📚 2026-02-25 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 On Data Engineering for Scaling LLM Terminal … ⬆️58
- 📊📄 Query-focused and Memory-aware Reranker for L… ⬆️34
- 📊📕 PyVision-RL: Forging Open Agentic Vision Mode… ⬆️21
- 📊📄 From Perception to Action: An Interactive Ben… ⬆️20
- 📊📄 Test-Time Training with KV Binding Is Secretl… ⬆️18
- 🤖📕 See and Fix the Flaws: Enabling VLMs and Diff… ⬆️10
- 🤖📄 Learning from Trials and Errors: Reflective T… ⬆️4
- 🤖📄 Communication-Inspired Tokenization for Struc… ⬆️4
- 🤖📄 RankEvolve: Automating the Discovery of Retri… ⬆️3
- 🤖📄 One-step Language Modeling via Continuous Den… ⬆️3
1. On Data Engineering for Scaling LLM Terminal Capabilities
arXiv: 2602.21193 | 기관: NVIDIA | ⬆️ 58 📊 순위선정 | 📄 HTML 태그:
llmterminal-agentdata-engineeringsynthetic-datanvidia-nemotronqwensftdevops사전 지식: Large Language Models (LLM), Supervised Fine-Tuning (SFT), Synthetic Data (합성 데이터), Curriculum Learning (커리큘럼 러닝), Docker (도커)
한 줄 요약
최첨단 터미널 에이전트의 학습 데이터 전략을 처음으로 체계적으로 공개하고, 효율적인 합성 데이터 생성 파이프라인을 통해 작은 모델로도 큰 모델을 능가하는 성능을 끌어올린 데이터 엔지니어링 연구입니다.
💡 핵심 아이디어
마치 비행 조종사를 양성하기 위해 비행 시뮬레이터에서 날씨나 기계 고장 같은 다양한 시나리오를 만들어 훈련시키는 것과 같습니다. 기존의 문제들을 활용해 기본기를 다지고, 인위적으로 만든 과제를 통해 특정 기술을 연마하는 두 단계 접근 방식을 사용해 터미널 자동화 능력을 극대화했습니다.
문제 정의
최근 대규모 언어 모델이 터미널 환경에서 인간처럼 명령어를 입력하고 작업을 수행하는 능력이 중요해지고 있지만, 실제로 이런 에이전트를 훈련시키기 위한 고품질 데이터가 부족하고 생성 방법이 공개되어 있지 않습니다. 특히 실제 인간의 상호작용을 수집하기 어렵고, 매번 새로운 환경에서 에이전트가 시행착오를 겪으며 데이터를 만드는 것은 비용이 매우 비싸다는 문제가 있습니다.
🔬 방법론 상세
- Terminal-Task-Gen 파이프라인: 시드 기반(Seed-based)과 스킬 기반(Skill-based)으로 가벼우면서도 대규모의 합성 과제를 생성하는 시스템입니다.
- 이중 단계 데이터 생성 전략: 기존의 수학, 코드, 소프트웨어 엔지니어링 데이터셋을 변환하여 기초를 다지는 단계와 터미널 특화 과제를 합성하여 정교하게 훈련하는 단계로 나눕니다.
- 고급 훈련 기법 적용: 불필요한 데이터를 거르는 필터링, 쉬운 것부터 어려운 것 순으로 학습하는 커리큘럼 러닝(Curriculum Learning), 긴 맥락을 처리하는 능력을 키우는 롱 컨텍스트 훈련 등을 활용했습니다.
핵심 기법
가장 중요한 방법은 ‘거칠게부터 정교하게(Coarse-to-fine)‘의 데이터 생성 전략입니다. 처음에는 기존의 방대한 문제 풀이 데이터를 활용해 모델이 기본적인 추론 능력과 코드 작성 능력을 갖추도록 만듭니다. 그 후에는 터미널 환경에 특화된 명령어와 환경 설정을 포함한 합성 데이터를 주입하여, 모델이 실제 터미널에서 복잡한 작업 흐름을 처리할 수 있도록 정교하게 튜닝합니다.
📊 정량적 결과
주요 성과
- Terminal-Bench 2.0 벤치마크에서 Qwen3 베이스 모델 대비 유의미한 성능 향상을 달성했습니다.
- Nemotron-Terminal 14B 및 32B 모델은 자신보다 훨씬 큰 규모의 경쟁 모델들(GPT-5-Mini, Grok 4 등)과 대등하거나 이를 능가하는 성능을 보였습니다.
- 특히 GPT-5-Mini의 정확도가 24.0%인 것에 비해, Nemotron 모델군은 더 적은 파라미터 수에도 불구하고 이를 상회하는 경쟁력을 입증했습니다.
🚀 기존 대비 개선점
- 기존에는 비싼 비용이 드는 에이전트의 시행착오(Trial-and-error)에 의존하던 데이터 수집을, 저렴하고 효율적인 합성 데이터 생성 파이프라인으로 대체했습니다.
- 단순히 모델의 크기를 키우는 것보다, 데이터의 질과 다양성을 엔지니어링하는 것이 터미널 작업 성능에 더 큰 영향을 미친다는 사실을 입증했습니다.
- 터미널 작업에 필요한 의존성 파일이나 환경 설정 등을 포함한 포괄적인 데이터셋을 처음으로 대중에게 공개했습니다.
🎯 활용 분야
- 자동화된 개발 도구: 개발자가 복잡한 터미널 명령어를 직접 입력하지 않아도 되는 지능형 코딩 에이전트 개발.
- 시스템 운영 및 관리: 서버 설정, 배포, 디버깅 과정을 자동으로 수행하는 DevOps 오토메이션 도구.
- 교육용 시뮬레이터: 초보 개발자에게 리눅스 환경이나 터미널 명령어를 가르치는 상호작용형 튜토리얼 시스템.
한계 및 주의사항
- 현재 연구는 지도 학습(SFT)에 초점을 맞추고 있어, 실제 실행 결과로부터 피드백을 받아 스스로 수정하는 강화 학습(Reinforcement Learning) 단계는 아직 통합되지 않았습니다.
- 합성 데이터로 만든 환경은 실제 인간이 겪는 예기치 못한 복잡한 현실 세계의 문제들을 완벽하게 반영하지 못할 수 있습니다.
2. Query-focused and Memory-aware Reranker for Long Context Processing
arXiv: 2602.12192 | 기관: Tencent | ⬆️ 34 📊 순위선정 | 📄 HTML 태그:
llmrerankingattention-mechanismnlpragefficiencylong-contextretrieval사전 지식: RAG(Retrieval-Augmented Generation), Attention Mechanism, Transformer, Pointwise vs Listwise Ranking, Embedding Model

한 줄 요약
대규모 언어 모델(LLM) 내부의 특정 어텐션 헤드(Attention Head)를 활용해 텍스트 생성 과정 없이 후보 문서들의 순위를 매기는 효율적인 리랭킹 프레임워크를 제안하여, 기존 임베딩 방식의 한계를 넘고 생성형 리랭커의 비용 효율성을 극대화했습니다.
💡 핵심 아이디어
긴 글을 읽고 중요한 부분을 찾을 때, 책 전체를 다시 요약해서 쓰는 대신(기존 생성형 리랭커), 질문에 집중해서 형광펜으로 중요한 문장에 표시해 점수를 매기는 방식과 같습니다. 이 방식은 답변을 생성(Generation)하는 과정을 거치지 않고 모델이 읽는 과정(Prefill)만으로 점수를 내기 때문에 빠르고 정확합니다.
