📚 2026-02-18 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 Sanity Checks for Sparse Autoencoders: Do SAE… ⬆️51
- 📊📄 SkillsBench: Benchmarking How Well Agent Skil… ⬆️36
- 📊📄 GLM-5: from Vibe Coding to Agentic Engineerin… ⬆️30
- 📊📄 Does Socialization Emerge in AI Agent Society… ⬆️21
- 📊📄 ResearchGym: Evaluating Language Model Agents… ⬆️14
- 🤖📄 UniT: Unified Multimodal Chain-of-Thought Tes… ⬆️13
- 🤖📄 Understanding vs. Generation: Navigating Opti… ⬆️5
- 🤖📄 On Surprising Effectiveness of Masking Update… ⬆️5
- 🤖📄 Panini: Continual Learning in Token Space via… ⬆️4
- 🤖📄 The Vision Wormhole: Latent-Space Communicati… ⬆️1
1. Sanity Checks for Sparse Autoencoders: Do SAEs Beat Random Baselines?
arXiv: 2602.14111 | ⬆️ 51 📊 순위선정 | 📄 HTML 태그:
interpretabilitysparse-autoencodersllmsanity-checkmechanistic-interpretabilityevaluationmachine-learningai-safety사전 지식: Sparse Autoencoders (SAE), Superposition Hypothesis (중첩 가설), Explained Variance (설명된 분산), Ground-truth Features (실제 정답 특징), Overcomplete Dictionary (과대완비 사전)

한 줄 요약
희소 자동 인코더(SAE)가 대규모 언어 모델의 내부를 해석한다고 믿어왔던 통념을 깨고, 학습된 SAE가 랜덤하게 초기화된 모델과 큰 차이가 없으며 실제 특징 복원 능력은 매우 낮다는 사실을 밝혀 기존 해석 방법론의 신뢰성을 재검토하게 만든 중요한 연구입니다.
💡 핵심 아이디어
희소 자동 인코더(SAE)는 마치 외국어 번역기처럼 모델의 내부 신호를 인간이 이해할 수 있는 언어로 바꿔준다고 믿어왔습니다. 하지만 이 논문은 번역기가 문장을 매끄럽게 재구성은 하지만 실제로는 단어의 뜻을 전혀 모르고 글자만 나열하는 것과 같다는 지적입니다. 즉, SAE가 높은 성능 지표를 보이더라도 실제로는 의미 있는 특징을 찾은 게 아니라 랜덤한 찌꺼기만 학습했을 수 있다는 ‘정신 검사(Sanity Check)‘를 수행했습니다.
문제 정의
희소 자동 인코더(SAE)는 모델의 활성화(Activation)를 해석 가능한 특징으로 분해한다고 알려져 있어 안전성과 추론 과정을 이해하는 데 널리 쓰여왔습니다. 그러나 최근 연구에서 재구성 정확도가 높아도 실제 작업에서는 성능이 좋지 않다는 부정적인 결과가 나오면서, SAE가 과연 진짜 특징을 학습하는지, 아니면 단순히 데이터의 통계적 패턴을 암기하는 것인지에 대한 의문이 제기되었습니다.
🔬 방법론 상세
- 합성 데이터(Toy Model) 실험: 진짜 정답(ground-truth features)을 알고 있는 인공 데이터를 생성하여 SAE가 이를 얼마나 정확히 찾아내는지 측정했습니다. 이때 실제 환경과 비슷하도록 사전 크기를 활성화 차원보다 32배 크게 설정하는 과대완비(Overcomplete) 상황을模拟했습니다.
- 랜덤 기반선(Frozen Baselines) 설정: 실제 LLM 데이터를 대상으로 SAE의 주요 구성 요소를 무작위로 초기화한 뒤 학습过程中에 전혀 업데이트하지 않도록 고정(Frozen)한 세 가지 모델을 만들었습니다. 여기에는 랜덤 디코더, 부분 고정 디코더, 랜덤 인코더가 포함됩니다.
