📚 2026-02-24 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 A Very Big Video Reasoning Suite ⬆️301
- 📊📄 VLANeXt: Recipes for Building Strong VLA Mode… ⬆️39
- 📊📕 SkillOrchestra: Learning to Route Agents via … ⬆️28
- 📊📄 TOPReward: Token Probabilities as Hidden Zero… ⬆️21
- 📊📄 Mobile-O: Unified Multimodal Understanding an… ⬆️18
- 🤖📄 DSDR: Dual-Scale Diversity Regularization for… ⬆️10
- 🤖📄 SimToolReal: An Object-Centric Policy for Zer… ⬆️10
- 🤖📄 K-Search: LLM Kernel Generation via Co-Evolvi… ⬆️4
- 🤖📄 Decoding ML Decision: An Agentic Reasoning Fr… ⬆️1
- 🤖📄 Large Causal Models for Temporal Causal Disco…
1. A Very Big Video Reasoning Suite
arXiv: 2602.20159 | 기관: Video-Reason | ⬆️ 301 📊 순위선정 | 📄 HTML 태그:
video-reasoninglarge-scale-datasetscaling-lawscognitive-architecturemultimodal-aisotaevaluation-benchmark사전 지식: Video Generation (비디오 생성), Scaling Laws (스케일링 법칙), Cognitive Science (인지 과학), Grounding (그라운딩), Spatiotemporal Reasoning (시공간 추론)

한 줄 요약
비디오 모델이 단순히 예쁜 화면을 만드는 것을 넘어 물리 세계의 인과 관계와 논리적 추론 능력을 배우게 하기 위해, 100만 개 이상의 영상 클립과 체계적인 인지 과제를 포함한 최대 규모의 데이터셋과 평가 도구를 최초로 제시했다.
💡 핵심 아이디어
지금까지의 비디오 모델은 사실적인 영상을 만드는 ‘화가’에 불과했지만, 이 논문은 물리 법칙과 시간의 흐름에 따른 이해가 가능한 ‘물리학자’로 AI를 훈련시키기 위한 거대한 도서관을 건설한 것과 같습니다. 아리스토텔레스와 칸트의 인지론을 바탕으로 단순한 시각 인지를 넘어 기억, 공간, 변형을 다루는 5가지 인지 능력을 체계적으로 학습할 수 있도록 설계되었습니다.
문제 정의
최근 대형 언어 모델(LLM)은 텍스트 기반의 추론 능력에서 획기적인 발전을 이루었지만, 영상 생성 모델은 시각적 품질에만 집중하여 논리적 추론이나 물리 법칙 이해 능력이 부족했습니다. 더 심각한 문제는 비디오 추론 능력을 체계적으로 연구하고 모델의 성장을 확인할 수 있는 대규모의 고품질 학습 데이터와 평가 도구가 전무하다는 점이었습니다.
🔬 방법론 상세
- 인지 아키텍처(Cognitive Architecture) 기반 설계: 아리스토텔레스와 칸트의 철학적, 인지과학적 이론을 종합하여 5가지 핵심 인지 능력(faculties)을 정의했습니다. 여기에는 감지(Perception), 변형(Transformation), 공간성(Spatiality) 등이 포함되며, 이를 통해 영상 속의 물체가 어떻게 움직이고 상호작용하는지를 이해하도록 과제를 구성했습니다.
- VBVR 데이터셋(VBVR-Dataset) 구축: 기존 데이터셋보다 약 1,000배 큰 규모인 100만 개 이상의 비디오 클립과 200개 이상의 선별된 추론 과제를 포함시켰습니다. 이는 모델이 데이터 양이 늘어날 때 어떻게 추론 능력이 발현하는지 연구할 수 있게 합니다.
- 검증 가능한 평가 툴킷(VBVR-Bench): 단순한 주관적 평가 대신, 모델의 비디오 추론 능력을 재현 가능하고 검증 가능한 원칙하에서 측정할 수 있는 표준화된 벤치마크를 제공합니다.
핵심 기법
이 논문의 핵심은 단순히 많은 데이터를 던져주는 것이 아니라, ‘인지 능력’을 기준으로 데이터를 분류했다는 점입니다. 예를 들어 ‘감지(Perception)’ 과제에서는 모델이 색상이나 모양을 구별하는지 확인하고, ‘변형(Transformation)’ 과제에서는 마음속으로 물체를 회전시키거나 조작하는 능력을 테스트합니다. 마치 아이가 세상을 배울 때 감각 → 기억 → 이해의 순서로 발달하듯이, AI에게도 이러한 인지 발달 과정을 거치게 하는 커리큘럼을 설계한 것입니다.
📊 정량적 결과
주요 성과
- VBVR 데이터셋으로 훈련된 모델(VBVR-Wan2.2)의 성능: 전체 평균 점수(Overall Avg.)에서 0.685를 기록했습니다.
- 최신 오픈소스 모델 대비 우수성: 동일 계열의 기존 오픈소스 모델(Wan2.2-I2V-A14B)은 0.371에 그쳤으나, VBVR 데이터셋으로 학습한 모델은 약 84% 이상의 성능 향상을 보여주었습니다.
- 최신 상용 모델(Sora 2) 대비 우수성: 오픈AI의 Sora 2가 0.546을 기록한 반면, VBVR-Wan2.2는 0.685를 기록하여 약 25% 더 높은 추론 능력을 보여주었습니다.
🚀 기존 대비 개선점
- 데이터셋의 규모가 기존 대비 약 세 자릿수(1,000배) 이상 커져서 비디오 모델의 스케일링 법칙(Scaling Laws, 모델 크기나 데이터 양에 따른 성능 변화)을 처음으로 비디오 추론 분야에서 적용할 수 있게 되었습니다.
- 인지 과학에 기반한 200개의 다양한 과제를 통해 모델이 특정 상황에만 과적합(Overfitting, 학습 데이터에만 잘 맞추는 현상)되는 것을 방지하고 일반화된 추론 능력을 갖추도록 했습니다.
- 재현 가능한 평가 도구를 통해 연구자들이 객관적으로 모델의 능력을 비교하고 발전시킬 수 있는 표준을 마련했습니다.
🎯 활용 분야
- 물리적 세계를 이해하는 AI 로봇: 로봇이 영상을 보고 물체의 상호작용이나 물리 법칙(중력, 충돌 등)을 이해하고 행동하는 데 활용할 수 있습니다.
- 고급 비디오 QA(Video Question Answering): 단순히 영상 내의 객체를 찾는 것을 넘어 “이 영상에서 왜 그 물체가 넘어졌는가?”와 같은 인과 관계 질문에 답할 수 있는 시스템을 만들 수 있습니다.
- 자율 주행 및 감시 시스템: 도로의 복잡한 상황에서 시간의 흐름에 따른 사고의 원인을 추론하고 미래의 위험을 예측하는 데 사용될 수 있습니다.
한계 및 주의사항
- 인간의 성능(약 0.974)에 비해 최상위 모델의 점수(약 0.685)는 아직 낮은 수준이며, 비디오 추론에는 해결해야 할 근본적인 어려움이 남아 있습니다.
- 특히 영역 밖(Out-of-Domain, 학습되지 않은 새로운 유형의 데이터) 일반화 성능은 영역 내(In-Domain) 성능보다 상대적으로 낮아, 새로운 환경에 대한 적응력이 더 필요합니다.
