modeling ⬆️65
- 📊📄 Enhancing Spatial Understanding in Image Gene… ⬆️41
- 📊📄 Recovered in Translation: Efficient Pipeline … ⬆️36
- 📊📄 CUDA Agent: Large-Scale Agentic RL for High-P… ⬆️34
- 📊📄 Mode Seeking meets Mean Seeking for Fast Long… ⬆️23
- 🤖📄 LK Losses: Direct Acceptance Rate Optimizatio… ⬆️15
- 🤖📄 Memory Caching: RNNs with Growing Memory ⬆️7
- 🤖📄 LongVideo-R1: Smart Navigation for Low-cost L… ⬆️6
- 🤖📄 SenCache: Accelerating Diffusion Model Infere… ⬆️5
- 🤖📄 DUET-VLM: Dual stage Unified Efficient Token … ⬆️2
1. dLLM: Simple Diffusion Language Modeling
arXiv: 2602.22661 | 기관: UC Berkeley | ⬆️ 65 | ⭐ 1883 📊 순위선정 | 📄 HTML 태그:
diffusion-language-modelllmopen-source-frameworkfine-tuningreproducibilityreasoningai-research사전 지식: Diffusion Models (확산 모델), Autoregressive Modeling (자기회귀 모델링), LoRA (Low-Rank Adaptation), Fine-tuning (미세 조정), Masked Language Modeling (마스크드 언어 모델링)
한 줄 요약
확산 언어 모델(Diffusion Language Models) 연구의 파편화된 코드와 구성 요소를 하나의 표준화된 오픈소스 프레임워크로 통합하여, 누구나 쉽게 재현하고 확장할 수 있도록 진입 장벽을 낮춘 데 있습니다.
💡 핵심 아이디어
각자 다른 규격과 부품을 사용하던 자동차 정비소들을 하나의 표준화된 정비 센터로 통합한 것과 비슷합니다. 연구자들은 더 이상 훈련(Training), 추론(Inference), 평가(Evaluation)를 위해 각기 다른 임시 코드를 짤 필요 없이, dLLM이라는 통합 도구 상자를 사용하여 모델의 부품(아키텍처나 목적 함수)을 레고처럼 쉽게 교체하고 조립할 수 있게 됩니다.
문제 정의
확산 언어 모델(DLMs) 분야가 빠르게 발전하고 있음에도 불구하고, 최신 모델들이 공유하는 핵심 구성 요소들이 여기저기 흩어진 임시 연구 코드베이스에 존재하거나 구현이 불투명하여 재현, 비교, 확장이 매우 어렵다는 문제를 해결하고자 합니다.
🔬 방법론 상세
- 모듈화된 트레이너(Trainer) 설계: 마스크드 확산(Masked Diffusion)과 블록 확산(Block Diffusion)과 같은 다양한 학습 목적 함수를 지원하며, 확산 모델링 로직을 모델 아키텍처로부터 철저하게 분리(Decoupling)하여 사용자가 코드를 크게 수정하지 않고도 새로운 변형을 추가할 수 있게 합니다.
- 통합된 파이프라인 제공: 훈련, 추론(Sampler), 평가(Evaluation)의 세 가지 핵심 구성 요소를 하나의 프레임워크 안에서 표준화하여 연구 개발의 생산성을 높입니다.
- AR-to-MDLM 어댑테이션: 기존의 자기회귀(Autoregressive) 언어 모델이나 BERT 스타일의 인코더를 경량의 미세 조정만을 통해 확산 언어 모델(DLM)로 변환할 수 있는 기법을 제안합니다.
핵심 기법
이 논문의 가장 중요한 기법은 ‘논리의 분리(Decoupling)‘입니다. 마치 소프트웨어 공학에서 인터페이스를 설계하듯, 모델의 구조(Transformer 등)와 모델을 학습시키는 방식(확산 방식)을 완전히 별개로 만들었습니다. 덕분에 연구자들은 새로운 모델을 만들 때마다 훈련 코드를 새로 짤 필요 없이, 기존의 트레이너에 새로운 모델 아키텍처를 꽂기만 하면 됩니다.
📊 정량적 결과
제공된 텍스트에는 구체적인 성능 향상 비율(%)은 명시되어 있지 않으나, 실험을 위해 다음과 같은 정량적인 하이퍼파라미터 설정을 사용하여 하류 성능(Downstream Performance)을 개선했다고 보고하고 있습니다.
주요 성과
- LoRA(Low-Rank Adaptation)를 적용하여 랭크(Rank) r=128, 알파(Alpha)=256의 설정으로 효율적으로 미세 조정을 수행했습니다.
- 학습률(Learning Rate) 10^-5, 전역 배치 사이즈(Global Batch Size) 32(그래디언트 누적 단계 4)를 사용하여 안정적인 학습을 달성했습니다.
- 8개의 A100 GPU와 DeepSpeed ZeRO-2를 활용하여 대규모 모델 학습 환경을 구축했습니다.
🚀 기존 대비 개선점
- 재현성(Reproducibility) 확보: 여기저기 흩어져 있던 연구 코드를 하나의 표준 프레임워크로 통합하여, 누구나 동일한 환경에서 결과를 재현하고 공정하게 비교할 수 있습니다.
- 낮아진 진입 장벽: 복잡한 구현 없이도 사전 학습된 오픈 가중치 모델을 가져와 경량의 미세 조정만으로도 확산 언어 모델을 개발할 수 있게 되어 연구자와 개발자 모두에게 접근성이 크게 향상되었습니다.
- 유연한 커스터마이제이션: 새로운 학습 목적이나 모델 아키텍처를 추가할 때 기존 코드를 뜯어고치는 리팩토링(Refactoring) 작업을 최소화했습니다.
🎯 활용 분야
- 추론(Reasoning) 능력 강화: 기존의 대규모 언어 모델(LLM)이 가진 추론 능력을 확산 방식의 반복적 정제(Iterative Refinement) 과정을 통해 더욱 향상시킬 수 있습니다.
- 고품질 텍스트 생성: 텍스트를 점진적으로 개선해 나가는 확산 모델의 특성을 살려 정교한 문장 생성이나 편집 작업에 활용할 수 있습니다.
- 모델 변환 및 배포: 이미 검증된 BERT나 GPT 계열의 모델을 확산 기반 모델로 쉽게 변환하여 특정 도메인이나 과제에 특화된 모델을 배포하는 데 사용할 수 있습니다.
한계 및 주의사항
- 저자들은 향후 dLLM 프레임워크를 계속 확장해 나갈 계획을 밝혔으며, 이는 현재 버전에서 다루지 못한 일부 최신 기법이나 아키텍처가 포함되지 않았을 수 있음을 시사합니다.
- 대규모 모델 학습을 위해서는 여전히 상당한 컴퓨팅 자원(예: 8개의 A100 GPU)이 필요하므로 개인이 사용하기에는 하드웨어적 제약이 있을 수 있습니다.
2. Enhancing Spatial Understanding in Image Generation via Reward Modeling
arXiv: 2602.24233 | 기관: Peking University | ⬆️ 41 | ⭐ 41 📊 순위선정 | 📄 HTML 태그:
text-to-imagespatial-reasoningreward-modelingreinforcement-learningdiffusion-modelsai-safetygrpocomputer-vision사전 지식: 강화 학습(Reinforcement Learning), 텍스트-투-이미지(Text-to-Image), 비전-언어 모델(Visual Language Model), 선호 학습(Preference Learning), LoRA(Low-Rank Adaptation)
한 줄 요약
텍스트-투-이미지 생성 모델의 가장 큰 약점인 복잡한 공간 관계 이해 능력을, 전용 데이터셋과 보상 모델을 통해 강화 학습으로 획기적으로 개선했다는 점에서 매우 중요합니다.