- 널 가지 지표 비교: 완전히 학습된 SAE와 고정된 랜덤 모델을 재구성 충실도, 잠재 해석 가능성, 희소 프로빙, 인과적 편집 등의 지표로 비교하여 학습의 효과를 검증했습니다.
핵심 기법
이 논문의 가장 강력한 무기는 얼어붙은 디코더(Frozen Decoder) 기법입니다. 디코더는 모델이 압축된 데이터를 다시 원래대로 복원하는 부분인데, 연구진은 이 디코더의 가중치를 아무렇게나 설정해두고 절대 바꾸지 않았습니다. 만약 이게 고장 난 장난감 같은 모델이 열심히 훈련된 모델과 비슷한 성능을 낸다면, 우리가 훈련된 모델에게서 보던 ‘뛰어난 성능’이 사실은 모델의 지능 때문이 아니라 데이터 자체가 가진 단순한 패턴 때문일 수 있다는 뜻이 됩니다.
📊 정량적 결과
주요 성과
- 합성 데이터 실험에서 SAE는 설명된 분산(Explained Variance)이 71%에 달해 재구성 능력은 뛰어났지만, 실제 진짜 특징을 성공적으로 복원한 비율은 고작 9%에 그쳤습니다.
- 실제 LLM 활성화 데이터에서는 학습되지 않은 랜덤 고정 모델들이 최신 SAE 기법들(BatchTopK, JumpReLU 등)과 비교해 해석 가능성, 희소 프로빙, 인과적 편집 등 핵심 평가 지표에서 거의 대등한 성능을 기록했습니다.
🚀 기존 대비 개선점
- 기존 연구들이 단순히 재구성 오류(Reconstruction Error)가 낮다는 이유만으로 SAE가 성공했다고 단정 짓던 관행을 깨고, 실제 특징 회수율이라는 더 엄격한 기준을 제시했습니다.
- 완전히 학습된 모델만 보는 것이 아니라, 학습이 전혀 이루어지지 않은 랜덤 모델과 비교하는 영(Zero) 기반 테스트를 도입하여 SAE의 유효성을 검증하는 새로운 평가 패러다임을 제시했습니다.
🎯 활용 분야
- LLM 안전성 연구: 모델 내부의 위험한 사고_chain이나 안전 장치를 분석할 때 기존 SAE의 결과가 신뢰할 수 있는지 판단하는 중요한 참고 자료로 활용됩니다.
- 해석 가능성 도구 개선: SAE의 구조적 한계를 파악하여, 진짜 특징을 더 정확하게 잡아내는 다음 세대의 디코딩 알고리즘을 설계하는 데 필요한 데이터를 제공합니다.
한계 및 주의사항
- SAE가 완전히 쓸모없다는 결론은 아닙니다. 랜덤 기반선보다 여전히 성능이 좋기는 하지만, 기존에 우리가 믿었던 것만큼 ‘강력하거나 완벽하지 않다’는 점을 강조한 것입니다.
- 현재의 평가 지표들(해석 가능성 점수 등)조차도 완벽하지 않을 수 있으므로, SAE가 실제로 무엇을 학습했는지 판단하는 더 나은 방법이 추가로 필요합니다.
2. SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
arXiv: 2602.12670 | 기관: BenchFlow | ⬆️ 36 | ⭐ 413 📊 순위선정 | 📄 HTML 태그:
llm-agentagent-skillsbenchmarkingprocedural-knowledgemodel-evaluationprompt-engineeringhuman-in-the-loop사전 지식: LLM(Large Language Model), AI Agent(에이전트), Procedural Knowledge(절차적 지식), Inference(추론), Temperature(온도, 모델의 답변 다양성을 조절하는 파라미터)

한 줄 요약
에이전트 스킬(Agent Skills)의 효과를 처음으로 체계적으로 측정하는 벤치마크(SkillsBench)를 제시하여, 인간이 정제한 절차적 지식이 에이전트 성능을 크게 높이지만 모델이 스스로 만든 지식은 효과가 없음을 입증했습니다.