2. VLANeXt: Recipes for Building Strong VLA Models
arXiv: 2602.18532 | 기관: MMLab@NTU | ⬆️ 39 | ⭐ 43 📊 순위선정 | 📄 HTML 태그:
vlaroboticsfine-tuningbenchmarkingliberosimulationgeneralizationbimanual사전 지식: VLA (Vision-Language-Action), Fine-tuning (파인 튜닝), Perturbation (섭동), Sim-to-Real (시뮬레이션에서 실제 세계로의 전이), Foundation Model (파운데이션 모델)

한 줄 요약
파편화된 VLA 연구 영역에 통합된 평가 프레임워크를 적용하여, 실제 성능과 일반화에 중요한 설계 선택지를 체계적으로 규명하여 더 작고 효율적인 모델로도 우수한 성능을 내는 방법을 제시했기 때문에 중요합니다.
💡 핵심 아이디어
로봇 제어 모델인 VLA를 요리에 비유하자면, 각 연구팀이 자신만의 방식으로 재료를 넣던 것을 이 논문은 ‘맛을 결정짓는 핵심 재료와 조리 순서’를 과학적으로 분석하여 정리한 ‘마스터 레시피’라고 볼 수 있습니다. RT-2나 OpenVLA 같은 기존 모델을 기반으로 기본 구조, 시각 인지, 행동 모델링이라는 세 가지 핵심 요소를 체계적으로 개선함으로써, 더 작은 모델 사이즈로도 더 강력한 성능을 끌어냈습니다.
문제 정의
현재 VLA(Vision-Language-Action) 모델 연구는 각기 다른 학습 프로토콜과 평가 설정을 사용하고 있어, 어떤 설계 선택이 실제 성능 향상에 기여했는지 명확히 파악하기 어려운 파편화된 상태입니다. 이 논문은 이러한 혼란을 해결하고 통합된 기준 하에 어떤 설계가 진정으로 효과적인지 규명하고자 합니다.
🔬 방법론 상상
- 통합된 평가 프레임워크: RT-2와 OpenVLA와 유사한 간단한 기본 모델(Baseline)에서 출발하여, LIBERO 및 LIBERO-plus 벤치마크를 통해 다양한 설계 선택을 체계적으로 비교 분석했습니다.
- 세 가지 차원의 설계 분석:
- 기초 구조(Foundational Components): 모델의 백본(Bone, 기본 뼈대)과 투사기(Projector, 정보를 연결하는 장치) 등을 분석.
- 인지 필수 요소(Perception Essentials): 시각적 정보를 처리하는 방식을 최적화.
- 행동 모델링(Action Modeling): 로봇의 행동(Action)을 토큰화하거나 예측하는 방식을 개선.
- 강건성(Robustness) 테스트: 단순한 성능 평가를 넘어, 조명, 배경, 카메라 각도, 물체 배치, 언어 지시 변경 등 다양한 변동(Perturbation)이 포함된 LIBERO-plus 데이터셋을 사용하여 모델의 일반화 능력을 검증했습니다.
핵심 기법
이 논문의 가장 중요한 기법은 단순히 모델을 크게 만드는 것이 아니라, 사전 학습된 대규모 데이터셋(DROID)에서 지식을 이전받은 후, 실제 작업 데이터셋(LIBERO)으로 파인 튜닝(Fine-tuning, 미세 조정)할 때 어떤 구조적 요소가 가장 효율적으로 성능을 높이는지 ‘레시피’ 형태로 정리했다는 점입니다. 특히 쌍봉(Bimanual, 두 팔을 사용하는) 작업에 적응할 때 특정 레이어만 재초기화하여 데이터 부족 문제를 해결하는 등 실용적인 전략을 제시합니다.
📊 정량적 결과
주요 성과
- 모델의 크기는 더 작음에도 불구하고 LIBERO 및 LIBERO-plus 벤치마크에서 기존 대표 모델들(RT-2, OpenVLA 등)보다 더 높은 작업 성공률을 기록했습니다.
- 실제 세계 실험(Real-World Evaluations)에서는 단일 팔과 쌍봉 로봇을 모두 사용하여 테이블 청소, 서랍 조작, 바구니 들기 등 4가지 작업을 수행했으며, 각 작업당 50개의 에피소드(Episode, 한 번의 시도 단위)로 학습하여 20번의 시행 평가를 통해 유효성을 입증했습니다.
🚀 기존 대비 개선점
- 파편화되어 있던 VLA 설계 공간을 ‘기초 구조’, ‘인지’, ‘행동 모델링’의 세 가지 축으로 체계화하여 연구자들이 명확한 가이드라인을 따르도록 했습니다.
- 다양한 시각적, 물리적, 의미적 섭동(Perturbation, 외부 방해)이 포함된 환경에서도 강건한 성능을 보이도록 설계하여, 실제 로봇 적용 시 발생하는 변화에 잘 대처할 수 있게 했습니다.
🎯 활용 분야
- 다양한 물건을 집어 옮기거나 정리하는 가정용 서비스 로봇 개발
- 서랍을 열거나 조작하는 등 정밀한 제어가 필요한 산업용 팔로봇
- 두 팔을 협동시켜 바구니를 들어 올리는 등 복잡한 쌍봇(Bimanual) 로봇 제어 시스템
한계 및 주의사항
- 사전 학습에 사용된 DROID 데이터셋이 단일 팔(Single-arm) 데이터 위주여서, 쌍봇 작업에 적용할 때는 자세 인지 투사기(Proprioception Projector)와 행동 생성 모듈의 마지막 레이어를 재초기화해야 하는 등 데이터 의존적인 제약이 있습니다.
3. SkillOrchestra: Learning to Route Agents via Skill Transfer
arXiv: 2602.19672 | 기관: University of Wisconsin - Madison | ⬆️ 28 📊 순위선정 | 📕 PDF 태그:
llmorchestrationmulti-agentroutingskill-transfercompound-aiefficiencyreasoning사전 지식: Large Language Model (LLM), Compound AI System, Reinforcement Learning (강화학습), Orchestration (오케스트레이션), Multi-hop Reasoning (멀티 홉 추론)
한 줄 요약
여러 AI 에이전트와 도구를 효율적으로 조율하는 기존의 한계를 극복하고, 숙련된 기술(Skill)을 학습하여 비용은 낮추고 성능은 최적화하는 새로운 오케스트레이션(Orchestration) 프레임워크를 제시했기 때문에 중요합니다.
💡 핵심 아이디어
마치 오케스트라 지휘자가 연주자들의 개별 악기 연주 능력을 정확히 파악하여, 악보의 각 구간마다 가장 적합한 연주자를 지휘하는 것과 같습니다. 단순히 가장 비싼 모델에 모든 일을 맡기는 대신, 작업을 세밀한 기술 단위로 나누어 각 기술에 가장 특화되고 비용 효율적인 에이전트를 동적으로 배정합니다.
문제 정의
기존의 라우팅(Routing) 방식은 입력 단계에서만 결정을 내려 세분화된 요구사항을 무시하거나, 강화학습(RL) 기반 방식이 비싼 최상위 모델만 반복적으로 호출하는 라우팅 붕괴(Routing Collapse) 문제를 겪습니다. 멀티 턴(Multi-turn) 환경에서 동적으로 변하는 작업 요구사항에 맞춰 적절한 모델과 도구를 선택하는 것이 어렵습니다.
🔬 방법론 상세
- 스킬 핸드북(Skill Handbook) 구성: 실행 경험(Execution Experience)에서 세밀한 기술(Skill)을 학습하여 저장소를 만듭니다. 이는 에이전트별 특정 기술에 대한 숙련도와 비용을 명시적으로 모델링합니다.
- 역량 및 비용 모델링(Capacity and Cost Modeling): 각 에이전트가 특정 스킬을 얼마나 잘 수행하는지(Competence)와 그에 따른 비용(Cost)을 정량화하여 학습합니다.