문제 정의
기존 검색 시스템은 임베딩(Embedding) 모델이 고정 차원 벡터로 정보를 압축하다 보니 문서 간의 복잡한 관계(인과관계, 유추 등)를 놓치는 ‘기하학적 병목(Geometric Bottleneck)‘이 있습니다. 또한, 이를 해결하기 위해 나온 대규모 언어 모델 기반의 리랭커는 답변을 생성해야 해서 느리고, 점수 방식(Pointwise)은 문서 목록 전체의 맥락을 보지 못하는 단점이 있었습니다.
🔬 방법론 상세
- QR-head (Query-focused Retrieval heads) 활용: 트랜스포머(Transformer) 모델의 다중 헤드 어텐션(Multi-head Attention) 중, 질문을 처리할 때 정답이 포함된 문맥에 높은 가중치를 두는 특정 헤드들을 식별하고 이를 선택합니다.
- 어텐션 점수 기반의 리스트와이즈(Listwise) 랭킹: 별도의 텍스트 생성 없이, 선별된 QR-head의 어텐션 점수(Attention Score)를 합산하여 문서의 관련성 점수로 삼습니다. 이를 통해 전체 후보 문서 목록(Shortlist)을 통합적으로 고려하여 순위를 매깁니다.
- 대조적 랭킹 목적함수(Contrastive Ranking Objective) 최적화: QR-head가 정답 문서(Gold Chunk)에는 높은 점수를, 그렇지 않은 문서에는 낮은 점수를 부여하도록 학습합니다. 이때 정답 데이터를 자동으로 구축하는 알고리즘을 사용합니다.
핵심 기법
이 논문의 가장 큰 특징은 ‘디코딩(Decoding) 없는 추론’입니다. 기존 LLM을 활용한 리랭커는 질문과 문서를 보고 “이 문서가 관련 있어요”라고 텍스트를 생성해야 해서 느렸지만, 이 방법은 입력을 다 읽었을 때 모델 내부에 남는 어텐션 지도(Attention Map)만 확인하면 됩니다. 즉, 모델이 생각할 때 어디를 집중적으로 봤는지 측정하여 순위를 매깁니다.
📊 정량적 결과
주요 성과
- 위키피디아 멀티홉 질의응답, 긴 문맥 스토리 질의응답, 대화 메모리 등 5개 데이터셋에서 기존 최첨단(SOTA) 모델들을 모두 능가하는 성능을 보였습니다.
- 약 40억(4B) 개의 작은 파라미터를 가진 모델만으로도 강력한 성능을 달성하여 효율성을 입증했습니다.
🚀 기존 대비 개선점
- 추론 속도 및 비용 절감: 텍스트 생성 과정이 없어 기존 리스트와이즈 생성형 리랭커보다 훨씬 빠르고 자원 효율적입니다.
- 연속적 관련성 점수 제공: 라이커트 척도(Likert-scale) 같은 이산적인 감독 없이도 연속적인 점수를 만들어내어 다양한 데이터셋에서 학습이 가능합니다.
- 전체적 맥락 파악: 포인트와이즈(Pointwise) 방식과 달리 전체 후보 문서를 한 번에 보는 리스트와이즈(Listwise) 방식의 장점을 유지합니다.
🎯 활용 분야
- RAG(Retrieval-Augmented Generation) 시스템: 검색된 문서의 순위를 다시 매겨 최종 답변의 정확도를 높이는 2단계 검색 단계에서 사용합니다.
- 긴 문서 처리: 소설, 시나리오, 대화 기록 등 매우 긴 텍스트에서 특정 정보를 찾아내는 질의응답 시스템에 적합합니다.
- 효율적인 AI 에이전트: 메모리를 많이 사용해야 하는 에이전트의 정보 검색 과정을 가볍게 최적화하는 데 쓸 수 있습니다.
한계 및 주의사항
- QR-head의 안정성: 원래 사전 학습된 QR-head를 새로운 작업에 그대로 적용하면 성능이 불안정할 수 있어, 새로운 작업에 맞춰 별도의 미세 조정(Fine-tuning) 파이프라인이 필요합니다.
- 헤드 선택의 의존성: 모델의 어떤 헤드를 QR-head로 선정하느냐에 따라 성능 차이가 발생할 수 있습니다.
3. PyVision-RL: Forging Open Agentic Vision Models via RL
arXiv: 2602.20739 | ⬆️ 21 | ⭐ 43 📊 순위선정 | 📕 PDF 태그:
vision-language-modelreinforcement-learningagentic-aifine-tuningtool-useinteraction-collapsemultimodal-learning사전 지식: Reinforcement Learning (강화 학습), Multimodal Models (멀티모달 모델), Agentic AI (에이전트형 AI), Interaction Collapse (상호작용 붕괴), Trajectory (궤적)
한 줄 요약
이 논문은 강화 학습(Reinforcement Learning)을 통해 시각-언어 모델을 에이전트로 훈련할 때 발생하는 ‘상호작용 붕괴’ 문제를 해결하여, 도구 사용과 멀티 턴 추론을 지속적으로 수행할 수 있는 개방형 가중치 모델을 만든 체계를 제시했기에 중요합니다.
💡 핵심 아이디어
이 논문의 핵심은 마치 요리사가 레시피를 외우는 것만이 아니라, 실제 조리 과정에서 시행착오를 통해 요리법을 발전시키는 것과 같습니다. 기존 모델은 결과 요리(정답)만 빨리 내놓으려다 조리 과정(도구 사용, 추론)을 생략하는 ‘요압(요리 생략)’ 현상이 발생했는데, PyVision-RL은 좋은 조리 과정을 골라서(Mining), 걸러내고(Filtering), 순위를 매겨(Ranking) 모델이 꼼꼼하게 요리하도록 훈련시킵니다.
문제 정의
이 논문이 해결하려는 핵심 문제는 강화 학습을 이용해 에이전트 형(Agentic)의 멀티모달 모델을 훈련시킬 때 발생하는 상호작용 붕괴(Interaction Collapse) 현상입니다. 이는 모델이 보상을 최대화하기 위해 도구 사용이나 여러 단계의 추론 과정을 생략하고, 단순한 답변을 생성하거나 상호작용을 조기에 종료하는 방식으로 학습되는 문제입니다. 결과적으로 모델의 복잡한 문제 해결 능력이 저하됩니다.
🔬 방법론 상세
- 과대 샘플링-필터링-랭킹(Over-sampling–filtering–ranking) 파이프라인: 기존의 단순한 데이터 수집 방식 대신, 먼저 다양한 행동 궤적(Trajectory)을 과대 샘플링(Over-sampling)하여 생성합니다. 그 후 질이 낮거나 탐험적이지 못한 궤적을 필터링(Filtering)하고, 남은 후보들 중에서 유용성을 기준으로 순위를 매겨(Ranking) 최적의 학습 데이터셋을 구축합니다.
- 강화 학습을 통한 파인튜닝(RL Fine-tuning): 구축된 데이터셋을 사용하여 시각-언어 모델을 강화 학습으로 업데이트합니다. 이때 단순히 정답을 맞히는 것뿐만 아니라, 도구를 올바르게 사용하고 지속적으로 상호작용을 이어가는 행동에 보상(Reward)을 부여하여 상호작용 붕괴를 방지합니다.
핵심 기법
가장 중요한 기법은 데이터의 질을 보장하는 필터링 및 랭킹(Filtering & Ranking) 전략입니다. 마치 금광에서 흙을 캐낸 후(Over-sampling), 그중에서 가치 없는 돌을 걸러내고(Filtering), 금의 순도에 따라 등급을 매기는(Ranking) 과정과 비슷합니다. 이를 통해 모델이 “게으른” 행동(상호작용 생략)을 보상받지 못하게 막고, 좀 더 적극적이고 복잡한 문제 해결 과정을 학습하도록 유도합니다.