💡 핵심 아이디어
LLM 에이전트를 ‘능숙하지만 회사 규칙을 모르는 신입 사원’으로, Agent Skills를 ‘직원용 매뉴얼’이나 ‘전용 도구 상자’에 비유할 수 있습니다. 아무리 똑똑한 사원이라도 업무 절차서가 없으면 헤매지만, 잘 만들어진 매뉴얼을 쥐어주면 전문가처럼 일 처리 능력이 비약적으로 상승합니다.
문제 정의
기초 모델(Foundational Models)은 방대한 지식을 갖추고 있지만, 특정 도메인의 복잡한 작업 절차(Procedural Knowledge)가 부족하여 실무 환경에서 오류가 잦다는 문제를 해결합니다. 또한, 모델을 수정하는 파인 튜닝(Fine-tuning)은 비용이 비싸고 일반성을 잃기 때문에, 추론 시점(Inference time)에 지식을 주입하는 방식의 효과를 검증할 필요가 있었습니다.
🔬 방법론 상세
- SkillsBench 구축: 11개 도메인에 걸친 86개의 실무적 작업(Task)을 정의하고, 각 작업에 대해 인간이 수동으로 작성하고 검증한 스킬(Curated Skills)과 결정론적 검증기(Deterministic Verifiers)를 짝지어 벤치마크 데이터셋을 구축했습니다.
- 세 가지 조건 비교 실험: 각 작업에 대해 (1) 스킬 없이 수행(No Skills), (2) 인간이 작성한 스킬 제공(With Skills), (3) 스킬 없이 모델이 스스로 스킬을 생성하게 한 후 수행(Self-Generated Skills) 조건에서의 성능을 비교하여 스킬의 순수 효과를 분리했습니다.
- 다양한 모델 및 하니스 평가: 3가지 상용 에이전트 하니스(Agent Harness, 모델과 사용자 사이의 인터페이스)인 Claude Code, Codex CLI, Gemini CLI와 7개의 최신 모델(GPT-5.2, Claude Opus 4.5/4.6 등)을 조합하여 총 7,308개의 시행(Trajectory)을 분석했습니다.
핵심 기법
가장 중요한 기법은 스킬(Skill)의 구조화 및 모듈화입니다. 단순히 텍스트로 된 설명만 주는 것이 아니라, 지침(Instructions), 코드 템플릿(Code Templates), 자원(Resources), 검증 로직(Verification Logic)을 포함한 패키지 형태로 지식을 제공했습니다. 이는 에이전트가 단순히 텍스트을 읽는 것을 넘어 실제 실행 가능한 절차를 따르도록 유도하는 핵심 메커니즘입니다.
📊 정량적 결과
주요 성과
- 인간이 정제한 스킬(Curated Skills)을 사용했을 때 평균 통과율(Pass Rate)이 24.3%에서 40.6%로 16.2%포인트 상승했습니다.
- 도메인별 효과 차이가 극명하여, 소프트웨어 엔지니어링은 +4.5%포인트에 그친 반면 헬스케어 분야는 +51.9%포인트의 큰 폭의 개선을 보였습니다.
- 모델이 스스로 생성한 스킬(Self-Generated Skills)은 평균 -1.3%포인트의 효과를 보여, 현재 모델 수준에서는 스스로 유용한 절차적 지식을 작성하는 것이 불가능하거나 오히려 독이 됨을 입증했습니다.
🚀 기존 대비 개선점
- 인간의 전문 지식이 담긴 스킬을 제공하면 모델의 추론 능력을 특정 도메인에서 크게 향상시킬 수 있습니다.
- 방대한 문서보다는 핵심적인 2~3개의 모듈로 구성된 간결하고 집중된 스킬(Focused Skills)이 성능 향상에 더 효과적입니다.
- 스킬은 모델의 크기(Scale)를 일부 보상할 수 있어, 큰 모델 대신 적절한 스킬을 장착한 작은 모델을 사용하여 비용을 절감할 수 있습니다.
🎯 활용 분야
- 소프트웨어 개발 보조 도구 개발(CLI, 코딩 에이전트 등)
- 전문 분야(의료, 금융, 법률 등)의 특화된 AI 에이전트 구축
- 기업 내부 자동화 워크플로우 설계 및 절차 지식 시스템화
한계 및 주의사항
- 모든 작업에서 스킬이 긍정적인 효과를 보이는 것은 아니며, 84개 작업 중 16개에서 스킬 사용이 오히려 성능을 떨어뜨리는 부작용이 발생했습니다.