- 스킬 기반 라우팅(Skill-based Routing): 배포 시점에 현재 상호작용의 맥락에서 필요한 스킬을 추론하고, 사전에 학습된 핸드북을 참조하여 가장 효율적인 에이전트를 선택합니다.
핵심 기법
가장 중요한 기법은 스킬 핸드북(Skill Handbook)의 재사용성(Transferability)입니다. 이는 단순히 라우팅 정책을 처음부터 끝까지 학습하는 것이 아니라, 에이전트들의 기술(Skill)을 독립적으로 정의하고 학습하여 다른 시스템이나 작업에도 별도의 훈련 없이 즉시 적용할 수 있게 만드는 핵심 구성 요소입니다.
📊 정량적 결과
논문은 Figure 1을 통해 SkillOrchestra가 모든 기준선(Baseline)보다 높은 정확도와 낮은 비용을 달성하여 파레토 최적(Pareto Frontier)에 위치한다고 주장합니다. 정확한 수치는 텍스트에 명시되지 않았으나, 다양한 벤치마크에서 기존 방법 대비 우월한 효율성을 입증했습니다.
주요 성과
- 벤치마크: Natural Question, TriviaQA, HotpotQA, MATH 등의 지식 및 추론 중심 작업에서 평가 수행
- 효율성: 모델 라우팅(Model Routing) 설정에서 외부 도구 없이 순수 오케스트레이션 품질만으로도 기존 방법보다 우수한 성능(cost-accuracy trade-off)을 보임
🚀 기존 대비 개선점
- 세밀한 수준의 의사결정을 통해 쿼리(Query) 단위의 거친 분류가 아닌, 변화하는 작업 요구사항에 즉각적으로 대응합니다.
- 비싼 모델만을 반복 호출하는 라우팅 붕괴(Routing Collapse) 현상을 방지하여 리소스를 효율적으로 분배합니다.
- 학습된 스킬 핸드북을 재사용할 수 있어 새로운 시스템 적응 시 추가 학습 비용과 시간을 절약합니다.
🎯 활용 분야
- 웹 검색, 코드 실행, 답변 종합 등 여러 도구를 혼합해 사용하는 복합 AI 시스템(Compound AI Systems)
- 복잡한 다단계 연구(Deep Research)나 과학적 발견(Scientific Discovery)을 수행하는 자동화 에이전트
- 다양한 규모의 LLM(Large Language Model)을 활용하여 서비스 운영 비용을 최적화해야 하는 기업용 애플리케이션
한계 및 주의사항
- 스킬 핸드북을 구축하기 위해 양질의 실행 경험(Execution Experience) 데이터가 축적되어야 하므로, 초기 데이터 수집 및 학습 단계에서 비용이 발생할 수 있습니다.
4. TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for Robotics
arXiv: 2602.19313 | 기관: Ai2 | ⬆️ 21 📊 순위선정 | 📄 HTML 태그:
roboticsreinforcement-learningreward-modelingvlmzero-shottransfer-learningembodied-ai사전 지식: Reinforcement Learning (강화 학습), Sparse Rewards (희소 보상), Fine-tuning (미세 조정), Vision-Language Model (비전-언어 모델), Zero-shot Learning (제로 샷 학습)

한 줄 요약
사전 학습된 비디오 언어 모델의 토큰 확률을 활용해 별도의 미세 조정 없이 로봇 작업의 진척도를 정밀하게 평가하는 제로 샷 보상 모델을 제안하여, 실제 환경 강화 학습의 낮은 샘플 효율성 문제를 해결했다.
💡 핵심 아이디어
로봇에게 수치적인 점수(예: 지금 50% 진행됨)를 직접 말하게 하는 대신, 작업이 완료되었는지 여부를 묻는 질문(예: 작업을 끝냈니?)을 던지고 모델이 “그렇다(True)“라고 대답할 확률을 측정하는 방식입니다. 이는 마치 학생에게 시험 점수를 구체적으로 예측하게 하는 어려운 대신, 시험을 잘 봤다는지에 대한 자신감 정도를 확인하여 진척도를 가늠하는 것과 같습니다.
문제 정의
실제 로봇 환경에서 강화 학습(Reinforcement Learning)을 적용할 때, 작업이 성공했는지 알려주는 보상 신호가 너무 드물게(Sparse) 주어지거나 데이터 효율이 낮아 학습이 매우 어렵습니다. 기존에 이를 해결하기 위해 개발된 보상 모델들은 새로운 작업이나 다른 로봇 환경에 적용할 때마다 방대한 데이터로 추가 학습을 해야 하는 일반화의 한계가 있었습니다.
🔬 방법론 상세
-
토큰 확률 기반 보상 설계 기존 방식처럼 모델이 직접 수치를 생성하도록(Free-form generation) 유도하는 대신, 모델의 내부 출력인 다음 토큰 예측 확률을 활용합니다. 구체적으로는 “현재 궤적이 지시사항을 완수했는가?”라는 질문을 던졌을 때, 모델이 긍정적인 답변(예: “True”) 토큰을 출력할 확률을 보상 신호로 정의합니다. 이는 모델의 수리적 추론 능력이나 지시 수행 능력에 의존하지 않고, 내부적인 비디오 이해 능력을 직접적으로 끌어냅니다.
-
시계열적 진척도 추정 시간 순서대로 정렬된 비디오 프레임의 접두사(Prefix)를 순차적으로 모델에 입력합니다. 시점이 지나감에 따라 긍정 답변 토큰의 확률이 점진적으로 증가하는지를 확인하여, 스칼라 진척도 신호를 생성합니다. 이를 통해 단순한 성공/실패 분류를 넘어 과정(Process)에 대한 밀도 높은 피드백을 제공합니다.
-
제로 샷(Zero-shot) 추론 로봇 데이터로 미세 조정(Fine-tuning)하지 않은 일반적인 비디오 언어 모델(VLM)을 그대로 사용합니다. 모델이 학습 과정에서 습득한 잠재적인 세상 지식(Latent world knowledge)을 활용하여, 특정 도메인에 국한되지 않고 로봇의 작업 진행 상황을 판단합니다.
핵심 기법
이 논문의 가장 큰 통찰은 "모델이 수치를 잘 맞추게 하는 것은 어렵지만, 참/거짓을 판단하는 내부 확신도는 훨씬 정확하다"는 점입니다. 모델이 외부로 출력하는 텍스트보다는, 내부적으로 계산된 토큰의 확률 분포가 오히려 진척도를 더 잘 반영한다는 점을 역이용하여 복잡한 수치 생성 과정을 우회했습니다.
📊 정량적 결과
주요 성과
- 오픈 소스 모델인 Qwen3-VL-8B를 기반으로 한 TOPReward는 Open X-Embodiment 데이터세트(39개 데이터세트, 780개 에피소드)에서 평균 VOC(Value of Correctness) 0.857을 달성했습니다.
- 새롭게 제안한 ManiRewardBench(113개 작업, 4개 로봇 플랫폼)에서는 0.947의 VOC를 기록하여 기존 최첨단 모델인 GVL을 큰 폭으로 능가했습니다.
- 이는 로봇의 형태(Embodiment)나 시점(View)이 달라지는 상황에서도 우수한 일반화 성능을 보임을 의미합니다.
🚀 기존 대비 개선점
- 별도의 로봇 데이터로 학습할 필요 없는 진정한 제로 샷(Zero-shot) 능력을 확보했습니다.
- 모델이 수치를 직접 생성하는 방식에서 발생하는 오표현(Numerical misrepresentation) 문제를 근본적으로 해결했습니다.
- 다양한 로봇 플랫폼과 시점에 대해 강건한(Robust) 보상 신호를 제공하여 기존 방법보다 훨씬 더 넓게 적용할 수 있습니다.