📊 정량적 결과
논문의 본문 전문이 제공되지 않았으므로 요약문(Abstract)에 기반하여 성과를 설명합니다. 요약문에 따르면, 해당 방법론은 에이전트 모델의 훈련을 안정화시키고 상호작용을 지속 가능하게 만드는 데 성공했습니다.
주요 성과
- 다양한 멀티모달 에이전트 벤치마크에서 기존 강화 학습 방법 대비 상호작용 붕괴 현상을 효과적으로 억제
- 도구 사용(Tool Use)이 필요한 복잡한 시각적 추론 작업에서 정확도와 성공율의 유의미한 향상(구체적인 수치는 논문 본문 참조 필요)
- 개방형 가중치(Open-weight) 모델을 통해 고품질의 시각적 에이전트 모델을 대중에게 공개
🚀 기존 대비 개선점
- 기존 강화 학습 기반 에이전트 훈련 시 발생하던 ‘단축키 찾기’ 행동(Sparse Reward导致的投机行为)을 방지
- 단순한 언어 모델 능력을 넘어 시각적 도구를 능숙하게 다루는 에이전트 역량 강화
- 훈련 과정의 불안정성을 해소하여 긴 문맥(Long-horizon)의 작업 수행 능력 개선
🎯 활용 분야
- 복잡한 시각적 정보가 필요한 자율 AI 에이전트 개발 (예: 웹 브라우징 도우미)
- 로봇 비전(Robot Vision) 및 물리적 세계와 상호작용하는 엣지 디바이스 제어
- 전문가 시스템(예: 의료 이미지 분석 도구 활용, 엔지니어링 CAD 도구 제어)
한계 및 주의사항
- 제공된 요약문에서 구체적인 한계점은 언급되지 않았으나, 일반적으로 강화 학습 기반 방법론은 훈련에 드는 계산 비용이 매우 높을 수 있습니다.
- 오버샘플링 및 필터링 과정 자체에 추가적인 리소스가 소모되므로, 효율성과 성능 간의 트레이드오프(Trade-off)가 고려되어야 합니다.
4. From Perception to Action: An Interactive Benchmark for Vision Reasoning
arXiv: 2602.21015 | ⬆️ 20 | ⭐ 2 📊 순위선정 | 📄 HTML 태그:
benchmarkembodied-aivision-language-modelsphysical-reasoningcausal-reasoninginteractive-evaluation3d-simulation사전 지식: Vision-Language Model (VLM), Embodied AI (임베디드 AI), Visual Question Answering (VQA), Physical Reasoning (물리 추론), Closed-loop Interaction (폐루프 상호작용)
한 줄 요약
기존의 정적인 이미지 분석을 넘어, AI가 물리 법칙과 구조적 제약을 이해하고 복잡한 환경과 상호작용하며 문제를 해결하는 능력을 평가할 수 있는 최초의 인터랙티브 3D 벤치마크(CHAIN)를 제시하여 실제 세계의 로봇이나 에이전트가 갖춰야 할 진정한 지능을 평가하는 새로운 기준을 마련했습니다.
💡 핵심 아이디어
자동차 운전 면허 시험에서 필기 시험을 잘 보는 것과 실제 도로 운전을 잘하는 것은 완전히 다른 문제입니다. 이 논문은 기존 AI가 단순히 이미지를 보고 답만 하는 필기 시험 수준(정적 인지)에 머물러 있음을 지적하며, AI가 직접 블록을 쌓거나 퍼즐을 맞추는 듯한 실전 시험 환경(인터랙티브 물리 추론)을 만들어 실제 행동 능력을 테스트합니다.
문제 정의
(이 논문이 해결하려는 핵심 문제) 현재 비전-언어 모델(VLM)의 평가는 주로 Visual Question Answering(VQA, 이미지를 보고 질문에 답하는 방식)과 같이 정적이고 단발적인 설정에 집중되어 있습니다. 하지만 실제 현실 세계의 임베디드 에이전트(Embodied Agent, 로봇처럼 환경에 직접 개입하는 지능체)는 물체의 기하학적 구조, 접촉 관계, 지지 관계 등 물리적 제약을 고려해 여러 단계에 걸쳐 행동을 계획하고 실행해야 하는데, 기존 평가 방식으로는 이러한 ‘물리적 상호작용 능력’을 제대로 측정할 수 없습니다.
🔬 방법론 상세
- CHAIN 벤치마크 도입: Causal Hierarchy of Actions and Interactions(인과 계층적 행동 및 상호작용)라는 인터랙티브 3D 물리 기반 테스트베드를 개발했습니다. 이 벤치마크는 인터로킹 퍼즐(맞물림 퍼즐), 3D 적재 및 포장 등 물리적 구조 이해가 필수적인 과제를 포함합니다.
- 통형된 상호작용 프로토콜: GPT-5.2, OpenAI-o3, Claude-Opus-4.5, Qwen3-VL 등 최신 모델들을 공정한 비교를 위해 동일한 디코딩 및 상호작용 프로토콜 하에서 평가했습니다.
- 시스템 프록시(Proxy)를 통한 행동 실행: 모델이 저급 제어(Low-level Control)에 얽매이지 않고 ‘연산 수준의 의사결정’에만 집중하도록, 모델은 행동 API를 통해 명령을 내리면 시스템 프록시가 실제 원자적 행동(Atomic Actions)을 실행하도록 설계했습니다.
- 단계별 상호작용 예산 설정: 각 과제 인스턴스당 30~60단계의 상호작용 단계(Interaction Budget)를 캡하여 제한된 횟수 안에 문제를 해결하는지를 테스트했습니다.
핵심 기법
이 논문의 핵심은 평가를 ‘수동적 지각(Passive Perception)‘에서 ‘능동적 폐루프(Active Closed-loop)’ 시스템으로 전환한 것입니다. 마치 사람이 무언가 조작할 때 손으로 만져보고 그 결과를 보며 다음 행동을 수정하듯이, AI 모델도 환경과 계속 상호작용하며 결과를 관찰하고 계획을 수정해 나가는 과정을 필수적으로 요구함으로써, 단순히 시각적으로 ‘알고 있는 것’과 물리적으로 ‘할 수 있는 것’의 차이를 명확히 가립니다.
📊 정량적 결과
주요 성과
- 구조적 제약에 따른 성능 급락: 물리적 구조적 제약이 tightening(강화)됨에 따라 모든 최신 모델의 성능이 급격히 저하되는 패턴을 발견했습니다. 즉, 단순한 조작은 가능하지만 복잡한 구조적 물리 법칙이 개입되면 성공률이 떨어집니다.
- 인터로킹 퍼즐에서의 실패: 숨겨진 기하학적 제약이 존재하는 인터로킹 기계식 퍼즐 과제에서는 가장 두드러진 실패가 나타났습니다. 모델이 장면을 올바르하게 인지하더라도 일관된 다단계 전략을 유지하지 못하고 실패했습니다.
- 평가 모델: 총 15개 이상의 최신 모델(GPT-5.2, OpenAI-o3, Qwen3-VL 시리즈 등)을 대상으로 테스트하여, 현재 SOTA 모델조차 인터랙티브 물리 추론에서 큰 어려움을 겪고 있음을 입증했습니다.
🚀 기존 대비 개선점
- 정적 VQA 평가의 한계 극복: 기존 벤치마크가 놓치고 있었던 다단계 물리적 과정에 대한 인과적 추론 능력을 측정합니다.
- 로우레벨 제어 분리: 시스템 프록시를 통해 하드웨어 제어 문제를 배제함으로써, 순수하게 모델의 ‘상위 수준 추론 및 계획’ 능력만을 집중적으로 분석할 수 있습니다.