💡 핵심 아이디어
미술 학생에게 그림을 그리게 할 때 단순히 “그림이 예쁜지”만 평가하는 것이 아니라, “사과가 과연 책상 왼쪽에 있는지”와 같은 구도의 정확성을 엄격하게 채점하는 교수님을 만들어주는 것과 같습니다. 기존 모델은 화려한 색감에 현혹되어 물체 위치가 틀려도 높은 점수를 줬지만, 이 논문은 공간 위치가 틀린 그림과 맞는 그림을 짝지어 모델이 위치의 중요성을 깨닫게 만들었습니다.
문제 정의
현재의 텍스트-투-이미지(Text-to-Image) 모델들은 “고양이 왼쪽에 강아지가 있다”와 같이 복잡한 공간 관계가 포함된 프롬프트를 처리할 때 종종 실패합니다. 더 큰 문제는 모델을 학습시키는 보상 모델(Reward Model)조차도 미적 완성도가 높으면 공간 관계가 틀려도 높은 점수를 준다는 점입니다. 기존의 평가 방식(GenEval 등)은 물체가 가려져 있거나 프롬프트가 길어지면 제대로 작동하지 않아, 모델의 공간 추론 능력을 향상시키는 데 큰 걸림돌이 되었습니다.
🔬 방법론 상세
-
SpatialReward-Dataset 구축 기존 데이터셋과 달리 80,000개의 적대적 선호 쌍(Adversarial Preference Pairs)을 구성했습니다. GPT-5를 사용하여 복잡한 공간 관계가 포함된 프롬프트를 생성하고, 이 프롬프트의 공간 관계(예: 왼쪽/오른쪽 스왑)만 교란시킨 ‘방해된 프롬프트’를 만듭니다. 원본 프롬프트로 만든 이미지를 ‘정답(Winner)’, 방해된 프롬프트로 만든 이미지를 ‘오답(Loser)‘으로 설정하여 미적 차이를 배제하고 공간 관계의 정확성에만 집중하도록 데이터를 설계했습니다.
-
SpatialScore 아키텍처 및 학습 강력한 비전-언어 모델(Visual Language Model)인 Qwen2.5-VL-7B를 백본(Backbone)으로 사용하고, 언어 모델링 헤드 대신 선형 보상 헤드(Linear Reward Head)를 연결했습니다. LoRA(Low-Rank Adaptation)를 사용하여 파인 튜닝함으로써 모델이 가진 기존 지식을 보존하면서 보상 점수를 예측하도록 학습시켰습니다. 수식으로 표현하자면, 프롬프트 c와 생성 이미지 y가 입력되었을 때 보상 점수 s는 다음과 같습니다. $$ s = R_{\phi}(H_{\phi}(c, y)) $$ 여기서 $H_{\phi}$는 특징 추출기, $R_{\phi}$는 보상 예측기입니다.
-
GRPO를 통한 강화 학습 적용 학습된 SpatialScore 보상 모델을 활용해 GRPO(Group Relative Policy Optimization) 기반의 온라인 강화 학습(Online Reinforcement Learning)을 수행합니다. Top-k 필터링과 결합하여 생성 모델이 공간적으로 정확한 이미지를 생성하도록 튜닝합니다.
핵심 기법
이 논문의 가장 중요한 기법은 **‘적대적 프롬프트 교란(Adversarial Prompt Perturbation)‘**입니다. 그림의 퀄리티나 스타일은 똑같이 두고, 텍스트 명령어에 있는 “왼쪽”을 “오른쪽”으로 바꾸는 식으로 공간 정보만 조금씩 비틀어서 데이터를 만듭니다. 이렇게 하면 AI가 “예쁘다”가 아니라 “위치가 맞다”라는 기준만으로 정답과 오답을 구별하도록 훈련시킬 수 있습니다.
📊 정량적 결과
주요 성과
- 공간 평가 우위: 개발된 SpatialScore 모델은 공간 관계 평가 벤치마크에서 상업용 독점 모델(Proprietary Models)을 포함한 기존 최고 모델들을 모두 능가하는 성능을 보였습니다.
- 범용성 향상: 단순한 공간 배치뿐만 아니라, 여러 객체가 얽힌 긴 프롬프트(Long Prompts)와 객체가 서로 가려진(Occlusion) 상황에서도 기존 GenEval 방식 대비 훨씬 높은 평가 정확도를 기록했습니다.
- 생성 품질 개선: 이 보상 모델로 학습된 생성 모델은 T2I-CompBench 등 다양한 벤치마크에서 공간 추론(Spatial Reasoning) 능력이 기존 모델 대비 크게 향상되었습니다.
🚀 기존 대비 개선점
- 물체 가림(Occlusion) 처리: 물체가 다른 물체 뒤에 숨어 있어도 제대로 평가하는 능력을 갖췄습니다.
- 긴 프롬프트 일반화: 여러 객체의 복잡한 위치 관계가 포함된 긴 문장의 프롬프트에도 강건합니다.
- 공간 인식 강화: 기존 보상 모델들이 가지고 있던 미적 요소에 대한 편향을 제거하여 공간 정확성을 판단하는 데 집중합니다.
🎯 활용 분야
- 정밀 그래픽 디자인: 레이아웃과 객체 배치가 중요한 광고 이미지나 책 표지 자동 생성.
- 로봇 공학 및 시뮬레이션: 로봇이 특정 물체들을 주변 환경과의 공간적 관계를 고려해 조작하거나 배치하는 시나리오 생성.
- 교육 및 시각화: 기하학적 개념이나 복잡한 구조를 설명하는 정확한 도식 자료 만들기.
한계 및 주의사항
- 데이터 구축 비용: 고품질의 데이터 쌍을 만들기 위해 사람이 직접 검증하는(Manual Verification) 과정이 포함되어 있어 확장성에 제한이 있을 수 있습니다.
- 기반 모델 의존성: Qwen-Image나 HunyuanImage-2.1 같은 특정 생성 모델의 성능에 의존하여 데이터를 만들었기 때문에, 이 기반 모델들의 성능 한계가 데이터셋의 품질에 영향을 줄 수 있습니다.
3. Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets
arXiv: 2602.22207 | 기관: Institute for Computer Science, Artificial intelligence and Technology | ⬆️ 36 | ⭐ 13 📊 순위선정 | 📄 HTML 태그:
machine-translationnlp-benchmarkmultilingual-llmtest-time-computedata-centric-aiautomated-pipelinetranslation-quality사전 지식: Large Language Model (LLM), Test-time Compute, Machine Translation (MT), Semantic Drift, BLEU/COMET Metric

한 줄 요약
다국어 대형 언어 모델(Large Language Model)의 평가 신뢰성을 획기적으로 높이기 위해, 단순 번역을 넘어 테스트 타임 컴퓨팅(Test-time compute) 기법을 적용하여 벤치마크와 데이터셋의 번역 품질을 극대화하는 자동화된 파이프라인을 제안했기 때문입니다.
💡 핵심 아이디어
번역 결과물이 마치 원어민이 다듬은 것처럼 정교해지도록, 언어 모델이 여러 번역 후보를 생성하고 스스로 평가하여 가장 좋은 결과를 선택하는 과정을 반복하는 방식입니다. 마치 훌륭한 번역가가 초안을 여러 버전 만들어 놓고, 엄격한 교정자가 문맥과 뉘앙스를 가장 잘 살린 버전을 골라내는 식의 품질 관리 프로세스를 자동화했다고 보시면 됩니다.