🎯 활용 분야
- 실제 환경에서 작동하는 로봇 팔의 강화 학습(RL) 훈련 시 밀도 높은 보상 제공
- 서로 다른 형태의 로봇이나 카메라 각도가 다른 환경으로의 지식 전이(Transfer Learning)
- 로봇이 작업을 성공적으로 완수했는지 판단하는 성공 감지 시스템
한계 및 주의사항
- 이 방법의 성능은 기본적으로 사전 학습된 비디오 언어 모델(VLM)이 가진 내부 지식 수준에 의존적입니다. 모델이 특정 물리 법칙이나 물체의 특성을 이해하지 못한다면 보상 신호도 부정확해질 수 있습니다.
5. Mobile-O: Unified Multimodal Understanding and Generation on Mobile Device
arXiv: 2602.20161 | 기관: Mohamed Bin Zayed University of Artificial Intelligence | ⬆️ 18 | ⭐ 35 📊 순위선정 | 📄 HTML 태그:
unified-multimodaledge-computingmobile-aidiffusion-modelsvlmefficient-transformeron-device-inference사전 지식: Vision-Language Model (VLM, 시각-언어 모델), Diffusion Model (확산 모델), Depthwise Separable Convolution (깊이별 분리 합성곱), Edge Computing (엣지 컴퓨팅), Transformer (트랜스포머)
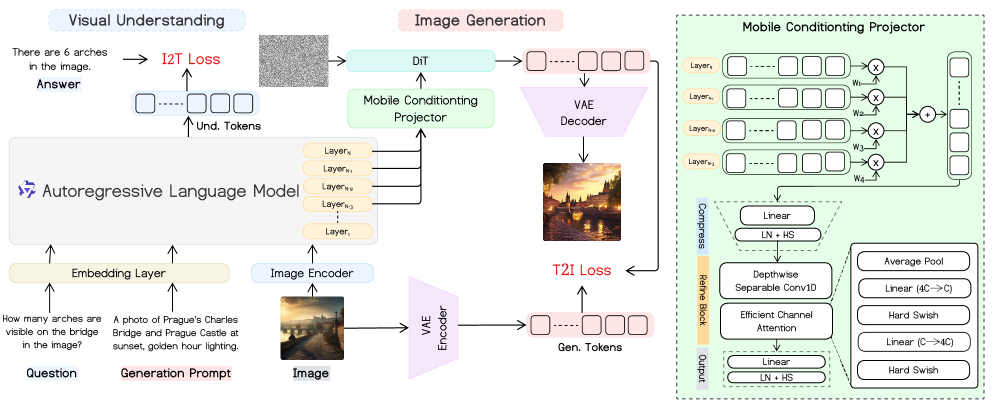
한 줄 요약
이 논문은 방대한 연산 자원이 필요했던 기존 통합 멀티모달 모델의 한계를 극복하여, 이미지 이해와 생성 능력을 모두 갖춘 경량화 모델을 모바일 기기에서 실시간으로 구동할 수 있게 만든 획기적인 연구이기 때문에 중요합니다.
💡 핵심 아이디어
작은 방에서 일하는 두 명의 전문가(이해 전문가와 생성 전문가)를 상상해 보세요. 기존 방식은 이 둘 사이에 중개인을 두어 대화를 나누게 해서 비효율적이었습니다. Mobile-O는 이 두 전문가의 머리에 초고속 통신 헤드셋(MCP)을 직접 연결하여, 중개인 없이 즉시 생각을 주고받게 함으로써, 좁은 방(모바일 기기) 안에서도 매우 효율적으로 협력할 수 있게 만들었습니다.
문제 정의
기존의 통합 멀티모달 모델(Understanding과 Generation을 동시에 하는 모델)은 성능이 뛰어나지만, 모델의 크기가 너무 크고(수십억 개의 파라미터) 연산량이 많아 스마트폰이나 엣지 장치(Edge Device)에 탑재하기 어렵다는 문제가 있었습니다.
🔬 방법론 상세
- 모바일 컨디셔닝 프로젝터(MCP, Mobile Conditioning Projector): 기존의 MLP(Multi-Layer Perceptron) 층이나 학습 가능한 쿼리 토큰을 사용하는 대신, 깊이별 분리 합성곱(Depthwise Separable Convolution)과 채널 어텐션(Channel Attention)을 활용하여 시각-언어 특징을 확산 모델(Diffusion Model)로 직접 전달합니다.
- 사중쌍(Quadruplet) 형식의 학습 데이터: (생성 프롬프트, 이미지, 질문, 답변)의 4가지 요소로 구성된 새로운 데이터 형식을 사용하여 모델이 이해와 생성 task를 동시에 학습할 수 있도록 통합하여 훈련시킵니다.
- 경량화 아키텍처: 이미지 인코더로는 FastViT, 언어 모델로는 Qwen2-0.5B, 이미지 생성기로는 선형 확산 트랜스포머(DiT, Diffusion Transformer)를 사용하여 전체 파라미터 수를 획기적으로 줄였습니다.
핵심 기법
가장 중요한 기법은 MCP(Mobile Conditioning Projector)입니다. 보통 ‘이해’ 모델과 ‘생성’ 모델을 연결할 때 복잡한 중간 단계(학습 가능한 쿼리 등)를 거치면 데이터가 적을 때 성능이 떨어지고 계산이 느려집니다. MCP는 가중치가 부여된 은닉 상태를 이용해 확산 생성 모델을 조건화(Conditioning)하여, 계산 비용을 최소화하면서도 고품질의 이미지를 생성할 수 있게 ‘지름길’을 만들어주는 역할을 합니다.
📊 정량적 결과
주요 성과
- GenEval 벤치마크에서 2B 이하의 크기를 가진 경쟁 모델들보다 높은 0.74의 종합 점수를 기록했습니다.
- 아이폰(Iphone) 기기에서 메모리 사용량 2GB 미만으로 유지되며, 약 3초 만에 이미지 생성을 완료하여 실시간 성능을 입증했습니다.
- 약 300만 개의 적은 데이터 샘플만으로도 훈련이 가능하여 데이터 효율성이 매우 뛰어납니다.
🚀 기존 대비 개선점
- 기존 대형 통합 모델(예: BLIP-3o 등)은 수십억 개의 파라미터를 필요로 하고 서버 환경에서만 구동 가능했지만, Mobile-O는 모바일 기기에서 직접 구동 가능한 수준으로 경량화되었습니다.
- 별도의 중간 쿼리 토큰 없이 모델 간 특징을 직접 융합하여, 연산 속도와 메모리 효율성을 동시에 개선했습니다.
- 적은 데이터로도 사후 훈련(Post-training)이 가능하여, 실제 환경에서의 모델 적용 난이도를 낮췄습니다.
🎯 활용 분야
- 오프라인 상태에서도 작동하는 모바일 생성형 AI 어시스턴트 (사진 촬영 후 즉시 설명하거나 편집하는 앱)
- 개인정보 보호가 중요한 의료/보안 영역에서의 엣지 디바이스 기반 이미지 분석 및 생성
- 증강 현실(AR) 안경이나 모바일 기기에서 실시간으로 사용자의 입력에 반응하여 이미지를 생성하는 콘텐츠 제작 도구
한계 및 주의사항
- 아주 복잡한 추론이나 초고해상도 이미지 생성에서는 클라우드 기반의 거대 모델보다 성능이 낮을 수 있습니다.
- 텍스트 기반의 세밀한 컨트롤이나 지극히 난해한 시각적 개념에 대한 생성 능력은 모델의 크기 한계로 인해 제약이 있을 수 있습니다.
6. DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning
arXiv: 2602.19895 | ⬆️ 10 🤖 GLM추천 | 📄 HTML 태그:
llmrlvrdsdrreasoningexplorationgrpofine-tuningreinforcement-learning사전 지식: 강화 학습(RLHF), 정책 최적화(PPO), 엔트로피 정규화, LLM 추론(Reasoning), 검증 기반 보상(Verifier-based Reward)

한 줄 요약
이 논문은 강화 학습 기반 LLM(Large Language Model) 추론 훈련에서 나타나는 탐험의 부족과 다양성 소멸 문제를, 글로벌(전역)과 로컬(지역) 두 가지 규모의 다양성 정규화를 결합하여 해결하고 추론 성능을 획기적으로 개선했다는 점에서 매우 중요합니다.
💡 핵심 아이디어
복잡한 미로를 탈출하는 로봇을 훈련시킨다고 상상해 보세요. 기존 방식은 로봇이 한 번 정답 경로를 찾으면 그 길로만 계속 가려 하여(수렴), 다른 더 빠르거나 효율적인 길을 놓치는 문제가 있었습니다. DSDR(Dual-Scale Diversity Regularization)은 로봇에게 “정답에 도달하는 서로 다른 길들을 여러 개 찾아내라”고 장려하는 동시에(글로벌 다양성), 각 길을 걷을 때도 너무 기계적이지 않고 유연하게 움직이게(로컬 다양성) 만들어 탐험 범위를 극대화하는 내비게이션 시스템과 같습니다.
문제 정의
검증자(Verifier)와 함께하는 강화 학습(RLVR)을 통해 LLM의 추론 능력을 향상시킬 때, 모델이 정답을 맞히는 Pass@1 성능은 올라가지만 여러 가지 정답 경로를 탐색하는 능력(Pass@k)은 저하되는 ‘해결책 다양성 붕괴(Solution Diversity Collapse)’ 현상이 발생합니다. 기존의 엔트로피(Entropy) 정규화 방식은 토큰 단위의 국지적 무작위성만 추가할 뿐, 의미 있는 경로 수준의 다양성을 유도하지 못해 학습 신호가 약하고 불안정한 문제가 있었습니다.
🔬 방법론 상세
- GRPO 기반 최적화 백본: 그룹 상대 정책 최적화(Group Relative Policy Optimization)를 기반으로 하여, 생성된 후보군들 내에서 보상을 정규화하여 학습의 안정성을 확보합니다. 검증자(Verifier)는 완성된 시퀀스에 대해 이진(Binary) 보상을 제공합니다.
- 글로벌 다양성(Global Diversity, GD) 정규화: 정답인 궤적들 사이에서 서로 다른 해결 모드(Solution Mode)가 더 많이 발현되도록 유도합니다. 모델이 하나의 올바른 패턴에만 집중하지 않고, 문제를 푸는 다양한 방식을 유지하도록 장려합니다.
- 글로벌-투-로컬 커플링(Global-to-Local Coupling, GC): 글로벌하게 구분되는 올바른 궤적에 대해 로컬 정규화를 집중시키는 메커니즘입니다. 글로벌 다양성이 높은 샘플일수록 로컬 정규화 효과를 더 받도록 하여 두 규모의 다양성을 긴밀하게 연결합니다.
- 길이 불변 로컬 엔트로피 정규화: 길이에 영향을 받지 않는 토큰 수준 엔트로피 정규화를 ‘정답 궤적’에만 적용합니다. 이는 같은 해결 모드 내에서 토큰 선택이 너무 확정적(Deterministic)으로 변하여 모델이 경직되는 것을 방지합니다.
핵심 기법
가장 중요한 포인트는 **‘정답에 맞춘 다양성’**입니다. 기존 방식은 틀린 답을 포함해 무조건 다양하게 만들려 해 학습 효율이 떨어졌지만, DSDR은 올바른 해결책들만 모아서 그 안에서의 다양성을 강제합니다. 즉, “무조건 새로운 길을 가라”가 아니라 “목적지에 도달하는 서로 다른 새로운 길들을 더 많이 찾아라”라고 가르치는 핵심적인 전략적 변화가 적용되었습니다.
📊 정량적 결과
Qwen3-1.7B 모델을 기준으로 다양한 수학 및 추론 벤치마크(AIME24, AIME25, MATH500 등)에서 평균 성능을 측정했습니다.
주요 성과
- 평균 정확도(Average): 기존 GRPO(28.4%) 대비 DSDR은 **36.8%**을 기록하여 약 8.4%p의 큰 폭의 성능 향상을 보였습니다.
- AIME24 벤치마크: Qwen3-1.7B 모델에서 GRPO는 16.7%였으나, DSDR은 **36.7%**로 2배 이상의 향상된 성능을 보여주었습니다.
- 소거 실험(Ablation Study): 글로벌 다양성(GD)을 제거했을 때 성능이 29.7%로 떨어지고, 커플링(GC)을 제거했을 때도 35.1%로 하락하여, 제안하는 두 가지 구성 요소가 모두 성능 향상에 필수적임을 입증했습니다.
🚀 기존 대비 개선점
- 탐험의 깊이 향상: 기존 방식들이 조기에 탐험을 멈추고 국소 최적해(Local Optima)에 갇히는 반면, DSDR은 다양한 경로를 통해 탈출하여 더 깊은 추론이 가능합니다.
- 그룹 기반 학습 신호 강화: 다양한 올바른 경로를 유지함으로써 그룹 내 상대 비교를 통한 학습 신호가 더 풍부해지고 안정적입니다.
- 엔트로피 붕괴 방지: 정답 궤적 내에서 토큰 수준의 엔트로피가 과도하게 줄어드는 현상을 막아 모델의 유연성을 보존합니다.
🎯 활용 분야
- 수학 문제 해결(Math Reasoning): 특히 정답을 유일하게 검증할 수 있고, 여러 가지 증명 방법이 존하는 고등 수학 및 올림피아드 수준의 문제 해결에 효과적입니다.
- 코딩 테스트 및 코드 생성(Code Generation): 하나의 문제를 해결하는 다양한 알고리즘이나 구현 방식을 탐색해야 하는 소프트웨어 개발 과정에 활용될 수 있습니다.
- 복잡한 논리 추론(Logical Inference): 다단계 사고가 필요하고 단순히 하나의 정답이 아닌 다양한 논리적 경로를 요구하는 추론 태스크에 적합합니다.
한계 및 주의사항
- 검증자(Verifier) 의존성: 이 방법론은 결과를 바탕으로 보상을 주는 검증자가 반드시 필요하므로, 수학이나 코드처럼 정답 여부를 자동으로 확인할 수 있는 영역에 주로 국한됩니다.
-
- 계산 비용: 여러 후보군을 생성하고 그룹 단위로 비교하는 방식은 단순 생성보다 더 많은 연산 자원과 추론 시간을 요구할 수 있습니다.
7. SimToolReal: An Object-Centric Policy for Zero-Shot Dexterous Tool Manipulation
arXiv: 2602.16863 | 기관: Stanford University | ⬆️ 10 | ⭐ 16 🤖 GLM추천 | 📄 HTML 태그:
sim-to-realdexterous-manipulationrltool-usezero-shotroboticsobject-centricprocedural-generation사전 지식: Sim-to-Real Transfer, Reinforcement Learning, Dexterous Manipulation, Zero-Shot Learning, Goal-Conditioned Policy

한 줄 요약
시뮬레이션에서 절차적으로 생성된 다양한 도구를 통해 훈련된 단일 정책을 사용하여, 실제 환경에서 별도의 추가 학습이나 모델링 없이도 보지 못한 도구를 정교하게 조작할 수 있는 제로샷(Zero-Shot) 일반화 가능성을 처음으로 입증했기 때문입니다.