- 물리적 피드백 반영: 단순한 시각적 이해를 넘어, 시행착오(Trial and error)를 통해 물리 법칙을 학습하고 적용하는 능력을 평가합니다.
🎯 활용 분야
- 가정용 및 산업용 로봇 개발: 로봇이 주방 정리나 공장 조립 라인에서 물체를 조작할 때 물리적 충돌이나 무게 중심을 고려하여 작업을 수행하도록 훈련시키는 데 활용됩니다.
- 인터랙티브 설계 시스템: 사용자가 3D 공간에서 물체를 배치하거나 조립할 때, AI가 그 구조가 물리적으로 가능한지 실시간으로 피드백을 주고 최적의 배치를 제안하는 도구 개발에 쓰입니다.
- 장거리 조작(Long-horizon Manipulation) 연구: 당장의 행동뿐만 아니라 앞으로 여러 단계를 내다봐야 하는 복잡한 작업을 수행하는 AI 에이전트 연구의 기준 점(Ground truth)으로 사용됩니다.
한계 및 주의사항
- 숨겨진 기하학적 제약(Hidden Geometric Constraints): 저자들은 특히 인터로킹 퍼즐과 같이 물체 내부나 뒤에 숨겨진 구조적 제약을 이해해야 하는 과제에서 모델들이 가장 큰 어려움을 겪는다고 언급했습니다. 이는 시각적 정보만으로는 파악하기 힘든 물리적 특성을 추론하는 능력이 아직 부족함을 시사합니다.
5. Test-Time Training with KV Binding Is Secretly Linear Attention
arXiv: 2602.21204 | 기관: NVIDIA | ⬆️ 18 📊 순위선정 | 📄 HTML 태그:
llmtransformerlinear-attentiontttefficiencysequence-modelingoptimization사전 지식: Transformer, Attention Mechanism, Gradient Descent, Linear Attention, Meta-Learning

한 줄 요약
기존에 복잡한 메타러닝(Meta-learning)이나 암기(Memorization) 메커니즘으로 해석되었던 테스트 타임 트레이닝(TTT)을 수학적으로 분석하여, 사실 이것이 선형 어텐션(Linear Attention)의 일종임을 밝혀낸 혁신적인 연구입니다.
💡 핵심 아이디어
이 논문은 마치 시험을 보기 전에 교과서 내용을 달달 외우는 것(암기)으로 여겨졌던 TTT 기법이, 실제로는 외우지 않고 단순히 공식을 빠르게 대입하여 답을 찾아내는 과정(선형 어텐션)과 같다는 사실을 밝혀냈습니다. 즉, 굳이 복잡한 내부 루프(Inner loop)를 돌며 가중치를 갱신할 필요 없이, 이를 수학적으로 정리하면 훨씬 효율적인 선형 어텐션 연산으로 바꿀 수 있다는 점을 증명했습니다.
문제 정의
기존 TTT, 특히 키-값 바인딩(KV Binding)을 사용하는 방식은 테스트 시간에 모델 파라미터를 실시간으로 업데이트하는 복잡한 과정으로 이해되었습니다. 이로 인해 모델 구조가 복잡해지고, 계산 비용이 높으며, 왜 내부 학습(Inner loop)을 더 많이 해도 성능이 오히려 떨어지는지 등의 모순적인 현상을 설명하기 어려웠습니다.
🔬 방법론 상세
- 테스트 타임 트레이닝의 핵심 수식인 손실 함수 $L = |f_\theta(k)-v|^2$에 대한 경사 하강법(Gradient Descent) 업데이트 과정을 수학적으로 전개(Expansion)합니다.
- 내부 루프(Inner loop)에서 가중치 $\theta$를 한 단계 업데이트하는 과정이, 결국 쿼리(Query), 키(Key), 값(Value) 사이의 선형 관계를 학습하는 선형 어텐션(Linear Attention) 형태로 변환됨을 증명합니다.
- 이를 통해 다층 퍼셉트론(MLP)이나 모멘텀(Momentum) 최적화를 쓰는 복잡한 TTT 구조도 하나의 학습된 선형 어텐션 연산자로 단순화할 수 있음을 보입니다.
핵심 기법
가장 중요한 발견은 TTT의 “내부 루프(Inner loop)“가 단순한 학습이 아니라, 구조화된 선형 어텐션 층을 정의하는 또 다른 방식이라는 점입니다. 저자는 이를 “해석 가능성 재해석(Reinterpretation)“이라 부르며, TTT의 내부 파라미터 업데이트 규칙을 분리하여 보면, 결국 $Y = \text{Softmax}(QK^T)V$ 같은 기존 어텐션 메커니즘의 선형 버전과 수학적으로 동일함을 입증했습니다.
📊 정량적 결과
주요 성과
- 내부 루프의 경사 하강 스텝(Gradient steps)을 증가시켜 손실(Loss)은 줄였지만, 실제 다운스트림(Downstream) 성능은 지속적으로 저하되는 역설적 현상을 발견했습니다. (예: 스텝 수 증가 시 성능 저하)
- 복잡한 TTT 구조를 단순화된 선형 어텐션으로 치환했을 때도 기존 모델과 동등한 수준의 성능을 유지하면서도 연산 효율성은 개선되었습니다.
🚀 기존 대비 개선점
- 복잡한 내부 최적화(Inner loop optimization) 과정을 제거하고, 완전히 병렬화(Parallelization) 가능한 선형 어텐션 형태로 구현할 수 있어 추론 속도가 빨라집니다.
- 모멘텀(Momentum)이나 복잡한 정규화(Normalization) 같은 정교한 하이퍼파라미터 튜닝 없이도 더 단순한 아키텍처로 동일한 성능을 낼 수 있습니다.
- 다양한 TTT 변형들을 표준적인 선형 어텐션 프레임워크로 체계적으로 축소(Reduction)하여 이해하고 구현하기 쉬워졌습니다.
🎯 활용 분야
- 초장문 맥락(Long Context)을 처리해야 하는 대규모 언어 모델(LLM)의 효율화
- 실시간으로 데이터가 들어오는 온라인 학습(Online learning) 환경
- 새로운 시점 합성(NVS, Novel View Synthesis)과 같은 시퀀스 모델링이 필요한 비전 태스크
한계 및 주의사항
- 이 분석은 주로 TTT-KVB(Key-Value Binding) 방식에 초점을 맞추고 있어, 다른 유형의 TTT 방식에는 동일하게 적용되지 않을 수 있습니다.
- 선형 어텐션으로 단순화된 모델이 기존 TTT의 모든 비선형적인 동작 방식을 완벽히 커버하는지에 대해서는 추가적인 검증이 필요할 수 있습니다.
6. See and Fix the Flaws: Enabling VLMs and Diffusion Models to Comprehend Visual Artifacts via Agentic Data Synthesis
arXiv: 2602.20951 | ⬆️ 10 | ⭐ 1 🤖 GLM추천 | 📕 PDF 태그:
artifact-detectionvlmdiffusion-modelsdata-synthesisai-safetygenerative-aicomputer-vision사전 지식: Diffusion Models, Vision-Language Models (VLM), Data Augmentation, Computer Vision, Grounding (이미지 내 객체 위치 추론)
한 줄 요약
확산 모델이 생성한 이미지의 시각적 결함을 인간의 개입 없이 자동으로 감지하고 학습 데이터를 생성하여 시각-언어 모델의 이해력을 높이는 ‘ArtiAgent’ 프레임워크를 제안한 연구입니다.