문제 정의
기존의 다국어 벤치마크는 구글 번역이나 오래된 모델을 사용하여 번역된 경우가 많아, 의미가 왜곡되거나 문맥이 손실되는 문제(Semantic Drift)가 빈번합니다. 특히 질문과 보기(answer choice)를 따로 번역하면서 생기는 불일치로 인해, 모델의 진짜 성능을 제대로 측정하지 못한다는 치명적인 문제를 해결하고자 했습니다.
🔬 방법론 상세
- 테스트 타임 컴퓨팅 확장 전략 적용: 단일 번역 결과에 의존하지 않고, 높은 온도(Temperature) 설정을 통해 다양한 번역 후보군을 생성한 뒤 이를 비교 선정하는 Best-of-N 및 Fusion-of-N 방식을 활용했습니다.
- T-RANK (제안된 랭킹 방식): 여러 라운드에 걸쳐 번역 품질을 순위 매기는 다중 라운드 랭킹 방법을 도입하여, 가장 원문의 의도와 구조를 잘 살린 번역을 선별합니다.
- 문맥 유지 번역 구조: 데이터셋의 중첩된 구조를 평면화하여 처리하고, 질문과 답변을 별개로 번역하는 기존 방식 대신 서로 연결된 상태를 유지하며 번역하여 평가의 신뢰성을 높였습니다.
핵심 기법
이 논문의 가장 큰 특징은 ‘추론 시간 연산(Test-time compute)‘을 번역에 적용했다는 점입니다. 단순히 “이 문장을 번역해”라고 한 번 시키는 대신, “이 문장을 번역할 때 여러 가지 버전을 만들고, 그중 가장 문맥에 맞는 것을 스스로 골라봐”라고 모델에게 스스로 개선하도록 유도하여 인간에 준하는 수준의 번역 품질을 끌어냈습니다.
📊 정량적 결과
주요 성과
- FLORES 및 WMT24++ 벤치마크에서 기존 파이프라인 대비 COMET(번역 품질 평가 지표) 점수 유의미한 상승을 달성했습니다.
- 개선된 번역 벤치마크로 Gemma 3, Qwen 3, Llama 3.1과 같은 중형 모델들을 평가한 결과, 기존 번역된 벤치마크에서의 점수보다 더 높은 성능을 기록했습니다.
🚀 기존 대비 개선점
- 문맥 및 문법적 불일치 해소: 질문과 답변 간의 매칭 오류를大幅 줄여 평가의 정확도 향상
- 자원 효율성 증대: 고자원 언어(독일어, 스페인어 등)와 저자원 언어에 맞춰 유연하게 파이프라인을 구성하여 비용과 시간 절약
- 자동화 수준 고도화: 인간 개입을 최소화하면서도 전문적인 수준의 번역 품질 유지
🎯 활용 분야
- 다국어 LLM 성능 평가: 영어가 아닌 언어에서도 모델의 진짜 능력을 공정하게 측정 가능
- 저자원 언어 데이터 증강: 학습 데이터가 부족한 언어의 데이터셋을 고품질로 자동 구축
- 다국어 벤치마크 지속적 관리: 새로운 모델이 나올 때마다 벤치마크를 최신 언어 능력에 맞춰 자동 업데이트
한계 및 주의사항
- 이 연구는 주로 동유럽 및 남유럽 언어(복잡한 문법 구조를 가진 언어)에 초점을 맞춰 진행되어, 다른 어족(예: 아시아권 언어 등)으로의 일반화는 추가 검증이 필요할 수 있습니다.
- 여러 후보군을 생성하고 랭킹하는 과정이 포함되므로, 단순 번역보다 추론 비용이나 소요 시간이 다소 늘어날 수 있습니다.
4. CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
arXiv: 2602.24286 | 기관: ByteDance Seed | ⬆️ 34 📊 순위선정 | 📄 HTML 태그:
cudareinforcement-learningagentic-aicode-generationllmoptimizationkernel-benchmoe사전 지식: CUDA Kernel (GPU에서 실행되는 프로그램 단위), Reinforcement Learning (강화 학습), PPO (근접 정책 최적화 알고리즘), Compiler Optimization (컴파일러 최적화), Mixture of Experts (전문가 혼합 모델)
한 줄 요약
이 논문은 대규모 에이전트 강화 학습 시스템을 통해 기존 컴파일러 기반 도구를 뛰어넘는 최고 성능의 CUDA 커널을 생성하여, 언어 모델이 하드웨어 성능을 인식하고 최적화하는 능력을 본질적으로 획득하게 했다는 점에 중요한 의의가 있습니다.
💡 핵심 아이디어
자동차 엔진을 조립하는 견습 공원을 훈련시키는 것과 비슷합니다. 단순히 완성된 설계도(SFT 데이터)만 보여주는 기존 방식과 달리, 직접 엔진을 조립하고 시동을 걸어본 뒤 속도와 연비를 측정하여 피드백을 받으며 반복적으로 수정하는 시뮬레이션 환경(RL 환경)에 에이전트를 배치했습니다. 이를 통해 모델은 코드를 단순히 작성하는 것을 넘어, 스스로 프로파일링(프로그램의 수행 시간과 자원 사용량을 분석하는 것)하고 하드웨어의 특성에 맞춰 최적화하는 전문가의 기술을 체득합니다.
문제 정의
딥러닝의 성능을 좌우하는 GPU 커널 최적화는 매우 어렵고 전문적인 영역입니다. 최신 대규모 언어 모델(LLM)이 일반적인 코딩 능력에서는 인간을 따라잡았지만, CUDA 코드 생성에서는
torch.compile(PyTorch의 자동 최적화 도구) 같은 컴파일러 기반 시스템에도 미치지 못하는 성능을 보였습니다. 기존의 방식들은 모델의 본질적인 최적화 능력을 키우지 못해 성능에 한계가 있었고, 이를 극복하기 위한 새로운 접근 방식이 필요했습니다.
🔬 방법론 상세
- 확장 가능한 데이터 합성 파이프라인 (Scalable Data Synthesis Pipeline) 고성능 CUDA 커널 데이터의 부족 문제를 해결하기 위해, 기존의 작업들을 조합하여 새로운 훈련 과제를 만드는 방식을 사용했습니다. 여러 연산자(Operator)를 하나로 융합(Fusion)하는 과정을 통해, 개별 최적화의 단순 합 이상의 복잡한 최적화가 필요한 데이터셋을 대규모로 생성했습니다.
- 에이전트 강화 학습 환경 및 보상 설계 모델이 작성한 코드를 실제로 실행해보고 그 성능에 따라 보상을 주는 환경을 구축했습니다. 여기서 ‘비해킹 가능한(Non-hackable)’ 보상 설계를 통해 모델이 보상만 받으면 cheating 하는 방법을 찾지 못하도록 제약을 두었습니다. 또한 단일 턴이 아닌 최대 150~200번의 다중 턴(Multi-turn) 상호작용을 통해 코드를 수정하고 디버깅하는 과정을 학습합니다.
- 안정적인 강화 학습 알고리즘 PPO(Proximal Policy Optimization) 알고리즘을 기반으로 하며, 학습 초기의 불안정성을 막기 위해 사전 훈련된 가치 함수(Value Pretraining)와 RFT(Rejection Fine-Tuning) 기법을 사용했습니다. 문맥 윈도우(Context Window)를 최대 131,072까지 확장하여 긴 코드와 히스토리를 처리할 수 있도록 설정했습니다.
핵심 기법
가장 중요한 기법은 ‘실행 기반의 에이전트 강화 학습(Execution-driven Agentic RL)‘입니다. 이는 모델이 코드를 작성한 후 컴파일 오류가 나거나 성능이 낮으면 스스로 코드를 수정하는 과정을 반복하며 학습한다는 뜻입니다. 마치 사람 개발자가 코드를 짜고, 돌려보고, 느리면 수정하는 과정을 수천 번 반복해서 “아, 이 부분을 이렇게 고치면 GPU 메모리 대역폭을 아낄 수 있구나”라는 감각을 몸에 익히는 것과 같습니다.