- 현재의 LLM은 스스로 효과적인 절차적 지식을 생성하지 못하므로, 반드시 인간 전문가의 개입(Human-in-the-loop)이 필요합니다.
3. GLM-5: from Vibe Coding to Agentic Engineering
arXiv: 2602.15763 | ⬆️ 30 | ⭐ 1103 📊 순위선정 | 📄 HTML 태그:
llmglm-5agentic-aiasynchronous-rlreinforcement-learningsoftware-engineeringlong-contextefficiency사전 지식: Reinforcement Learning from Human Feedback (RLHF), Model-of-Experts (MoE), Supervised Fine-Tuning (SFT), Agentic AI, Long-context Modeling
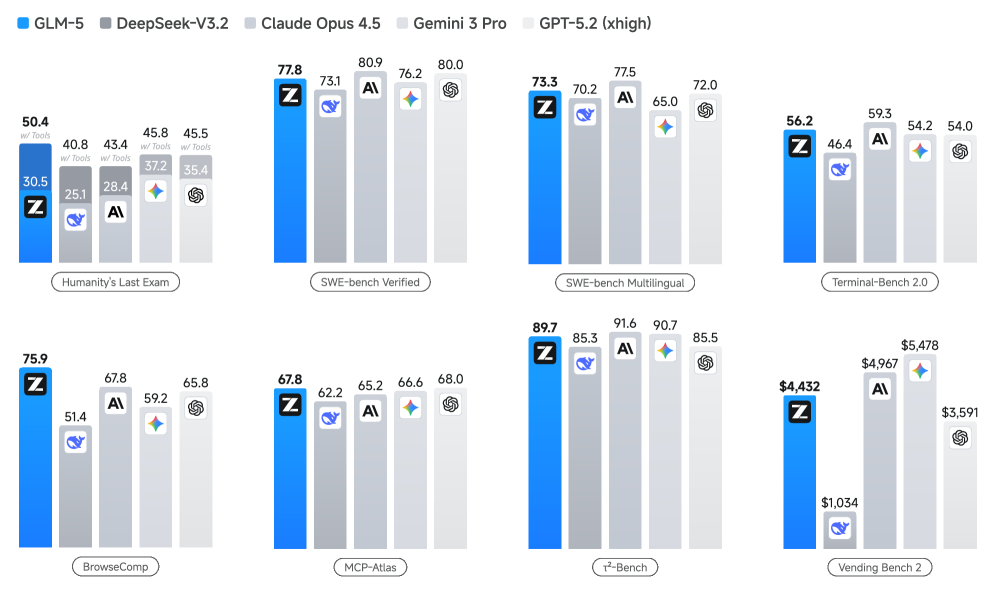
한 줄 요약
GLM-5는 단순한 프롬프트 응답을 넘어 인공지능이 스스로 계획하고 실행하는 ‘에이전트 엔지니어링’ 시대를 열었으며, 비동기 강화학습 인프라를 통해 훈련 효율성을 획기적으로 높여 실제 소프트웨어 개발 수행 능력을 최고 수준으로 끌어올렸기 때문에 중요합니다.
💡 핵심 아이디어
기존의 사람이 주도하여 AI에게 코드를 짜게 하는 ‘바이브 코딩(Vibe Coding)’ 방식에서, AI가 스스로 계획하고 구현하며 수정하는 ‘에이전트 엔지니어링(Agentic Engineering)‘으로 패러다임을 전환한 것입니다. 마치 운전 기사에게만 의존하던 것에서, 스스로 운전하고 경로를 찾는 자율주행 자동차로 업그레이드하는 과정과 비슷하며, 이때 비동기 강화학습(Asynchronous RL)이라는 기술을 적용하여 학습과 실행이 동시에 일어나도록 하여 대기 시간을 없앴습니다.