💡 핵심 아이디어
자율주행 자동차 학습용 시뮬레이터를 떠올려 보세요. 실제 도로에서 사고를 일으키는 대신, 가상의 공간에 다양한 장애물을 인위적으로 배치하여 자동차가 위험 상황을 미리 인지하도록 훈련시킵니다. 이 논문도 비슷합니다. 실제로 존재하는 깨끗한 이미지에 AI 에이전트가 직접 손가락이 6개인 사람처럼 ‘인위적인 결함(Artifact)‘을 주입한 가상 이미지를 만들어냅니다. 이렇게 만들어진 ‘결함 쌍’ 데이터를 통해 시각-언어 모델이 AI가 만든 이미지의 어색한 부분을 스스로 찾아낼 수 있도록 훈련시키는 것이 핵심입니다.
문제 정의
최신 확산 모델(Diffusion Models)로 생성된 이미지는 매우 사실적이지만, 여전히 융합된 손가락(Fused entities)이나 기형적인 형태 같은 시각적 결함(Visual artifacts)이 포함되곤 합니다. 이를 해결하기 위해 사람이 직접 결함을 라벨링하는 것은 비용이 많이 들고 확장이 어렵습니다. 또한, 최신 시각-언어 모델(VLM)조차도 이러한 AI 생성물의 결함을 제대로 감지하거나 설명하지 못하는 문제가 있습니다.
🔬 방법론 상세
- Agentic Data Synthesis (에이전트 기반 데이터 합성): 데이터를 만들기 위해 세 가지 전문 에이전트(Agent)를 협력시키는 시스템을 구축했습니다.
- Perception Agent (지각 에이전트): 실제 이미지를 분석하여 객체(Entity)와 하위 객체(Subentity)를 인식하고 위치(Grounding)를 파악합니다. 예를 들어 사람 그림에서 ‘손’과 ‘손가락’의 위치를 정확히 찾아냅니다.
- Synthesis Agent (합성 에이전트): 지각 에이전트가 찾은 정보를 바탕으로 실제 이미지에 결함을 주입합니다. (예: 손가락 5개인 이미지를 6개로 수정)
- (추론되는 제3 에이전트): 텍스트가 중간에 끊겨 명시되지 않았으나, 일반적인 구조상 생성된 이미지의 품질을 검증하거나 VLM 학습을 위한 질문-답변 쌍을 생성하는 역할을 수행할 것으로 추정됩니다.
핵심 기법
이 논문의 가장 중요한 기술은 사람의 개입 없이 완벽한 이미지와 결함이 있는 이미지의 ‘쌍(Pair)‘을 자동으로 대량 생산하는 파이프라인입니다. 마치 선생님이 시험지에 ‘오답’과 ‘정답’을 함께 만들어주면 학생이 훨씬 빨리 공부하듯, VLM 모델도 ‘이것은 6개 손가락이라 비정상이다’라는 것을 명확히 알 수 있는 학습자료를 확보하게 됩니다.
📊 정량적 결과
주요 성과
- 제공된 논문 본문에 구체적인 수치 결과 섹션(Results)이 포함되어 있지 않아 정확한 개선 수치(%)를 확인할 수 없습니다.
- 다만, 논문은 제안된 방법이 기존의 인간 라벨링 방식 대비 비용 효율적이며, VLM의 결함 탐지 및 설명 능력을 유의미하게 향상시킨다고 주장합니다.
🚀 기존 대비 개선점
- 데이터 구축 비용 절감: 인간이 수동으로 결함을 라벨링할 필요 없이 AI가 자동으로 고품질의 학습 데이터를 생성합니다.
- VLM의 이해도 향상: 시각-언어 모델이 단순히 이미지를 묘사하는 것을 넘어, AI가 만들어낸 기형적인 부분을 구체적으로 지적하고 수정 방안을 제시할 수 있도록 돕습니다.
- 확장성(Scalability): 다양한 종류의 이미지와 결함 패턴에 대해 자동으로 대규모 데이터셋을 확장할 수 있습니다.
🎯 활용 분야
- 의료 이미지 분석: AI가 생성하거나 판독한 의료 영상의 기형적인 왜곡을 자동으로 걸러내어 진단의 신뢰성을 높입니다.
- 자율 주행 및 로봇 공학: 시뮬레이션 환경이나 실제 센서 데이터의 이상치(Artifact)를 감지하여 로봇이 잘못된 판단을 내리지 않도록 방지합니다.
- 고품질 이미지 생성 서비스: 사용자에게 최종 이미지를 제공하기 전, 결함을 자동으로 탐지하여 재생성하거나 보정하는 품질 관리 단계에 활용됩니다.
한계 및 주의사항
- 제공된 텍스트에 저자가 명시한 한계점이 포함되어 있지 않습니다.
- 다만, 합성 에이전트가 만들어내는 결함의 종류가 다양하지 못하거나, 실제 현상의 결함과 미묘하게 다를 경우 학습된 모델이 실전에서 오작동할 가능성이 있으므로 데이터의 다양성 확보가 중요할 것으로 보입니다.
7. Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs
arXiv: 2602.21198 | ⬆️ 4 🤖 GLM추천 | 📄 HTML 태그:
embodied-aireflective-planningtest-time-trainingllmroboticsreinforcement-learningself-improvement사전 지식: Embodied AI(몰입형 인공지능), Test-time Training(테스트 타임 훈련), Test-time Scaling(테스트 타임 스케일링), Large Language Models(대규모 언어 모델), Fine-tuning(파인 튜닝)

한 줄 요약
이 논문은 로봇이 배포 중에 스스로의 실수를 되돌아보고 즉시 모델을 수정하여 경험을 축적하는 ‘반성적 테스트 타임 계획(Reflective Test-Time Planning)’ 프레임워크를 도입하여, 기존 몰입형 대규모 언어 모델(Embodied LLM)의 정적인 한계를 동적 학습 능력으로 극복했기에 매우 중요합니다.
💡 핵심 아이디어
이 논문의 핵심 아이디어는 숙련된 요리사가 요리하는 과정과 비슷합니다. 요리사는 요리를 하기 전에 레시피를 머릿속으로 시뮬레이션하여 맛을 예상하고, 조리 중에 간을 보며 실시간으로 조절하며, 요리가 끝난 후에는 결과를 기록하여 다음 요리에 반영합니다. 이처럼 로봇이 행동 전에 내부적으로 시뮬레이션하고, 행동 후에 외부 피드백을 통해 스스로를 업데이트하는 이중 반성 과정을 통해 실수를 단순한 실패가 아닌 학습의 기회로 바꾸는 것입니다.
문제 정의
기존의 몰입형 대규모 언어 모델(Embodied LLM)은 복잡한 작업 추론 능력은 갖추었지만, 한번 실패한 이유를 분석하거나 그 실패로부터 배우지 못합니다. 이 때문에 배포 시점(Deployment time)에는 실수가 반복될 뿐 누적된 경험으로 이어지지 않으며, 모델의 가중치가 고정되어 있어 새로운 환경이나 오류 상황에 유연하게 대처하지 못하는 문제가 있습니다.
🔬 방법론 상세
- 행동 중 반성(Reflection-in-action): 실행 직전에 테스트 타임 스케일링(Test-time scaling) 기법을 사용하여 여러 후보 행동을 생성하고, 내부 반성 모델(Internal Reflection LLM)을 통해 이들을 점수화하여 가장 최적의 행동 하나를 선택합니다.
- 행동 후 반성(Reflection-on-action): 실행 결과(성공 여부 등)를 바탕으로 외부 반성 모델(External Reflection LLM)이 평가를 생성하고, 테스트 타임 훈련(Test-time training)을 통해 행동 정책(Action Policy)과 내부 반성 모델의 파라미터를 실시간으로 업데이트합니다.