📊 정량적 결과
주요 성과
- 전체 모델(CUDA Agent)은 기존 Eager 실행(즉시 실행 모드) 대비 평균 2.60배,
torch.compile대비 2.11배의 속도 향상을 달성했습니다. - KernelBench 벤치마크에서
torch.compile과 비교했을 때 무려 96.8%의 높은 통과율과 우위를 점했습니다. - 제거 실험(Ablation Study)에 따르면, 강화 학습 구성 요소(에이전트 루프, 강건한 보상, RFT 등)를 하나씩 빼면 성능이 급격히 하락하여, 제안된 시스템의 모든 요소가 필수적임을 입증했습니다.
🚀 기존 대비 개선점
- 단순한 코드 생성을 넘어 하드웨어(Hardware)의 특성을 고려한 성능 최적화가 가능해졌습니다.
- 실행 피드백(Execution Feedback)을 통해 코드의 논리적 오류뿐만 아니라 성능 병목을 스스로 찾아내어 수정하는 자율적인 디버깅 능력을 갖추었습니다.
- 다양한 연산자를 융합한 복잡한 문제에 대해서도 기존 최적화 도구보다 뛰어난 솔루션을 제시합니다.
🎯 활용 분야
- 딥러닝 프레임워크의 자동 커널 최적화 (PyTorch, TensorFlow 등)
- HPC(고성능 컴퓨팅) 분야의 사용자 정의 CUDA 커널 자동 생성
- 새로운 GPU 아키텍처에 대한 컴파일러 최적화 정책 자동 학습
한계 및 주의사항
- 학습 과정에서 막대한 컴퓨팅 자원이 소모됩니다. 총 2,300억 개의 파라미터를 가진 MoE(Mixture of Experts) 모델을 사용했으며, 이는 일반적인 연구 환경에서 재현하기 어려울 수 있습니다.
- 아직 완벽하지는 않으며, 가장 어려운 문제 난이도의 일부 하위 집합에서는 통과율이 다소 떨어질 수 있습니다(Overall 98.8% vs Subset 98.4%).
5. Mode Seeking meets Mean Seeking for Fast Long Video Generation
arXiv: 2602.24289 | 기관: NVIDIA | ⬆️ 23 📊 순위선정 | 📄 HTML 태그:
long-video-generationdiffusion-transformerflow-matchingrectified-flowvideo-aimode-seekingdistillationgenerative-model사전 지식: Rectified Flow (보정 흐름), Flow Matching (흐름 매칭), KL Divergence (쿨백-라이블러 발산), Knowledge Distillation (지식 증류), Sliding Window (슬라이딩 윈도우)
한 줄 요약
짧은 영상 데이터는 풍부하지만 긴 영상 데이터가 부족한 상황에서, 국소적 화질과 전체적 일관성을 분리하여 학습함으로써 몇 분짜리 장편 영상 생성을 가능하게 한 혁신적인 훈련 패러다임을 제시했기 때문입니다.
💡 핵심 아이디어
마치 소설을 집필할 때 문장 하나하나를 아름답게 다듬는 편집자와 전체적인 스토리 라인을 구성하는 작가가 각자의 역할에 집중하듯, 이 논문은 영상 생성 모델에게 두 가지 머리(head)를 부여합니다. 하나는 선생님 역할을 하는 짧은 영상 모델을 따라 하여 국소적인 화질을 높이고, 다른 하나는 긴 영상 데이터를 통해 전체적인 서사 구조를 학습하여 짧은 클립에서 장편으로 확장할 때 발생하는 퀄리티 저하 문제를 해결합니다.
문제 정의
영상 생성 모델을 5초짜리 짧은 클립에서 몇 분짜리 긴 영상으로 확장하려 할 때, 훈련 데이터의 부족과 모델이 긴 시간의 인과 관계를 이해하지 못해 영상이 중간에 망가지거나 맥락이 끊기는 ‘일관성’ 문제가 발생합니다.
🔬 방법론 상세
이 논문은 Decoupled Diffusion Transformer(분리된 확산 트랜스포머)라는 아키텍처를 사용하여 목적함수를 두 가지로 분리합니다.
- 전역적 Flow Matching 헤드 (Mean Seeking): 실제 긴 영상 데이터를 사용하여 지도 학습(Supervised Learning)을 수행합니다. 이는 영상 전체의 서사 구조와 긴 시간의 일관성(Long-term coherence)을 학습하는 역할을 하며, 분포의 평균(Mean)을 추구하여 긴 영상의 전체적인 틀을 잡습니다.
- 국소적 Distribution Matching 헤드 (Mode Seeking): 짧은 영상 생성에 특화된 선생님 모델(Frozen short-video teacher)로부터 슬라이딩 윈도우(Sliding window) 방식으로 지식을 증류합니다. 역방향 KL 발산(Reverse-KL Divergence)을 사용하여 분포의 최빈값(Mode)을 추구하며, 이를 통해 긴 영상 내의 작은 구간들이 높은 해상도와 사실적인 움직임을 유지하도록 합니다.
핵심 기법
기존에는 길게 늘어난 시간을 한 번에 다루려다 보니 국소적인 디테일이 흐려지거나 전체 스토리가 깨지는 딜레마가 있었습니다. 하지만 이 논문은 “Mean Seeking(전체 그림)“과 “Mode Seeking(국소 디테일)” 두 가지 학습 목표를 인위적으로 분리하여, 서로 방해받지 않고 각자의 강점만을 취함으로써 이 문제를 우아하게 해결했습니다.
📊 정량적 결과
주요 성과
- Wan 1.3B 및 14B 기반 모델에서 기존 방식(Long-context SFT, Mixed-lengths SFT) 대비 현저히 개선된 정성적, 정량적 성능을 보여주었습니다.
- 짧은 영상 모델 수준의 국소적 선명성과 움직임을 유지하면서도, 긴 영상에서의 장거리 일관성을 확보하여 Fidelity(충실도)-Horizon(시계) 간격을 획기적으로 좁혔습니다.
🚀 기존 대비 개선점
- 기존의 단순히 긴 영상으로 미세 조정(Fine-tuning)하는 방식보다 긴 영상 생성 시의 화질 저하 현상을 막았습니다.
- CausVid나 Self-Forcing 같은 자기회귀 방식과 비교하여 더 빠르고 안정적인 생성이 가능합니다.
- 추가적인 짧은 영상 감독(Supervision) 없이도 이미 학습된 짧은 영상 모델의 지식을 재사용하여 효율적입니다.
🎯 활용 분야
- 영화급 긴 스토리 영상 생성 및 캐릭터와 배경이 유지되는 애니메이션 제작
- 로봇이나 AI 에이전트를 위한 상호작용 가능한 가상 세계 모델 구축
- 긴 시간 동안 캐릭터의 정체성과 스타일을 유지해야 하는 고정밀 비디오 편집
한계 및 주의사항
- 긴 영상 훈련 데이터 자체가 희소하고 도메인이 제한적이라는 근본적인 데이터 문제는 완전히 해결되지 않았으며, 모델이 학습된 데이터 패턴을 벗어난 새로운 사건을 생성하는 데는 여전히 한계가 있을 수 있습니다.
6. LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding
arXiv: 2602.23881 | 기관: Nebius | ⬆️ 15 🤖 GLM추천 | 📄 HTML 태그:
speculative-decodingllm-inferenceloss-functionmodel-compressionnlpoptimizationdraft-modelacceptance-rate사전 지식: Speculative Decoding (추적 디코딩), KL Divergence (KL 발산), Draft Model (드래프트 모델), Logits (로짓), Total Variation Distance (총 변동 거리)
한 줄 요약
추적 디코딩(Speculative Decoding)의 효율을 결정짓는 수락률(Acceptance Rate)을 기존의 대리 지표인 KL 발산 대신 직접 최적화하는 새로운 손실 함수인 LK Losses를 제안하여, 용량이 작은 드래프트 모델의 성능을 극대화하고 추론 속도를 획기적으로 높인다.
💡 핵심 아이디어
마치 셰프(타겟 모델)가 검토하는 주방 조수(드래프트 모델)를 훈련할 때, 셰프의 레시피와 비슷하게 만드는 것(KL 발산 최소화)만으로는 부족하다는 점에 착안했습니다. 대신, 실제로 셰프가 이 요리를 그대로 통과시킬 확률(수락률)을 높이는 방향으로 직접 훈련시키면, 능력이 제한된 조수도 최대한 쓸모 있는 결과물을 만들어낼 수 있습니다.
문제 정의
기존 추적 디코딩 연구들은 드래프트 모델을 훈련시킬 때 타겟 모델과의 확률 분포 차이를 줄이는 KL 발산(Kullback-Leibler divergence)을 사용했습니다. 하지만 작은 드래프트 모델은 타겟 모델과 완벽히 같아지는 불가능한 상태(Global optimum)에 도달하지 못하므로, KL 발산을 줄인다고 해서 실제 추론 속도를 결정하는 ‘수락률’이 최대가 되지 않는다는 비효율적인 문제가 있었습니다.
🔬 방법론 상세
- 직접 최적화 목적함수(Direct Optimization Objective): 수학적으로 수락률(Acceptance Rate) $\alpha$은 두 확률 분포 $p$와 $q$의 최소값 합인 $\sum \min(q, p)$와 같습니다. 이를 최대화하는 것은 총 변동 거리(Total Variation distance, TV)를 최소화하는 것과 수학적으로 동치이므로, TV 거리를 최소화하는 방향으로 학습합니다.
- 기울기(Gradient) 분석: 기존 KL 발산의 기울기는 $\nabla KL = q - p$로 단순하지만, 초기 학습 단계에서 분포 차이가 클 때 최적화 효율이 떨어질 수 있습니다. 반면 제안하는 방식은 수락률 자체에 집중하여 분포가 겹치는 영역을 넓히는 방향으로 더 효과적으로 학습을 유도합니다.
- LK Losses 적용: 이론적 분석을 바탕으로, TV 거리 최소화와 같은 효과를 내면서도 실제 학습에서 안정적으로 수렴하는 LK 손실 함수들을 새롭게 정의하여 드래프트 모델의 파라미터를 업데이트합니다.
핵심 기법
이 논문의 핵심은 ‘목적함수를 다시 정의’하는 것입니다. 기존에는 “타겟 모델을 잘 흉내 내라(KL 최소화)“고 시켰다면, 이번에는 “타겟 모델이 승인할 확률을 직접 높여라(수락률 최대화)“라고 시킵니다. 이는 시험을 준비하는 학생에게 “교과서를 그대로 외워라”고 시키는 것보다, “정답을 맞출 확률을 높이는 공부를 해라”고 시키는 것과 같은 전략입니다.
📊 정량적 결과
주요 성과
- 광범위한 모델 검증: 8B에서 685B 파라미터까지의 6가지 타겟 모델과 4가지 드래프트 아키텍처에서 실험을 수행했습니다.
- 일관된 성능 향상: Figure 1의 데이터에 따르면, 기존 목적함수로 훈련된 모델보다 훨씬 더 긴 수락 길이(Acceptance Length)를 기록하며, KL 발산을 최소화하는 것보다 더 높은 수락률을 달성했습니다.
🚀 기존 대비 개선점
- 용량이 작은 드래프트 모델도 타겟 모델의 특성을 더 잘 흉내 내어 실제 서비스 환경에서 더 많은 토큰을 한 번에 생성할 수 있습니다.
- 훈련 목적이 실제 추론 성능 지표(수락률)와 직접 연결되어 있어, 기존 방식보다 효율적인 모델 최적화가 가능합니다.
- 특정 아키텍처에 국한되지 않고 다양한 드래프트 구조(EAGLE 등)에 적용 가능한 범용 손실 함수입니다.
🎯 활용 분야
- 대규모 언어 모델(LLM) 추론 서비스의 비용 절감 및 지연 시간(Latency) 단축
- 하드웨어 자원이 제한적인 엣지(Edge) 디바이스에서의 고성능 AI 배포
- 실시간 대화형 챗봇이나 코딩 어시스턴트 등 빠른 반응 속도가 중요한 애플리케이션
한계 및 주의사항
- 총 변동 거리(TV) 최소화를 기반으로 한 최적화는 이론적으로 유리하지만, 실제 구현 시 기울기(Gradient) 계산이 복잡하여 학습 안정성을 확보하는 추가적인 기술이 필요할 수 있습니다.
- 수락률은 높아졌으나, 드래프트 모델이 생성하는 토큰의 다양성이나 품질 측면에서는 다른 트레이드오프가 발생할 가능성이 있습니다.
7. Memory Caching: RNNs with Growing Memory
arXiv: 2602.24281 | ⬆️ 7 🤖 GLM추천 | 📄 HTML 태그:
recurrent-neural-networksmemory-cachingsequence-modelingefficient-transformersassociative-memorylong-context사전 지식: RNN(순환신경망), Transformer, Attention Mechanism(어텐션 메커니즘), Associative Memory(연상 기억), Quadratic Complexity(이차 복잡도)
한 줄 요약
이 논문이 중요한 이유는 순환신경망(RNN)의 계산 효율성은 유지하면서 트랜스포머와 같이 긴 문맥을 기억하는 능력을 부여하여, 계산 복잡도와 성능 사이의 트레이드오프를 획기적으로 개선했기 때문입니다.
💡 핵심 아이디어
기존 RNN이 책을 읽되 마지막 문장만 기억하는 것과 같다면, 트랜스포머는 책의 모든 문장을 완벽하게 암기해 버리는 것과 같습니다. 이 논문의 메모리 캐싱 기법은 중요한 시점마다 ‘요약 노트(캐시)‘를 작성해 두고 필요할 때 꺼내 보는 것처럼, 뇌의 고정된 용량(메모리 상태)을 초과하지 않으면서도 먼 과거의 내용을 효율적으로 상기할 수 있게 해줍니다.
문제 정의
트랜스포머는 모든 과거 정보를 저장하는 연상 기억(Associative Memory) 역할을 하여 높은 성능을 보이지만, 문맥 길이가 길어질수록 계산 복잡도가 제곱으로 증가하는 문제가 있습니다. 반면 기존 RNN은 과거 정보를 압축하여 고정된 크기의 메모리만 사용하므로 계산은 효율적이지만, 먼 과거의 정보를 잊어버려 검색이나 회상 능력이 떨어지는 치명적인 단점이 있습니다.
🔬 방법론 상세
- 시퀀스 분할 및 압축: 입력 시퀀스를 여러 세그먼트(Segment)로 나누고, 각 세그먼트를 처리한 후의 메모리 상태를 계산합니다. 이때 메모리 업데이트 규칙 $f(\cdot)$을 사용하여 과거 정보를 현재 상태에 통합합니다.