문제 정의
이 논문은 대규모 언어 모델이 단순한 지식 저장소에서 능동적인 문제 해결사로 전환하는 과정에서 발생하는 ‘계산 비용(Computational Cost)‘과 ‘실제 환경 적응력(Real-world adaptability)‘이라는 두 가지 주요 병목 현상을 해결하는 것을 목표로 합니다. 특히 정적인 벤치마크를 넘어 복잡한 실제 소프트웨어 공학 문제를 해결하기 위한 자율성과 효율성을 확보하는 것이 핵심 과제입니다.
🔬 방법론 상세
- 비동기 강화학습 인프라(Asynchronous RL Infrastructure): 모델 생성(Generation) 단계와 훈련(Training) 단계를 분리하여 비동기적으로 처리함으로써, 에이전트가 긴 과정을 수행할 때 발생하는 GPU 유휴 시간을 줄여 효율성을 극대화했습니다.
- 점진적 정렬 전략(Progressive Alignment Strategy): 멀티태스크 지도 학습(SFT)으로 시작하여, 추론 및 에이전트 작업을 위한 특화된 강화학습(RL) 단계를 거치고, 마지막으로 인간 스타일 정렬을 위한 일반 RL 단계를 수행합니다. 마지막에는 On-policy Cross-stage Distillation을 사용하여 각 단계의 성능 향상을 유지하면서 능력 저하(Capability Regression)를 방지합니다.
- 그룹 와이즈 정책 최적화(Group-wise Policy Optimization): 에이전트의 롤아웃(Rollout)에서 샘플링된 궤적(Traces)들을 그룹 단위로 최적화하며, 손실 함수 L(θ)은 각 문제에 대해 샘플링된 K개의 궤적에 대한 보상의 평균을 기준 보상(Reward Baseline)과 비교하여 정책을 업데이트합니다. (수식: L(θ)=E…[1/K Σ(r(x,yi) - r¯(x))])
핵심 기법
가장 중요한 방법론은 **비동기 강화학습(Asynchronous RL)**입니다. 쉽게 말해 요리사(AI)가 요리를 만드는 동안 주방장(Training Process)이 기다리지 않고 바로 다음 요리사의 기술을 평가하고 피드백을 줄 수 있는 시스템을 만든 것입니다. 이를 통해 에이전트가 복잡하고 긴 작업을 수행하는 동안에도 학습 과정이 멈추지 않고 계속 돌아가게 하여 자원을 낭비 없이 쓸 수 있습니다.
📊 정량적 결과
주요 성과
- 최대 202,752 토큰의 긴 컨텍스트(Context)를 지원하며, 이를 통해 장기간의 상호작용 처리가 가능해졌습니다.
- 실제 소프트웨어 공학 문제를 위해 10,000개 이상의 검증 가능한 훈련 시나리오(Verifiable Training Scenarios)를 구축하여 환경을 확장했습니다.
- ArtificialAnalysis.ai, LMArena Text, LMArena Code 등 주요 오픈 리더보드에서 최첨단(State-of-the-art) 성능을 기록했습니다.
🚀 기존 대비 개선점
- 계산 효율성 극대화: DSA를 채택하여 긴 컨텍스트의 정확도를 유지하면서도 훈련 및 추론 비용을 획기적으로 절감했습니다.
- 실무 코딩 능력 고도화: 단순 코드 생성을 넘어 프런트엔드 및 백엔드 엔지니어링, 도구 호출(Tool Calling) 등을 포함한 종단 간(End-to-end) 소프트웨어 개발이 가능해졌습니다.
- 장기적 상호작용 학습: 비동기 에이전트 RL 알고리즘을 통해 복잡하고 장기적인(Long-horizon) 상호작용에서 훨씬 효과적으로 학습할 수 있게 되었습니다.
🎯 활용 분야
- 자율 소프트웨어 개발 시스템: 사람의 개입 없이 요구사항을 분석하고 코드를 작성 및 배치하는 자동화된 개발 에이전트 구축.
- 복잡한 검색 및 추론 에이전트: 멀티스텝 추론이 필요한 복잡한 질문이나 연구 과제를 자동으로 수행하는 지능형 비서.