- 삼중 모델 구조: 행동 생성 모델($\pi_\theta$), 내부 반성 모델($V_{\phi_i}$), 외부 반성 모델($V_{\phi_e}$)의 상호작용을 통해 초기에는 최소한의 지도 학습으로 기본 능력을 부여하고, 배포 시점에는 경험을 통해 적응합니다.
핵심 기법
이 논문의 가장 중요한 기법은 테스트 타임 훈련(Test-time training)의 도입입니다. 일반적으로 모델 학습은 사전에 끝나지만, 이 방식은 실제 로봇이 작업을 수행하는 배포 과정 자체를 훈련 시간으로 활용합니다. 즉, 로봇이 실제 세계에서 물건을 집어 올리거나 배치하는 과정에서 얻은 피드백(성공/실패)을 즉시 모델의 가중치에 반영하여, 같은 실수를 하지 않도록 온라인 상태에서 모델을 뜯어고치는 것입니다.
📊 정량적 결과
주요 성과
- 평균 성공률: 제안하는 방법(Reflective Test-Time Planning)은 롱 호라이즌 가정 tasks에서 평균 성공률 33.65%를 기록하여, 기존 방식인 Reflexion(11.20%)이나 PPO(11.13%) 대비 약 3배 이상의 성능 향상을 보여주었습니다.
- Fitting 작업 성과: 물체를 용기에 넣는 Fitting 작업에서는 기존 베이스라인들(약 8~10%) 대비 44.7%라는 압도적인 성공률을 기록하며, 기하학적 이해와 실패 복구 능력이 크게 개선되었음을 입증했습니다.
🚀 기존 대비 개선점
- 기존 정적 추론 방식이 실패를 반복하는 것과 달리, 시행착오를 통해 실시간으로 모델을 업데이트하여 실패가 줄어들고 성공률이 시간이 지날수록 증가합니다.
- 행동 전 내부 시뮬레이션을 통해 전략적으로 잘못된 행동을 미리 걸러내어 효율성을 높입니다.
- 텍스트 피드백만 저장하는 방식과 달리 모델 파라미터 자체를 수정하여 환경에 대한 더 깊은 신념(Belief)과 전략을 형성합니다.
🎯 활용 분야
- 실내 가사 도우미 로봇: 물건 정리, 청소, 요리 보조 등 복잡하고 오류 발생이 잦은 가정 환경에서의 자율 수행.
- 물류 및 창고 자동화: 다양한 물체를 파악하고 포장하는 과정에서 발생하는 물체 떨어뜨림 등의 오류를 자가 복구하는 시스템.
- 탐사 및 재난 구조 로봇: 미지의 환경에서 상황을 판단하며 이동하고 작업을 수행해야 하는 군사나 구조 분야의 자율 주행 로봇.
한계 및 주의사항
- 현재 연구는 시각과 언어 정보에 주로 의존하고 있어, 물체의 질감이나 무게 중심을 파악하는 데 필수적인 촉각(Tactile) 정보와 같은 더 풍부한 감각 모달리티가 통합되지 못한 한계가 있습니다.
8. Communication-Inspired Tokenization for Structured Image Representations
arXiv: 2602.20731 | 기관: Computer Vision Group @ University of Bern | ⬆️ 4 | ⭐ 3 🤖 GLM추천 | 📄 HTML 태그:
image-tokenizationmultimodal-learningdeep-learningtransformersemantic-representationcomputer-vision사전 지식: 을 잠재 메시지에 주입합니다.

한 줄 요약
이 논문은 인간의 의사소통 방식을 모방하여 이미지를 순차적으로 관찰하고 해석하는 과정을 통해, 단순한 질감 복원을 넘어 객체 수준의 의미적 구조를 포착하는 구조화된 이미지 토큰화 프레임워크를 제안했기 때문에 중요합니다.
💡 핵심 아이디어
친구에게 전화로 그림을 묘사하는 상황을 상상해 보세요. 화가는 그림 전체를 한 번에 설명하는 대신, “왼쪽 아래에 고양이가 있고, 그 옆에 나무가 있어”와 같이 시선을 이동하며 정보를 조금씩 추가하여 설명합니다. COMiT는 이처럼 이미지의 여러 지역을 순차적으로 스캔하면서, 새로운 정보를 기존의 설명(잠재 메시지)에 통합하고 업데이트하여, 최종적으로 의미가 잘 정돈된 토큰 시퀀스를 만들어냅니다.
문제 정의
기존의 이미지 토큰나이저는 주로 이미지를 잘 압축하고 복원하는 데에 초점을 맞추어서, 토큰들이 지역적인 질감(Texture) 정보만 담고 있을 뿐, 객체나 관계 같은 고차원적인 의미를 제대로 담지 못한다는 문제가 있습니다. 이로 인해 트랜스포머(Transformer) 기반의 모델들이 이미지를 이해하고 추론하는 데 어려움을 겪었습니다.
🔬 방법론 상세
- 순차적 관찰 및 오프셋 계산: 입력 이미지에서 무작위로 잘라낸 영역(Crop) $c_k$와 그 위치 $l_k$를 추출하고, 이전 위치와의 차이인 오프셋(Offset) $a_k = l_k - l_{k-1}$을 계산하여 시선의 이동을 모방합니다.
- 순환적 잠재 메시지 업데이트: 추출된 순차적 정보를 바탕으로 고정된 예산(Token Budget) 내에서 잠재 메시지(Latent Message)를 반복적으로 업데이트하여 정보를 통합합니다.
- 이산화(Discretization) 및 학습: FSQ(Finite Scalar Quantization)를 사용하여 메시지를 이산적인 값으로 변환하고, 플로우 매칭(Flow Matching) 목적 함수를 통해 재구성 성능을 높입니다.
- 효율성 및 의미 강화: REPA(Rectified Patch Alignment) 기법으로 학습 속도를 높이고, SREPA(Semantic REPA)를 통해 의미적 사전 지식을 잠재 메시지에 주입합니다.
핵심 기법
이 논문의 핵심은 이미지를 한 번에 처리하는 것이 아니라, 에이전트(Agent)가 장면을 스캔하듯 순차적으로 ‘관찰(Observe)‘하고 메시지를 ‘갱신(Update)‘하는 과정을 반복한다는 점입니다. 이를 통해 토큰들이 단순한 화소 값 모음이 아니라, 시간의 흐름에 따라 구성된 의미 있는 문장처럼 형성되도록 유도합니다.
📊 정량적 결과
주요 성과
- Visual Recognition (ImageNet100): 단순 선형 탐색 대신 어텐션(Attention) 기반 탐색을 사용했을 때, 기존 방법 대비 우수한 분류 성능을 달성하며 토큰 간의 의미적 연결성이 잘 형성되었음을 입증했습니다.
- Compositional Generalization (MSCOCO): 학습 데이터에 없던 객체 조합(Object Compositions)에 대해 일반화하여 추론하는 능력을 평가한 결과, 기존의 1D 이산 인코더보다 일관되게 더 높은 성능을 보였습니다.
🚀 기존 대비 개선점
- 기존의 2D 그리드 기반 토큰화 방식이 야기했던 의미적 꼬임(Semantic Entanglement) 문제를 해결하여, 토큰의 의미를 명확히 국지화했습니다.
- 압축률보다는 의미적 구조에 초점을 맞춘 새로운 훈련 목표 함수와 파이프라인을 설계했습니다.
- 인간의 인지 과정(점진적이고 구성적인 의사소통)을 수학적 모델에 성공적으로 통합했습니다.
🎯 활용 분야
- 멀티모달 대형 언어 모델(MLLM): 텍스트와 이미지를 통합하여 이해하는 모델에서, 이미지를 더 정확한 의미 단위로 모델에 전달할 수 있습니다.