- 메모리 상태 캐싱: 기존 RNN은 가장 최신의 메모리 상태만 유지하지만, 이 방법은 특정 시점의 메모리 상태를 체크포인트처럼 저장해 둡니다. 이렇게 저장된 과거의 메모리 $\mathcal{M}^{(i)}$는 이후 토큰이 처리될 때 직접 접근하여 참조할 수 있습니다.
- 복잡도 보간: 캐싱을 얼마나 자주 하느냐에 따라 계산 비용을 선형인 $O(L)$과 이차형인 $O(L^2)$ 사이에서 조절할 수 있도록 설계했습니다.
핵심 기법
메모리 캐싱(Memory Caching)은 단순히 과거의 은닉 상태(Hidden State)를 버리지 않고 보관했다가, 나중에 현재 입력이 이 과거 정보를 참조해야 할 때마다 꺼내 쓰는 기술입니다. 이는 마치 트랜스포머의 어텐션 메커니즘을 RNN 구조 위에 얹어 놓아, 필요할 때만 과거를 돌아볼 수 있는 ‘지능형 북마크’를 제공하는 것과 같습니다.
📊 정량적 결과
주요 성과
- 계산 복잡도 측면에서 완전한 트랜스포머의 $O(L^2)$와 기존 RNN의 $O(L)$ 사이에서 유연하게 조절 가능함을 수식적으로 증명했습니다.
- 다양한 베이스라인 모델 대비 회상 중심(Recall-intensive) 작업에서 성능 향상을 보였습니다.
🚀 기존 대비 개선점
- 트랜스포머에 비해 추론 시간 메모리 사용량(Inference-time memory)을 획기적으로 줄이면서도 긴 문맥을 처리할 수 있습니다.
- 고정된 메모리 크기를 가진 기존 RNN의 병목 현상을 해결하여, 모델의 유효 메모리 용량이 시퀀스 길이에 따라 증가할 수 있게 되었습니다.
🎯 활용 분야
- 긴 영상 데이터를 실시간으로 처리해야 하는 비디오 분석 시스템
- 방대한 문맥 이해가 필요하지만 빠른 응답 속도가 중요한 장문 언어 모델링
- 과거의 이력을 기반으로 추천해야 하는 실시간 추천 시스템
한계 및 주의사항
- 현재 연구에서는 메모리 캐싱의 아이디어를 명확히 보여주기 위해 모델 구조를 최대한 단순하게 설계했으므로, 성능 한계가 존재할 수 있습니다.
- 향후 연구에서는 더 표현력이 풍부한 풀링(Pooling)이나 라우팅(Routing) 메커니즘을 도입하여 성능을 进一步 향상시켜야 합니다.
8. LongVideo-R1: Smart Navigation for Low-cost Long Video Understanding
arXiv: 2602.20913 | 기관: ucas | ⬆️ 6 | ⭐ 18 🤖 GLM추천 | 📄 HTML 태그:
long-video-understandingmllmagentefficiencyactive-navigationreasoninghierarchical-captionvideo-qa사전 지식: 멀티모달 대형 언어 모델(Multimodal Large Language Model), 컨텍스트 윈도우(Context Window), 강화 학습(Reinforcement Learning), 에이전트(Agent), 파레토 최적(Pareto-optimal)
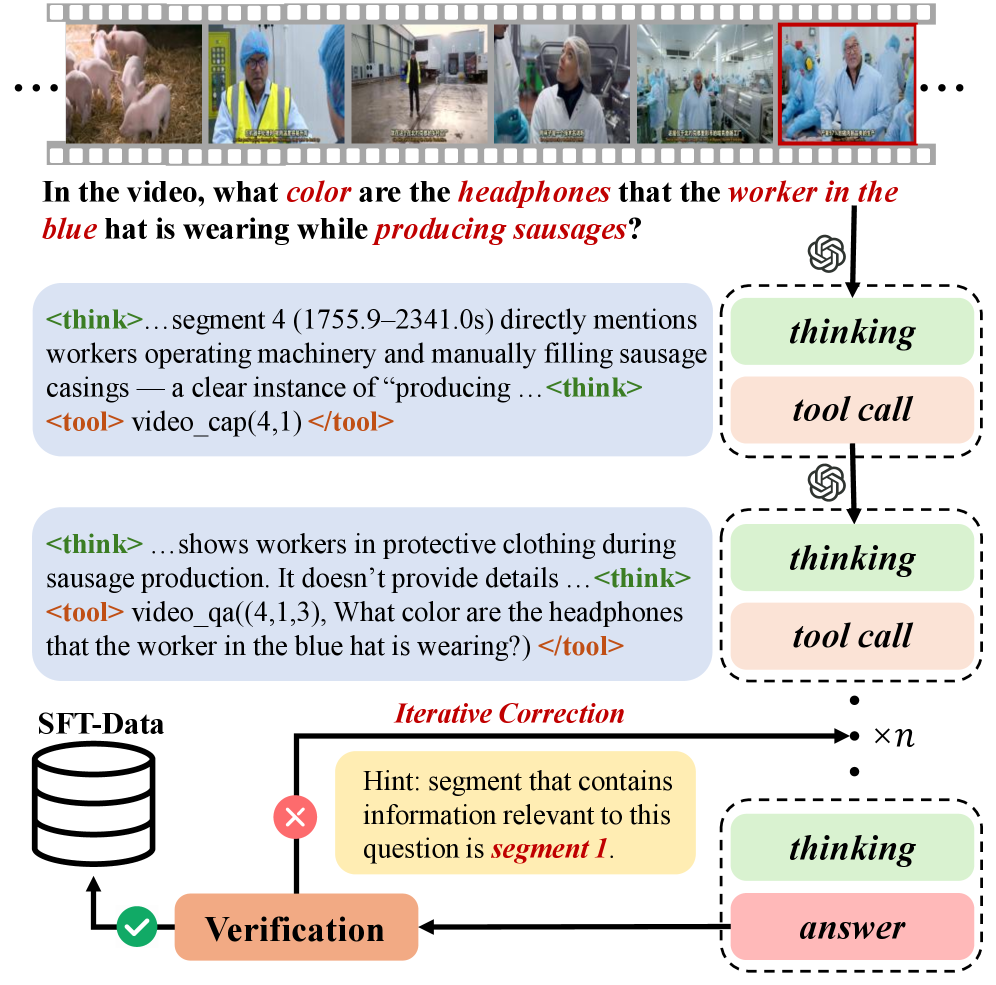
한 줄 요약
긴 영상을 이해하기 위해 무작정 전체를 처리하는 기존 방식의 비효율을 개선하여, 적은 연산량으로도 높은 정확도를 유지하며 필요한 정보만 똑똑하게 찾아내는 지능형 멀티모달 에이전트 프레임워크를 제시했기 때문에 중요합니다.
💡 핵심 아이디어
이 모델은 마치 두꺼운 책을 읽을 때, 처음부터 끝까지 단어 하나하나 다 읽는 대신 목차를 먼저 훑어보고 필요한 챕터로 이동한 뒤, 정답을 찾는 순간 바로 읽기를 멈추는 방식을 사용합니다. 영상의 가장 큰 요약부터 시작하여 점점 세부적인 장면으로 범위를 좁혀나가는 위계적인 탐색 과정을 통해 컴퓨터의 연산 낭비를 막습니다.
문제 정의
최신 멀티모달 대형 언어 모델(MLLM)로 1~2시간 분량의 긴 영상을 이해하려면, 영상을 잘게 쪼개 모든 구간을 처리하는 무리한 과정(Brute-force pipeline)이 필요합니다. 이는 모델의 문맥 창(Context Window) 한계를 넘어설 뿐만 아니라, 영상 길이에 비례해 계산 비용이 선형적으로 증가하여 실시간 서비스나 로봇 같은 저지연 애플리케이션에 적용하기 어렵다는 문제가 있습니다.