💡 핵심 아이디어
로봇에게 ‘망치로 못 박기’ 같은 특정 작업을 하나씩 가르치는 대신, ‘물건을 원하는 위치와 방향으로 옮기기’라는 보편적인 기술을 집중적으로 훈련시킵니다. 마치 피아노 연주자가 특정 곡만 연습하는 것이 아니라, 도(re), 레(mi) 같은 기본적인 위치를 정확하게 치는 기술을 마스터한 뒤에 악보(인간의 동작 영상)를 보면 어떤 곡이든 즉석에서 연주할 수 있는 것과 같습니다.
문제 정의
정교한 도구 조작(Dexterous Tool Manipulation)은 로봇이 얇은 손잡이를 잡거나 손 안에서 도구를 회전시키는 등 높은 난이도의 기술이 필요합니다. 기존에는 사람이 직접 로봇을 조작하여 데이터를 수집하거나, 각 작업마다 시뮬레이션 환경과 보상 함수를 새로 설계해야 하는 등 공학적 노력이 과도하게 필요했습니다.
🔬 방법론 상세
- 객체 중심 축소(Object-Centric Reduction): 도구 사용 작업을 복잡한 작업별 문제가 아닌, 도구를 일련의 목표 자세(Goal Pose)로 이동시키는 문제로 단순화합니다.
- 목표 조건부 강화 학습(Goal-Conditioned RL): 시뮬레이션 내에서 다양한 도구 원형(Primitives)과 무작위 목표 자세를 생성하여 학습합니다. 정책(Policy) $\pi_\theta$는 현재 상태 $\bm{s}_t$, 객체 자세 $\bm{o}_t$, 객체 묘사자 $\bm{\phi}$, 목표 자세 $\bm{g}$를 입력받아 관절 액션 $\bm{a}_t$를 출력합니다.
- 시뮬레이션 투 리얼(Sim-to-Real) 전이: 실제 테스트 시 인간의 동영상에서 추출한 도구 궤적을 목표 자체(goal)로 사용하여, 별도의 실제 객체 모델링 없이 학습된 정책을 바로 적용합니다.
핵심 기법
가장 중요한 기법은 **‘절차적 생성(Procedural Generation)‘**입니다. 연구진은 시뮬레이션에서 실제 존재하는 특정 도구만 사용하는 대신, 막대, 손잡이 등 다양한 형태의 도어 원형을 프로그램으로 무작위 생성하여 로봇이 학습합니다. 이를 통해 로봇이 특정 도구의 모양을 외우는 것이 아니라, 어떤 모양이든 잡고 조작하는 ‘일반적인 손 기술(Dexterity)‘을 습득하게 합니다.
📊 정량적 결과
주요 성과
- 성공 기준 정의: 객체 자세와 목표 자세 간의 거리 $d(\bm{o}_t, \bm{g})$가 2cm 이하일 경우 목표 도달로 간주합니다.
- 하드웨어 사양: 7자유도(DoF)의 팔(KUKA iiwa 14)과 22자유도의 5지 손(Sharpa hand)을 결합하여 실험했습니다.
- 평가 방법: 실제 도구와 궤적에 대해 제로샷(Zero-Shot)으로 성공적으로 추적하는지 Task Progress 지표를 통해 측정했습니다.
🚀 기존 대비 개선점
- 범용성: 각 작업이나 도구마다 시뮬레이션 모델을 직접 만들거나 보상 함수를 수동으로 조정할 필요가 없습니다.
- 데이터 효율성: 사람이 직접 로봇을 조작하여 실제 데이터를 수집(텔레오퍼레이션)하는 어려운 과정 없이 시뮬레이션 데이터만으로 실제 성능을 냅니다.
- 운동학적 제한 극복: 기존의 키네마틱 리타겟팅(Kinematic Retargeting)이나 고정된 그립(Fixed-Grasp) 방식보다 더 정교하고 동적인 손가락 움직임이 가능합니다.
🎯 활용 분야
- 가정용 로봇: 청소, 요리 등 다양한 도구를 사용하는 가사 노동 자동화.
- 산업용 로봇: 조립 라인에서 공구를 교체하여 사용하는 복잡한 정밀 작업.
- 서비스 로봇: 사용자가 요청하는 도구를 즉시 사용하여 도움을 주는 상황.
한계 및 주의사항
- 기능적 완수 보장 부족: 제안하는 방법은 도구를 목표 궤적대로 움직이게는 하지만, 예를 들어 ‘망치로 못이 제대로 박혔는지’와 같은 작업의 실질적인 성공(기능적 완수)까지 보장하지는 못합니다.
- 환경 인식 부재(Blind): 객체의 자세(Goal Pose)에만 집중하기 때문에, 주변 환경이나 장애물과의 충돌 등을 고려하지 않는 ‘환경 눈먼(Blind)’ 상태일 수 있습니다.
8. K-Search: LLM Kernel Generation via Co-Evolving Intrinsic World Model
arXiv: 2602.19128 | ⬆️ 4 🤖 GLM추천 | 📄 HTML 태그:
llmkernel-optimizationgpuworld-modelautomated-searchevolutionary-algorithmsdeepseek-v3flashinfer사전 지식: 이 부족한 완전히 새로운 도메인에 대한 적용은 추가 연구가 필요해 보입니다.

한 줄 요약
이 논문은 거대 언어 모델(LLM)을 단순한 코드 생성 도구가 아닌 성능 최적화를 계획하는 ‘세계 모델(World Model)‘로 활용하여, GPU 커널 최적화 작업에서 기존 진화적 방법론보다 훨씬 더 뛰어난 효율과 성능을 달성했기에 중요합니다.
💡 핵심 아이디어
기존 방식이 마치 지도 없이 맹목로 길을 찾는 여행자처럼 무작위로 코드를 수정하고 테스트했다면, 이번 방법론은 매번 걸을 때마다 지형을 기억하고 분석하여 다음 최적 경로를 예측하는 내비게이션을 장착한 것과 같습니다. 즉, LLM이 실제 코드를 짜면서도 동시에 이 코드가 성능에 어떤 영향을 줄지 추론하는 ‘내적 세계 모델’을 형성하여, 시행착오를 줄이고 더 똑똑하게 탐색합니다.
문제 정의
GPU 커널 최적화는 설계 공간이 넓고 하드웨어 변화가 빨라 자동화가 어렵습니다. 특히 기존 LLM 기반 자동화 방식들은 복잡한 구조적 변화가 필요한 문제에서 명시적인 계획 능력이 부족하여, 좋은 전략임에도 불구하고 중간 단계의 구현 실수로 인해 유망한 방향을 버리는 문제가 있었습니다.
🔬 방법론 상세
- 공진화 세계 모델(Co-Evolving World Model): 정적인 탐색 휴리스틱(경험적 법칙) 대신, 환경과 상호작용하며 지속적으로 업데이트되는 세계 모델을 도입했습니다. 이 모델은 탐색 상태(Search State, $S_t$)를 기반으로 특정 행동(Action, $a$)의 우선순위 점수(Priority Score, $V(a \mid S_t)$)를 추정합니다.
- 목적 함수 최적화: 커널 프로그램 $x$에 대한 목적 함수 $J(x)$를 정의하여 참조 솔루션 대비 속도 향상폭을 최대화하는 방향으로 탐색합니다. 수식은 $J(x) = s \cdot \frac{p_{\text{ref}}}{p} \cdot 100$으로, 여기서 $s$는 정확성, $p$는 지연 시간(Latency)입니다.
- 검색 공간 추론: LLM은 단순히 코드를 생성하는 것을 넘어, 탐색 공간 전체를 추론하고 전략의 유효성을 구현 노이즈(Implementation Noise)와 분리하여 판단합니다.