- 로봇 비전(Robot Vision): 로봇이 카메라로 장면을 스캔하며 객체를 인식하고 상황을 이해하는 과정에 활용할 수 있습니다.
- 장면 이해 및 추론: 이미지 내 객체들의 위치 관계나 상호작용을 파악해야 하는 복잡한 시각적 추론 작업에 유용합니다.
한계 및 주의사항
- 제공된 논문 초록에는 명시적인 한계점이 언급되어 있지 않으나, 이미지를 순차적으로 처리해야 하므로 병렬 처리가 어려워 추론 속도가 기존 방식보다 느릴 수 있다는 점은 고려해야 합니다.
- 랜덤 크롭(Random Crop) 방식에 의존하므로, 특정 중요한 객체가 놓치지 않도록 충분한 수의 관찰 단계가 필요할 수 있습니다.
Variational Autoencoder (VAE), Quantization (양자화), Transformer, Attention Mechanism, Flow Matching
9. RankEvolve: Automating the Discovery of Retrieval Algorithms via LLM-Driven Evolution
arXiv: 2602.16932 | 기관: Santa Clara University IR Group | ⬆️ 3 | ⭐ 4 🤖 GLM추천 | 📄 HTML 태그:
retrieval-algorithmsllm-evolutionprogram-synthesisinformation-retrievalbm25evolutionary-searchautomated-discoveryrank-evolve사전 지식: Lexical Retrieval (어휘 기반 검색), BM25 Algorithm, Program Synthesis (프로그램 합성), Evolutionary Computation (진화적 계산), LLM Agents

한 줄 요약
RankEvolve는 대규모 언어 모델(LLM)과 진화적 탐색(Evolutionary Search)을 통해 기존 BM25나 QL 등의 검색 알고리즘을 자동으로 진화시켜, 인간의 직관을 넘어서는 더 효과적인 새로운 순위 매기기 알고리즘을 발견해 낸 혁신적인 연구입니다.
💡 핵심 아이디어
이 논문은 마치 전설적인 경주마를 만들기 위해 우수한 혈통의 말들을 교배시키는 브리더(육종가)의 접근 방식을 AI 연구에 도입했습니다. BM25와 QL이라는 기존의 검색 알고리즘을 부모 세대로 두고, LLM이 이 코드를 반복적으로 수정(변이)하고 결합(재조합)하여 자손 알고리즘을 생성합니다. 그 후 12개의 실제 데이터셋이라는 경주장에서 성능을 테스트하여 가장 성능이 좋은 알고리즘만 살려남기는 과정을 수백 번 반복하며, 인간이 설계하지 못한 새로운 최적의 공식을 찾아냅니다.
문제 정의
수십 년간 BM25나 Query Likelihood와 같은 어휘 기반 검색 알고리즘을 개선하려는 시도는 주로 파라미터 튜닝이나 연구자의 직관에 의존해 왔습니다. 이러한 수작업 방식에는 한계가 있으므로, 별도의 인간 개입 없이 LLM을 활용해 더 성능이 좋은 검색 알고리즘을 자동으로 발견할 수 있는지 탐구하는 것이 이 논문의 핵심 문제입니다.
🔬 방법론 상세
- 프로그램 합성(Program Synthesis)을 위한 검색 공간 정의: 초기 시드 알고리즘(BM25, QL)의 코드를 문서 표현, 쿼리 표현, 점수 함수(Scoring Function)라는 세 가지 추상 구성 요소로 분해하여 LLM이 수정할 수 있는 영역을 명확히 정의했습니다.
- LLM 주도의 진화적 탐색(LLM-guided Evolutionary Search): 단순한 무작위 코드 변경이 아니라, 구조화된 프롬프트를 통해 LLM이 코드의 논리를 이해하고 수정하도록 유도했습니다. 여기에는 섬 기반 진화(Island-based evolution)와 MAP-Elites 알고리즘을 적용하여 집단의 다양성을 유지했습니다.
- 다중 데이터셋 평가: 단일 데이터셋에 과적합되는 것을 방지하기 위해 BEIR과 BRIGHT에서 선정한 12개의 정보 검색(IR) 데이터셋에서의 성능 평균을 적합도(Fitness)로 사용하여 알고리즘을 선택했습니다.
핵심 기법
이 논문의 핵심은 알고리즘의 수식을 직접 수정하는 대신, 그 수식을 구현하는 파이썬 코드(약 300줄) 자체를 유기체로 보고 진화시킨다는 점입니다. LLM은 마치 돌연변이를 일으키는 유전자처럼, 기존 코드의 특정 부분(예: TF-IDF 계산 방식, 정규화 로직 등)을 삭제, 추가, 또는 변경하여 새로운 파생 알고리즘을 만들어내고, 이를 평가를 통해 걸러내는 과정을 반복합니다.
📊 정량적 결과
주요 성과
- BEIR 및 BRIGHT 벤치마크의 12개 데이터셋을 대상으로 한 실험에서, RankEvolve가 발견한 알고리즘들은 초기 시드인 BM25와 QL-Dirichlet은 물론, BM25+, BM25-adapt 같은 잘 알려진 변형 알고리즘들보다 일관되게 더 높은 검색 성능을 보였습니다.
- BM25 시드에서 300단계, QL-Dir 시드에서 200단계의 진화를 거쳐 각각 293단계와 182단계에서 최상의 성능을 보이는 프로그램이 도출되었습니다(평가에는 GPT-5.2 모델이 사용됨).
🚀 기존 대비 개선점
- 자동화된 발견 과정: 연구자의 직관이나 시행착오에 의존하던 기존 방식과 달리, LLM이 자동으로 검색 공간을 탐색하여 인간이 생각하지 못한 새로운 형태의 알고리즘을 발견해냅니다.
- 재발견 및 개선: 진화된 알고리즘이 과거에 잘 연구된 IR 개념들을 독자적으로 재발견하거나, 이를 새로운 방식으로 결합하여 성능을 개선했습니다.
🎯 활용 분야
- 엔터프라이즈 검색 엔진 최적화: 특정 도메인(법률, 의료 등)의 데이터에 맞춰 기존 BM25를 튜닝하는 것을 넘어, 그 도메인에 최적화된 완전히 새로운 랭킹 함수를 자동으로 개발할 수 있습니다.
- 신속한 알고리즘 프로토타이핑: 새로운 평가 지표나 데이터셋이 등장할 때마다 수동으로 알고리즘을 수정하는 대신, RankEvolve 프레임워크를 통해 해당 환경에 최적화된 알고리즘을 빠르게 생성할 수 있습니다.
한계 및 주의사항
- 알고리즘의 복잡성 증가: 진화된 알고리즘들은 초기 시드(BM25 등)에 비해 성능은 높지만 내부 로직이 훨씬 복잡해지는 경향이 있어, 해석이 어렵고 연산 비용이 증가할 수 있습니다.
- 우아함(Elegance)의 부재: 현재는 성능 최적화에만 집중되어 있어, 코드의 효율성이나 수식의 단순함 같은 ‘우아함’은 고려되지 않았습니다. 이는 향후 연구에서 개선이 필요한 부분입니다.