🔬 방법론 상세
- 폐루프 탐색 메커니즘(Closed-loop mechanism)
- 모델이 스스로 판단하여 영상의 어느 부분을 볼지 결정하고, 충분한 정보를 얻었다고 판단되면 즉시 탐색을 멈추는 자기 조절 기능을 사용합니다.
- CoTwT(Chain of Thought with Termination) 궤적 생성
- GPT-5와 같은 강력한 모델을 활용하여, 최상위 요약에서 시작해 정답을 찾을 때까지 단계적으로 추론하며 멈추는 시점을 결정하는 학습 데이터를 만듭니다.
- 위계적 비디오 캡션(Hierarchical Video Captions)
- Qwen2.5-VL-72B 모델을 사용해 영상을 여러 단계(레벨 0
3)의 밀도로 요약하며, 각 단계별로 서로 다른 프레임 수(예: 256개32개)를 처리하여 효율적인 정보 계층을 구성합니다.
- Qwen2.5-VL-72B 모델을 사용해 영상을 여러 단계(레벨 0
핵심 기법
가장 중요한 기법은 ‘추론 기반 조기 종료(Reasoning and Termination Control)‘입니다. 모델은 단순히 영상을 보는 것을 넘어, 현재까지 본 정보만으로 질문에 답할 수 있는지를 지속적으로 평가합니다. 답할 수 있다면 바로 멈추고, 부족하다면 어느 시점으로 이동해야 할지 추론하여 다음 클립을 선택하는 능동적인 지능이 핵심입니다.
📊 정량적 결과
논문의 텍스트에는 구체적인 정확도 향상률(예: 10% 개선)에 대한 수치는 명시되어 있지 않으나, 다음과 같은 정량적 데이터를 제시합니다.
- 데이터셋 규모: CG-Bench 데이터셋의 800개 비디오와 5,600개의 질의응답(QA) 쌍을 사용하여 학습 궤적을 생성했습니다.
- 효율성 개선: 기존 방식(Ego-R1, Videotree)은 영상 길이에 따라 비용이 선형적으로 증가하지만, LongVideo-R1은 필요한 부분만 탐색하여 파레토 최적(Pareto-optimal)에 가까운 정확도와 효율성의 균형을 달성했습니다.
주요 성과
- CG-Bench 벤치마크에서 기존 최상위 모델들과 대등하거나 더 우수한 QA 정확도를 기록했습니다.
- 단순한 질의응답을 넘어, 정보 검색(Information Retrieval) 및 정답이 포함된 구간 위치 찾기(Grounding) 작업에서도 뛰어난 성능을 보였습니다.
🚀 기존 대비 개선점
- 능동적 탐색(Active Navigation): 영상의 모든 구간을 처리하는 것이 아니라, 질문과 관련 있는 구간을 유추하여 선택적으로 탐색합니다.
- 계산 비용 절감: 영상 길이에 상관없이 일정 수준의 연산량을 유지하며 답변을 생성하여 저지연(Low-latency) 환경에 적합합니다.
- 계층적 추론(Hierarchical Reasoning): 거시적인 안목에서 점진적으로 미시적인 안목으로 이동하는 방식을 통해 불필요한 세부 정보를 배제합니다.
🎯 활용 분야
- 저지연이 필요한 임베디드 에이전트(Embodied Agents): 현실 세계에서 로봇이나 AI가 영상을 실시간으로 분석하여 즉각적인 행동을 취해야 할 때 유용합니다.
- 비용 제약이 있는 비디오 채팅 서비스: 사용자가 긴 영상을 업로드하거나 질문할 때, 서버의 부하를 줄이면서 빠르게 답변을 제공해야 하는 대규모 서비스에 적합합니다.
한계 및 주의사항
- 사전 요약 의존성: 효율적인 탐색을 위해 위계적인 비디오 캡션이나 요약이 미리 생성되어야 하므로, 완전히 새로운 영상에 대해서는 이러한 전처리 과정이 추가로 필요할 수 있습니다. 저자는 광범위한 사전 처리가 필요한 접근법은 저지연 요구사항을 충족하지 못할 수 있다고 언급하며 이 부분의 균형이 중요함을 시사합니다.
9. SenCache: Accelerating Diffusion Model Inference via Sensitivity-Aware Caching
arXiv: 2602.24208 | ⬆️ 5 | ⭐ 6 🤖 GLM추천 | 📄 HTML 태그:
diffusion-modelsinference-accelerationcaching-sensitivityflow-matchinggenerative-aivideo-generationoptimizationmodel-efficiency사전 지식: Diffusion Models (디퓨전 모델), Flow Matching (플로우 매칭), Jacobian Matrix (야코비안 행렬), ODE (Ordinary Differential Equation, 상미분방정식), Latent Space (잠재 공간)
한 줄 요약
이 논문은 모델 재학습 없이 수학적 민감도(Sensitivity) 분석을 통해 캐시를 재사용할 최적의 시점을 정확히 판단함으로써, 디퓨전 모델의 추론 속도를 획기적으로 높이고 비용을 절감하기 때문에 중요합니다.
💡 핵심 아이디어
비디오 생성 과정을 자동차 운전에 비유해 볼 수 있습니다. 기존 방식은 도로 상황과 관계없이 매초마다 운전대를 꽉 잡고 제어해야 했다면, 이 방법론은 도로가 직선이고 평평할 때(즉, 모델의 출력 변화가 민감하지 않을 때)는 일시적으로 손을 떼고 캐시(Cache)에 저장해 둔 과거 상태를 재사용하여 운전대를 조작하는 횟수를 줄이는 스마트한 크루즈 컨트롤과 같습니다.
문제 정의
디퓨전 모델(Diffusion Model)은 고품질 비디오를 생성하지만, 수백 번의 순차적인 노이즈 제거(Denoising) 단계가 필요해 추론 비용이 매우 높습니다. 기존의 캐싱 기반 가속 방법들은 캐시를 언제 재사용할지 결정하는 기준이 경험적(Heuristic)이라서, 모델이나 데이터에 따라 성능이 들쑥날쑥하고 별도의 세밀한 튜닝이 필요하다는 문제가 있었습니다.
🔬 방법론 상세
- 민감도(Sensitivity) 공식화: 모델 출력이 입력 잠재 변수(Noisy Latent)와 타임스텝(Timestep)의 작은 변화에 얼마나 반응하는지를 수학적으로 정의합니다. 이를 야코비안 노름(Jacobian Norm)을 통해 계산하여, 모델이 해당 구간에서 얼마나 민감하게 반응하는지 측정합니다.
- 유한 차분 근사(Finite-Difference Approximation): 실제로 야코비안을 매번 계산하는 것은 비싸기 때문에, 현재 입력과 아주 작은 변화가 있는 입력 간의 모델 출력 차이를 이용해 민감도를 효율적으로 근사합니다. 이를 통해 추가적인 연산 비용을 최소화합니다.
- 통합 메트릭 및 캐싱 결정 규칙: 잠재 변수 변화에 대한 민감도와 시간 단계 변화에 대한 민감도를 결합한 메트릭을 제안합니다. 이 메트릭이 특정 임계값보다 낮으면(즉, 모델 반응이 둔하면) 이전 단계의 출력을 재사용하고, 높으면 새로운 연산을 수행합니다.
핵심 기법
가장 중요한 핵심은 수학적 근거에 기반한 ‘민감도 임계값’ 설정입니다. 마치 네비게이션이 “도로가 울퉁불퉁하니 속도를 줄여라(새로 계산해라)“와 “도로가 매끄러우니 속도를 유지해라(캐시를 써라)“를 정확히 판단해주는 원리입니다. 이를 위해 단순히 출력 값의 크기만 보는 것이 아니라, 입력이 아주 조금 변했을 때 출력이 얼마나 크게 움직이는지를 계산하여 캐시 사용의 안전성을 보장합니다.