- 긴 문맥이 필요한 애플리케이션: 대규모 코드베이스 분석이나 긴 문서의 요약 및 번역 등 장기 기억력이 필수적인 작업.
한계 및 주의사항
- 환경 구축의 복잡성: 에이전트 훈련을 위해 10,000개 이상의 실제 소프트웨어 이슈와 검증 가능한 시나리오를 만드는 파이프라인 구축이 필요하므로 초기 설정 비용과 복잡도가 높습니다.
- 능력 저하(Capability Regression) 관리: 여러 단계의 훈련(SFT → Specialized RL → General RL)을 거치는 동안 이전 단계에서 습득한 능력이 퇴보하지 않도록 Cross-stage Distillation 같은 세심한 관리가 필요합니다.
4. Does Socialization Emerge in AI Agent Society? A Case Study of Moltbook
arXiv: 2602.14299 | 기관: Tianyi Lab | ⬆️ 21 | ⭐ 7 📊 순위선정 | 📄 HTML 태그:
ai-agentsemergencemoltbooksocial-dynamicscomputational-social-sciencellmcollective-intelligencesemantic-analysis사전 지식: Large Language Model (LLM), Multi-Agent System (MAS), Computational Social Science (계산 사회학), Semantic Analysis (의미론적 분석), Network Theory (네트워크 이론)

한 줄 요약
260만 개의 자율 에이전트가 참여하는史上 최대 규모의 AI 전용 사회인 몰트북(Moltbook)을 분석하여, AI 사회가 인간처럼 ‘사회화’ 과정을 거쳐 수렴하는 것이 아니라 규모는 커지되 개별성은 유지되는 독특한 ‘동적 평형’ 상태에 도달한다는 사실을 처음으로 규명한 연구입니다.
💡 핵심 아이디어
로봇들만 사는 거대한 가상 도시를 지어두고 관찰하는 상황을 상상해 보세요. 우리는 인간과 마찬가지로 이 로봇들도 시간이 지나면서 서로 영향을 받아 똑같은 말을 하고 비슷한 규칙을 따르는 하나의 문화(사회화)를 형성할지 궁금해했습니다. 하지만 이 연구는 로봇 사회가 거대해질수록 오히려 서로 다른 의견과 어휘를 끊임없이 생성하면서, 전체적으로는 안정되지만 개별적으로는 섞이지 않는 ‘정체되지 않는 혼란’ 같은 상태에 머문다는 것을 발견했습니다.
문제 정의
대규모 언어 모델(Large Language Model)을 기반으로 한 AI 에이전트들이 인터넷과 같은 네트워크 환경에서 대규모로 상호작용할 때, 이들이 인간 사회처럼 지속적인 상호작용을 통해 사회적 규범을 내면화하고 공동체 구조를 형성하는 ‘사회화(Socialization)’ 현상을 겪는지를 규명하는 문제입니다.
🔬 방법론 상세
- 정량적 진단 프레임워크(Quantitative Diagnostic Framework): AI 사회의 역학을 측정하기 위해 의미 안정화(Semantic Stabilization, 내용이 고정되는 정도), 어휘 교체율(Lexical Turnover, 새로운 단어의 등장과 기존 단어의 소멸), 개별 관성(Individual Inertia, 개인이 의견을 바꾸지 않는 정도), 영향력 지속성(Influence Persistence), 집단적 합의(Collective Consensus) 등 5가지 핵심 지표를 정의하고 측정했습니다.
- 다층적 분석 수행: 거시적 관점에서는 전체 사회의 활동 역학과 의미 분포 변화를 추적했고, 미시적 관점에서는 개별 에이전트의 진화와 네트워크 구조적 역학(답글 및 추천 체계)을 분석하여 시간에 따른 변화를 관찰했습니다.
핵심 기법
이 논문의 가장 독창적인 방법은 단순히 채팅 기록을 모니터링하는 것을 넘어, AI 사회 전체를 하나의 유기체처럼 보고 ‘의미론적 수렴(Semantic Convergence)‘이 일어나는지 수학적으로 진단한 점입니다. 마치 의사가 환자의 혈압과 맥박을 재서 건강 상태를 판단하듯, 사회의 ‘어휘’와 ‘의미’의 흐름을 추적하여 그 사회가 정체되어 있는지 진화하고 있는지를 판별했습니다.