핵심 기법
이 논문의 가장 큰 핵심은 LLM이 단순한 코드 생성기가 아니라 ‘잠재적인 계획 능력(Latent Planning Capabilities)‘을 가진 세계 모델이라는 점을 입증한 것입니다. 쉽게 말해, 코드가 작동하는지를 검사하기 전에 “이 방식이면 성능이 좋을 것 같다”라고 머릿속으로 시뮬레이션해보고, 그 가능성이 높은 방향으로 집중 투자하는 능력을 LLM에게 부여한 것입니다.
📊 정량적 결과
주요 성과
- 평균 2.1배 향상: 다양하고 복잡한 커널에서 기존 최신 진화적 기법(Baseline) 대비 평균 2.1배의 개선 효과를 보였습니다.
- MoE 최대 14.3배 향상: 혼합 전문가(MoE, Mixture of Experts) 커널 최적화 작업에서는 최대 14.3배의 성능 향상을 달성했습니다.
- 대회 수상: GPUMODE TriMul 경쟁에서 최신 성능(SoTA)을 기록하며 그 우수성을 입증했습니다.
🚀 기존 대비 개선점
- 계획 능력 부재로 인한 무작위 탐색을 지능적인 탐색으로 대체했습니다.
- 중간 구현의 실수로 인해 좋은 최적화 전략을 폐기하던 문제를 해결했습니다.
- 하드웨어 아키텍처(예: NVIDIA Hopper에서 Blackwell으로의 전환) 변화에 유연하게 대응할 수 있는 적응력을 보였습니다.
🎯 활용 분야
- 초대규모 언어 모델(LLM) 서빙 속도를 높이기 위한 커널 자동 최적화 (예: FlashInfer, FlashAttention)
- 새로운 GPU 하드웨어(예: NVIDIA Blackwell)에 맞춘 고성능 커널 자동 생성
- 메모리 대역폭이나 계산 병목이 심한 복잡한 연산(예: FP8 MoE, GQA) 최적화
한계 및 주의사항
제공된 텍스트에서는 명시적인 한계점을 언급하지 않으나, ‘엄격하게 제한된 테스트 예산(Strictly Limited Testing Budget)’ 환경을 전제로 하고 있으므로, 계산 비용이 매우 큰 대규모 탐색에서의 확장성 검증이 추가로 필요할 수 있습니다. 또한 LLM 자체의 추론 능력에 의존하므로, 모델의 사전 지식이 부족한 완전히 새로운 도메인에 대한 적용은 추가 연구가 필요해 보입니다.
9. Decoding ML Decision: An Agentic Reasoning Framework for Large-Scale Ranking System
arXiv: 2602.18640 | 기관: AI at Meta | ⬆️ 1 🤖 GLM추천 | 📄 HTML 태그:
recommender-systemsllm-agentcausal-inferencemulti-objective-optimizationmlopsautomated-mlranking-algorithm사전 지식: Uplift Modeling (인과추론 기반 개인화 모델링), Large Language Model Agent (LLM을 이용한 자율 추론 시스템), Multi-objective Optimization (다목적 최적화), A/B Testing (가설 검증 실험), Ranking Systems (순위 매기기 시스템)
한 줄 요약
이 논문은 대규모 순위 시스템의 최적화 작업을 단순한 모델 선택에서 전문가의 지식을 통합한 자율적인 에이전트(Agent) 발견 과정으로 재정의하여, 복잡한 제약 조건과 비즈니스 목표를 자동으로 충족하는 생산 가능한 정책을 찾아내는 획기적인 프레임워크 GEARS를 제시했기에 중요합니다.
💡 핵심 아이디어
기존의 추천 시스템 최적화가 마치 수십 개의 다이얼을 감각에 의존해 수동으로 조절하는 것과 같다면, GEARS는 요리사의 의도를 이해하고 안전 규정을 준수하면서 스스로 최적의 레시피를 찾아내는 자율 주행 주방 로봇과 같습니다. 단순히 통계적 수치만 좋은 정책을 찾는 것이 아니라, 실제 현장에서 적용 가능한지 안전한지를 판단하며 제품 의도를 실행 가능한 정책으로 자동 변환하는 자율 발견 루프를 핵심으로 합니다.
문제 정의
현대의 대규모 순위 시스템(Ranking System)은 서로 충돌하는 다양한 목표와 복잡한 제약 조건 속에서 운영됩니다. 하지만 현재 산업계의 주된 병목 현상은 모델링 기술 자체가 아니라, 모호한 제품 의도를 검증 가능한 가설로 변환하고 수동으로 최적화하는 ‘엔지니어링 맥락 제약(Engineering Context Constraint)‘에 있습니다. 기존의 정적 모델링 방식(예: Uplift Modeling)은 운영 제약이나 데이터 불안정성을 간과하여, 통계적으로는 좋지만 실제로는 적용 불가능한 취약한 정책을 제안하는 문제가 있습니다.
🔬 방법론 상세
- GEARS (Generative Engine for Agentic Ranking Systems) 프레임워크: 최적화를 일회성 추론 문제가 아닌 프로그래밍 가능한 실험 환경 내에서의 자율적인 발견 루프(Autonomous Discovery Loop)로 재정의합니다.
- Vibe-Driven Personalization (바이브 기반 개인화): 인간의 의도와 같은 질적인 목표(Vibes)를 수치적인 최적화 목표로 변환하여 의미적 격차(Semantic Gap)를 해소합니다.
- Specialized Agent Skills (특화된 에이전트 스킬): 순위 최적화 전문가의 지식을 재사용 가능한 추론 능력으로 캡슐화하여, 에이전트가 장기적인 추론 과정에서 맥락 부재(Context Rot) 문제를 겪지 않도록 합니다.
- Deterministic Lifecycle Governance (결정론적 수명 주기 거버넌스): 순수 통계적 방법이 승인할 수 있는 위험도가 높은 정책을 필터링하여, 엄격한 프로덕션 안전 기준을 준수하는 정책만을 선택하도록 강제합니다.
핵심 기법
가장 중요한 기법은 Specialized Agent Skills의 활용입니다. 일반적인 LLM(Large Language Model)에 모든 것을 묻는 대신, ‘Pareto 최적해 찾기’, ‘제약 조건 검증’ 등의 전문 지식을 별도의 스킬로 만들어 에이전트에게 장착합니다. 이는 마치 숙련된 엔지니어가 가진 툴킷을 AI에게 그대로 물려주는 것과 같아서, AI가 단순히 텍스트를 생성하는 것을 넘어 엔지니어링적으로 타당한 결정을 내릴 수 있게 해줍니다.
📊 정량적 결과
주요 성과
- 데이터셋 구축: 20개의 내부 실험을 바탕으로 수백 개의 정책 후보와 측정 지표를 포함한 벤치마크 데이터셋을 구축했습니다.
- 다양한 지침 평가: 실험당 5가지 유형의 지침(예: 두 지표 최대화, 제약 조건 하 최적화, 효율성 최적화 등)을 자동 생성하여 총 100개의 지침(20개 실험 × 5개 유형)을 통해 실제 성능을 평가했습니다.
- 실제 배포 검증: 복잡하고 비볼록한(Non-convex) 최적화 환경에서 실제 프로덕션 레벨의 구성을 성공적으로 출력하며, 기존 Uplift Modeling 방식의 취약성을 극복함을 실증했습니다.
🚀 기존 대비 개선점
- 자동화된 발견 과정: 수작업에 의존하던 정책 탐색과 가설 검증 과정을 자율적인 루프로 자동화하여 확장성 문제를 해결했습니다.