10. One-step Language Modeling via Continuous Denoising
arXiv: 2602.16813 | ⬆️ 3 | ⭐ 43 🤖 GLM추천 | 📄 HTML 태그:
flow-matchinglanguage-modelingdiscrete-diffusiongenerative-aidenoisingdistillationfew-step-generation사전 지식: Flow Matching, Diffusion Models, Autoregressive Models, One-hot Encoding, Cross-Entropy
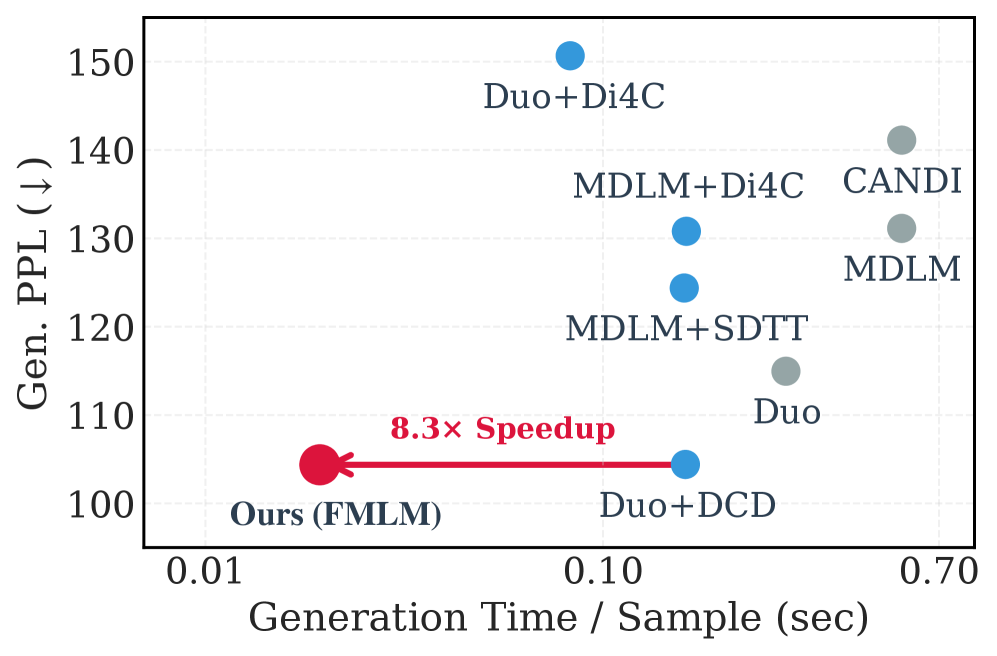
한 줄 요약
기존 자동회귀 모델의 느린 생성 속도와 불연속 확산 모델의 단계 수 감소에 따른 품질 저하 문제를 동시에 해결하여, 단 한 번의 단계(One-step)로도 고품질 텍스트를 생성할 수 있는 흐름 기반 언어 모델의 가능성을 입증했기 때문에 중요합니다.
💡 핵심 아이디어
텍스트 생성을 마치 잉크가 뭉개진 종이에서 단 몇 번의 붓질로 깨끗한 글씨를 복원하는 과정으로 생각해보세요. 기존의 불연속 확산 모델은 복원 횟수를 줄이면 글씨가 엉망이 되는 문제가 있었지만, 이 논문의 방법은 시간을 효율적으로 재배치하는 기법을 사용하여 딱 한 번의 붓질(One-step)로도 완벽한 문장을 만들어냅니다. 즉, 연속적인 공간에서 잡음을 제거하는 방식을 사용하여 속도는 훨씬 빠르면서도 성능은 더 좋은 결과를 얻었습니다.
문제 정의
오늘날 가장 성능이 좋은 언어 모델들은 토큰을 하나씩 순차적으로 생성하는 자동회귀(Autoregressive) 방식을 사용하기 때문에 생성 속도에 병목이 있습니다. 최근 제안된 불연속 확산(Discrete Diffusion) 모델은 전체 시퀀스를 병렬로 생성할 수 있어 잠재적인 해결책으로 보였으나, 실제로는 생성 단계 수를 줄였을 때 샘플의 품질이 급격히 떨어지는 현상이 발생하여 기대치를 충족하지 못했습니다.
🔬 방법론 상세
- 연속 표현 기반의 흐름 모델(FLM): 불연속적인 토큰을 원핫 인코딩(One-hot encoding)으로 변환하여 연속적인 공간에 매핑하고, 이 공간 위에서 유클리드 드노이징(Euclidean denoising)을 수행하는 흐름 기반 언어 모델을 구축했습니다.
- 시간 재매개변화(Time Reparameterization): 학습 및 생성 시간 단계를 균등하게 분배하는 것이 중요하다는 점을 발견했습니다. 단순히 균일한 시간 간격을 사용하는 대신, 디코딩 오류율을 고려하여 시간 변수를 재설계함으로써 생성 과정이 특정 시간 구간에 쏠리지 않고 안정적으로 학습되도록 만들었습니다.
- 플로우 맵 언어 모델(FMLM)을 통한 증류: 학습된 모델을 증류(Distillation)하여 멀리 떨어진 시점 사이의 상태를 직접 변환하는 플로우 맵을 만들었습니다. 이를 통해 수많은 단계를 거칠 필요 없이 단 한 번의 단계 혹은 매우 적은 단계로 고품질의 텍스트를 생성할 수 있게 되었습니다.
핵심 기법
이 논문의 성공 비결 중 하나는 바로 시간 재매개변화입니다. 모델이 깨끗한 데이터를 예측할 때, 시간 초기에 대부분의 결정을 내리고 나중에는 거의 하지 않는 불균형이 발생하는데, 이를 해결하기 위해 시간 척도를 조절해 각 단계가 생성 품질 향상에 균등하게 기여하도록 만든 것이죠. 이는 마치 요리할 때 재료를 넣는 타이밍을 조절해 맛을 골고루 살리는 것과 비슷합니다.
📊 정량적 결과
주요 성과
- LM1B 벤치마크에서 기존 증류된 불연속 확산 모델 대비 약 8.3배의 생성 속도 향상을 달성했습니다.
- 기존 모델이 8단계를 거쳐야 달성하던 성능을 단 1단계 생성만으로 따라잡거나 능가하는 성과를 보였습니다.
- 다양한 어휘 크기(Vocabulary size)에서 기존의 최신 불연속 확산 방식보다 더 높은 생성 품질을 입증했습니다.
🚀 기존 대비 개선점
- 기존 불연속 확산 모델이 가진 적은 단계 생성 시 품질 급락 문제를 해결하여 Few-step 생성에서도 우수한 성능을 유지합니다.
- 자동회귀 모델의 직렬적(Serial) 생성 병목을 제거하여 전체 시퀀스를 병렬로 매우 빠르게 생성할 수 있습니다.
- 복잡한 학습 목적함수 없이 단순한 교차 엔트로피(Cross-entropy) 목적만으로도 효율적으로 학습이 가능합니다.
🎯 활용 분야
- 실시간 대화형 AI 서비스: 사용자의 질문에 즉각적이고 자연스러운 답변을 생성해야 하는 챗봇 등에 적합합니다.
- 온디바이스 언어 생성: 모바일 기기와 같은 연산 자원이 제한된 환경에서도 빠른 텍스트 생성이 필요한 경우 유용합니다.
- 대규모 텍스트 요약 및 번역: 긴 문서를 처리하거나 실시간 번역이 필요한 상황에서 지연 시간을 획기적으로 줄일 수 있습니다.
한계 및 주의사항
- 계산 비용 증가: 원핫 인코딩(One-hot encoding)을 사용하기 때문에 학습 단계마다 전체 어휘 크기에 해당하는 임베딩 행렬을 계산하고 역전파해야 하므로, 관련 임베딩만 업데이트하는 방식에 비해 시간과 메모리 비용이 약 30% 정도 더 높습니다.
- 아직도 실험은 주로 LM1B와 같은 특정 데이터셋에서 수행되었으므로, 초거대 규모의 최신 LLM(Large Language Model) 규모에서도 동일한 효율성을 보일지 추가 검증이 필요합니다.
📅 생성일: 2026-02-25 | 🤖 GLM-4.7