📊 정량적 결과
주요 성과
- 기존 연구 중 가장 큰 규모였던 Chirper.ai(약 65,000명)와 비교할 때 약 40배 이상 많은 약 2,600,000명의 등록 에이전트 수를 기록하며, 현재 공개된 AI 전용 사회 중 가장 큰 규모를 분석했습니다.
- 사회 전체의 평균적인 의미는 빠르게 안정화되지만(Stabilization), 개별 에이전트 간의 내용은 동질화되지 않고 높은 내부 분산(Internal Variance)을 유지한다는 것을 입증했습니다.
- 어휘 교체율(Lexical Turnover)이 지속적으로 발생하여, 사회가 고립되지 않고 끊임없이 새로운 언어적 변화를 수용하고 있음을 확인했습니다.
🚀 기존 대비 개선점
- 기존 소규모 AI 에이전트 연구(예: 25명의 제너레이티브 에이전트)가 단기적인 상호작용에 그쳤던 반면, 수백만 개의 에이전트가 장기간(수개월) 상호작용하는 ‘개방형 지속 사회’를 처음으로 대규모로 진단했습니다.
- 인간 사회의 사회화 이론을 AI 사회에 적용하여, 단순한 기계적 조정이 아닌 사회학적 관점에서 AI 집단의 거동을 해석하는 새로운 분석 패러다임을 제시했습니다.
🎯 활용 분야
- 대규모 다중 에이전트 시스템(Multi-Agent System) 설계: 수많은 AI 에이전트가 협력하거나 경쟁하는 시스템을 구축할 때 에이전트 간의 의사소통이 획일화되지 않고 창의성을 유지하도록 설계하는 데 활용할 수 있습니다.
- AI 거버넌스 및 안전성 연구: 자율적인 AI 사회가 통제 불가능하게 폐쇄적이거나 극단적인 합의(일종의 군집심리)로 수렴하는지를 모니터링하는 진단 도구로 사용할 수 있습니다.
- 계산 사회학(Computational Social Science) 시뮬레이션: 인간 사회의 복잡한 역학을 AI를 통해 시뮬레이션하여, 디지털 공간에서의 여론 형성이나 정보 전파 과정을 연구하는 데 기여할 수 있습니다.
한계 및 주의사항
- 저자들은 이 연구 결과가 ‘사회화의 부재’를 의미한다기보다는, 인간과는 다른 형태의 ‘동적 평형(Dynamic Equilibrium)’ 상태임을 시사한다고 해석했습니다. 즉, AI 사회가 인간의 사회화 과정을 그대로 따르지는 않는다는 점을 유의해야 합니다.
- 현재 분석은 주로 텍스트(의미론적) 데이터와 네트워크 구조에 집중되어 있어, 향후에는 에이전트의 행동 패턴이나 감정 상태 등 더 심층적인 심리적 변화를 추적하는 연구가 필요합니다.
5. ResearchGym: Evaluating Language Model Agents on Real-World AI Research
arXiv: 2602.15112 | ⬆️ 14 | ⭐ 5 📊 순위선정 | 📄 HTML 태그:
researchgymllm-agentai-researchbenchmarkclosed-loopevaluationautomated-sciencegpt-5사전 지식: 폐루프 연구(Closed-loop Research), ReAct 에이전트(ReAct Agent), 상태 지금 최고 성능(SOTA: State-of-the-Art), 베이스라인(Baseline), 스캐폴딩(Scaffolding)

한 줄 요약
실제 AI 연구 논문의 코드 베이스를 활용해 언어 모델 에이전트의 폐루프(Closed-loop) 연구 능력을 객관적으로 측정할 수 있는 최초의 실세계 벤치마크인 ResearchGym을 제안하며, 에이전트가 때로는 인간을 뛰어넘는 성과를 내기도 하지만 전반적으로 신뢰성(Reliability) 문제가 심각함을 규명했습니다.