📊 정량적 결과
주요 성과
- 추론 속도 및 연산량 감소: 기존 캐싱 방법(TeaCache, MagCache) 대비 더 많은 연산 단계를 건너뛰면서도, 고품질의 비디오를 유지하여 전체적인 추론 시간과 FLOPs(Floating Point Operations)를 효과적으로 줄였습니다.
- 품질 유지: FID(Fréchet Inception Distance) 및 CLIP 점수 등 생성 품질 지표에서 기존 방법들과 동등하거나 더 우수한 성능을 보이며, 노이즈 제거 품질 저하 없이 속도를 높였습니다.
🚀 기존 대비 개선점
- 원칙 기반의 접근(Principled Approach): 기존 방법들이 단순 실험적 규칙(Heuristic)에 의존한 것과 달리, 민감도 분석이라는 수학적 이론에 기반하여 캐시 재사용을 결정하므로 모델이나 데이터셋이 바뀌어도 강인한 성능을 보입니다.
- 추가 훈련 불필요(Training-free): 모델의 파라미터를 수정하거나 추가적인 미세 조정(Fine-tuning) 없이 추론 단계에서만 적용이 가능하여 적용 비용이 매우 낮습니다.
- 범용성: Flow Matching 등 다양한 디퓨전 기반 생성 모델에 적용할 수 있는 일반적인 프레임워크를 제공합니다.
🎯 활용 분야
- 실시간 비디오 생성 애플리케이션: 사용자가 프롬프트를 입력하고 몇 초 만에 고화질 비디오를 생성해야 하는 서비스나 앱.
- 엣지 디바이스 내 생성 모델: 서버가 아닌 개인용 컴퓨터나 모바일 기기 등 연산 능력이 제한적인 환경에서 로컬로 생성 모델을 구동할 때.
- 대규모 비디오 제작 스태빙(Sampling) 프로세스: 영화나 애니메이션 제작 등 수많은 샘플을 생성해야 하는 산업 현장에서의 전력 및 시간 절약.
한계 및 주의사항
- 보정(Calibration) 비용: 민감도를 정확히 추정하기 위해 소규모의 데이터셋을 사용한 사전 계산 과정이 필요하며, 이 과정이 완전히 무료는 아닙니다.
- 높은 민감도 구간에서의 효과: 생성 과정 초기나 중반에 모델이 매우 민감하게 반응하는 구간에서는 캐시를 재사용하기 어려워 가속 효과가 상대적으로 떨어질 수 있습니다.
10. DUET-VLM: Dual stage Unified Efficient Token reduction for VLM Training and Inference
arXiv: 2602.18846 | 기관: AMD | ⬆️ 2 | ⭐ 13 🤖 GLM추천 | 📄 HTML 태그:
vlmefficiencytoken-reductionmultimodalcompressioninference-optimizationclipllava사전 지식: Vision-Language Model (VLM), Token, Attention Map, Clustering, Pruning

한 줄 요약
이 논문은 시각 언어 모델(VLM)의 처리 속도와 효율성을 극대화하기 위해, 시각 인코더 단계에서의 중복 토큰 병합과 언어 백본(Language Backbone) 단계에서의 텍스트 주도 토큰 삭제를 결합한 이중 단계 압축 프레임워크를 제안하여 기존 방식 대비 훨씬 적은 토큰으로도 높은 정확도를 유지한다는 점에서 중요합니다.
💡 핵심 아이디어
마치 만화책을 읽을 때, 배경의 디테일을 대표하는 몇 개의 그림으로 요약해서 머릿속에 넣고(Vision-side compression), 대화 내용을 읽을 때는 현재 대화와 관련 없는 그림은 무시하는 방식(Text-guided pruning)으로 뇌의 처리 부하를 줄이는 것과 같습니다.
문제 정의
이미지가 모델로 들어오면 수천 개의 시각 토큰(Visual token)으로 변환되는데, 이로 인해 계산량이 급격히 늘어나고 메모리 사용량이 과도해지는 문제를 해결하고자 합니다. 기존의 효율화 방법들은 토큰을 줄이면 성능이 떨어지는 딜레마가 있었습니다.
🔬 방법론 상세
- 이중 단계 압축 프레임워크 (Dual-stage compression): 시각 인코더 출력 단계와 언어 모델 처리 단계에서 각각 다른 전략을 사용하여 토큰을 효율적으로 줄입니다.
- 시각 토큰 클러스터링 (Clustering of vision tokens):
- CLIP(Clip-style model)의 마지막 레이어에서 추출한 주의 맵(Attention map)을 활용합니다.
- 전체 토큰 중 중요도가 높은 k1개의 우세 토큰(Dominant tokens)을 선택합니다.
- 나머지 잔여 토큰들은 지역적 클러스터 집합(Local cluster aggregation) 방식을 통해 k2개의 문맥 토큰(Contextual tokens)으로 병합합니다.
- 텍스트 주도 계층적 프루닝 (Text-guided hierarchical pruning):
- 언어 백본 내부에서 레이어별로 텍스트 토큰의 중요도(Salient text)를 기반으로 덜 중요한 시각 토큰을 점진적으로 삭제합니다.
핵심 기법
이 논문의 핵심은 토큰을 그냥 무작정 버리는 것이 아니라, 두 가지 유형으로 나누어 관리하는 것입니다. 첫째, ‘주인공’ 역할을 하는 핵심 정보는 우세 토큰으로 그대로 두고, 둘째, ‘배경’ 역할을 하는 정보는 군집화(Clustering)하여 몇 개의 대표 토큰으로 압축한 뒤, 언어 모델이 내용을 이해해가면서 필요 없는 배경 토큰을 과감하게 버리는 방식을 사용합니다.
📊 정량적 결과
주요 성과
- 추론(Inference) 단계: 토큰 수를 약 67% 줄인 상태(576개 → 192개)에서도 기존 최고 성능 모델인 VisionZip보다 더 높은 99.0%의 평균 정확도를 달성했습니다.
- 학습(Training) 단계: 학습 시간이 31% 단축되었음에도 불구하고, 정확도 저하는 1% 미만으로 유지되었습니다.
🚀 기존 대비 개선점
- VisionZip이나 PyramidDrop과 같은 단일 방식론보다 두 가지 방식을 결합하여 더 적극적인 토큰 압축이 가능해졌습니다.
- LLaVA-1.5-7B 기준, 추론 시 토큰을 78%(128개 토큰)까지 줄여도 경쟁력 있는 성능을 보여주었습니다.
- 플러그 앤 플레이(Plug-and-play) 방식으로, 모델 구조를 크게 뜯어고치지 않고도 적용할 수 있습니다.
🎯 활용 분야
- 모바일 기기나 엣지 디바이스에서 실행되는 실시간 비전-언어 모델 서비스
- 대용량 멀티모달 데이터를 다뤄야 하는 비디오 이해 및 생성 모델의 효율적 학습
- 비용 제약이 있는 클라우드 환경에서의 VLM 추론 최적화
한계 및 주의사항
- 이 방식은 시각 인코더(예: CLIP)의 self-attention map에 의존적이므로, 인코더 구조가 다른 모델에 적용할 때는 추가적인 수정이 필요할 수 있습니다.
- 텍스트가 이미지의 내용과 전혀 관련이 없는 경우, 텍스트 주도 프루닝(Text-guided pruning)이 오히려 중요한 시각 정보를 삭제할 위험이 있습니다.
📅 생성일: 2026-03-02 | 🤖 GLM-4.7