- 운영 제약 반영: 통계적 유의성만을 보는 기존 방식과 달리, 인프라 제약이나 비즈니스 규칙 등 운영 가능성을 고려한 견고한 정책을 제안합니다.
- 장기 추론 안정성: 전문가 지식을 스킬로 캡슐화하여 에이전트가 긴 추론 과정에서 맥락을 잃어버리거나 환각(Hallucination)에 빠지는 문제를 완화했습니다.
🎯 활용 분야
- 대규모 추천 시스템: 디스커버리 중심의 콘텐츠 추천 및 커머스 상품 순위 결정.
- 소셜 미디어 피드: 커뮤니티 주도의 인터페이스에서 다양한 사용자 선호와 충돌하는 지표(예: 참여도 vs 시간)를 균형 있게 조절.
- 광고 및 검색 엔진: 다양한 비즈니스 목표(클릭률, 수익성 등)와 엄격한 운영 제약 조건이 공존하는 복잡한 환경의 입찰 및 순위 최적화.
한계 및 주의사항
- 초기 스킬 정의 비용: Specialized Agent Skills를 구축하려면 해당 도메인에 대한 높은 수준의 전문 지식이 필요하며, 이를 초기에 캡슐화하는 작업이 추가로 필요합니다.
-
- 계산 복잡성: 단순한 모델 추론에 비해 자율적인 발견 루프와 거버넌스 검증 과정을 거치므로 시스템 전체의 연산 비용이나 대기 시간이 증가할 수 있습니다.
10. Large Causal Models for Temporal Causal Discovery
arXiv: 2602.18662 🤖 GLM추천 | 📄 HTML 태그:
large-causal-modelstemporal-causal-discoverytime-seriestransformerzero-shot-learningdeep-learning사전 지식: 인과 발견(Causal Discovery), 시계열 분석(Time-Series Analysis), 트랜스포머(Transformer), 제로샷 학습(Zero-shot Learning), 인과 그래프(Causal Graph)

한 줄 요약
개별 데이터셋마다 모델을 새로 학습하던 기존 인과 발견 패러다임을 깨고, 다양한 데이터로 사전 학습된 대규모 인과 모델(LCM)을 통해 본 적 없는 이종 시계열 데이터에도 제로샷(Zero-shot)으로 인과 구조를 추론할 수 있는 길을 열었기 때문입니다.
💡 핵심 아이디어
각각의 범죄 사건(데이터셋)이 발생할 때마다 탐정을 처음부터 양성하는 대신, 수만 건의 사건 파일을 학습한 베테랑 탐정(사전 학습된 모델)을 투입하여 어떤 유형의 사건이든 즉시 범인(인과 관계)을 추론하도록 만드는 것입니다. 다양한 가상의 연습문제(합성 데이터)와 실제 사건(현실 데이터)을 섞어서 학습시켜, 실제 현장에서도 적응력을 발휘하도록 만드는 전략을 사용합니다.
문제 정의
시계열 인과 발견(Temporal Causal Discovery) 분야에서 기존 방법들은 데이터셋마다 모델을 새로 맞춰야 하고, 변수 수가 늘어나면 계산 복잡도가 급증하여 성능이 저하되는 문제가 있었습니다. 또한 대부분 가성 데이터(Synthetic Data)에 의존하다 보니 실제 환경(Realistic benchmarks)에서는 일반화가 잘 되지 않는다는 근본적인 한계를 해결하고자 했습니다.
🔬 방법론 상세
- 다양한 데이터 생성기 통합 학습: 단순한 합성 데이터뿐만 아니라 다양한 TSCM(Time-Series Causal Model, 시계열 인과 모델) 생성기와 실제 시계열 데이터셋을 결합하여 대규모 학습 파이프라인을 구축했습니다.
- Convolution-Enhanced Transformer 아키텍처: Conv1D 레이어를 통해 입력 데이터의 지역적 시간 특징을 추출하고, 위치 인코딩(Positional encoding)을 더한 뒤 트랜스포머 인코더 스택(Transformer encoder stack)을 통과시켜 맥락화된 표현(Contextualized representations)을 얻습니다.
- 시차 교차 상관(Lagged Cross-correlations) 주입: 모델의 성능을 높이기 위해 인코더의 최종 표현에 시차 교차 상관 계수를 연결(Correlation injection)하여, 모델이 통계적 의존성을 더 잘 파악하도록 유도했습니다.
- 시차 인접 텐서(Lagged Adjacency Tensor) 예측: 시그모이드(Sigmoid) 활성화 함수를 거친 출력 헤드를 통해, 시간의 흐름에 따른 변수 간의 인과 강도를 확률 값($[0, 1]$)으로 출력합니다.
핵심 기법
이 논문의 가장 독창적인 부분은 ‘상관관계 주입(Correlation Injection)‘입니다. 신경망이 처음부터 인과 관계를 완벽히 학습하기 어렵다는 점을 보완하기 위해, 전통적인 통계 기법인 ‘시차 교차 상관’ 값을 모델 학습 과정에 힌트로 제공합니다. 이는 마치 어려운 문제를 풀 때 요약본을 옆에 두고 푸는 것과 같아서, 모델이 더 정확하게 인과 구조를 파악하도록 돕는 강력한 귀납적 편향(Inductive bias) 역할을 합니다.
📊 정량적 결과
주요 성과
- 합성(Synthetic), 반합성(Semi-synthetic), 현실적(Realistic) 벤치마크를 포함한 광범위한 실험에서 LCM이 기존 방법론 대비 효과적으로 확장(Scale effectively)되며 성능을 입증했습니다.
- 특히 Zero-shot(제로샷) 설정, 즉 학습에 사용되지 않은 완전히 새로운 시스템의 데이터에 대해서도 기존 데이터셋 특화 모델들보다 뛰어난 일반화 성능을 보였습니다. (구체적인 수치는 원문의 Table 1 등 참조 필요)
🚀 기존 대비 개선점
- 일반화성: 특정 데이터셋에 과최적화(Overfitting)되지 않고, 이질적인 시스템(Heterogeneous systems)에도 적용 가능한 범용 모델을 구현했습니다.
- 확장성: 입력 변수(Variable)의 개수나 시계열의 길이가 증가해도 성능 저하가 적도록 설계하여 기존 방법의 계산 복잡도 문제를 완화했습니다.
- 효율성: 새로운 데이터가 들어와도 추가 학습(Fine-tuning) 없이 즉시 추론(Inference)이 가능하여 시간과 비용을 절약합니다.
🎯 활용 분야
- 금융 시장 분석: 수백 개의 경제 지표 간의 복잡한 인과 네트워크를 실시간으로 파악하여 리스크 요인을 조기에 발견할 수 있습니다.
- 바이오 헬스케어: 유전자 발현 시계열이나 환자의 생체 신호 데이터로부터 질병의 진행 경로를 파악하여 정밀 의료의 기반을 마련할 수 있습니다.
- 산업 제어 시스템: 센서 네트워크 데이터에서 이상 징후의 원인을 즉각적으로 찾아내어 공정 자동화 및 예지 보전에 활용할 수 있습니다.
한계 및 주의사항
- 모델의 성능이 사전 학습에 사용된 합성 데이터 생성기의 질과 다양성에 크게 의존하므로, 학습 데이터가 실제 세상의 다양성을 충분히 반영하지 못하면 실제 적용 시 성능이 떨어질 수 있습니다.
- 제로샷 추론 성능이 뛰어나지만, 특정 도메인에 매우 특화된 미세한 인과 관계까지 파악하려면 소량의 실제 데이터를 이용한 미세 조정(Fine-tuning)이 여전히 필요할 수 있습니다.
📅 생성일: 2026-02-24 | 🤖 GLM-4.7