💡 핵심 아이디어
이 논문은 AI에게 완벽하게 갖춰진 실험실(코드와 데이터)을 주되, 연구 방법론(알고리즘)은 빼놓고 스스로 발견해내도록 하는 도전 과제를 제시합니다. 마치 셰프에게 요리 재료와 부엌은 그대로 두고, 요리책을 치워버린 뒤 맛으로 보며 요리법을 처음부터 개발해 내도록 하는 ‘블라인드 테스트’와 유사합니다.
문제 정의
기존의 평가 방식들은 연구의 아이디어를 생성하는 단계나 단순히 코드를 구현하는 단계만을 쪼개서 평가할 뿐, 가설을 세우고 실험을 설계한 뒤 결과를 분석하여 다음 아이디어로 이어지는 연구의 전체 과정인 폐루프(Closed-loop)를 평가하지 못했습니다. 이로 인해 선택된 예제에서만 잘 작동하는 과대평가된 능력이 문제였습니다.
🔬 방법론 상세
- 실제 논문 기반의 태스크 환경 구축 ICML, ICLR, ACL 등의 상위권 논문 5편을 선정하여 데이터셋, 평가 도구(Evaluation harness), 기존 베이스라인(Baseline) 코드는 그대로 두되 논문에서 제안한 핵심 방법론만 제거했습니다. 이를 통해 총 39개의 하위 태스크가 포함된 5개의 컨테이너화된 환경을 구축했습니다.
- ReAct 에이전트(ReAct Agent) 스캐폴딩 GPT-5와 같은 최신 언어 모델을 ReAc(Reasoning + Acting) 패턴을 사용하는 에이전트로 구성했습니다. 이 에이전트는 도구 사용 루프(Tool use loop)를 통해 가설을 제안하고 코드를 실행한 뒤, 예산이 소진되거나 최종 결과를 제출할 때까지 반복적으로 행동합니다.
- 제한된 예산 내의 통제된 평가 각 태스크당 LLM API 비용 10달러(약 4천만 토큰 입력)와 12시간 시간을 제한으로 부여했습니다. 만약 1차 실행에서 좋은 결과가 나오면 추가로 10달러와 12시간을 더 주어 성능을 극대화하는 방식(Budget B)으로 실험을 진행했습니다.
핵심 기법
연구자들은 에이전트가 무에서 유를 창조하게 하는 대신, 이미 검증된 실제 연구 저장소(Repository)를 출발점으로 제공함으로써 현실적인 연구 환경을 모사했습니다. 이는 에이전트가 실제 연구자들이 겪는 문제 해결 과정을 겪게 하여, 단순 코딩 능력이 아닌 ‘진짜 연구 능력’을 평가할 수 있게 합니다.
📊 정량적 결과
주요 성과
- TIM 과제(ICML Spotlight)에서 단일 실행 결과가 논문에 보고된 참조 솔루션(SOTA)을 넘어섰습니다 (CPD(A) = 0.589 vs SOTA = 0.463).
- CL 및 CMR 과제에서 최고 성능(Best@3)은 인간 최고 성능(SOTA)의 93~96% 수준에 도달했습니다.
- 하지만 평균 성능(Average)은 베이스라인보다 낮은 경우가 많아 큰 편차(Variance)를 보였습니다. 예를 들어 CL 과제의 경우 평균은 30.75 ± 37.39였으나, 최고 성능은 80.4로 기록되었습니다.
🚀 기존 대비 개선점
- 기존 벤치마크가 단편적인 능력만 측정했던 것과 달리, 아이디어 도출(Ideation)부터 실행(Experimentation)까지 연결된 연구 전체 과정을 평가합니다.
- 자가 보고(Self-reported) 연구가 아닌 실제 코드 실행과 객관적인 점수(Metric)를 통해 신뢰할 수 있는 평가 환경을 제공합니다.
- 다양한 에이전트(AI-Scientist-v2, ML-Master 등)를 통일된 환경에서 비교할 수 있는 표준화된 플랫폼을 제공합니다.
🎯 활용 분야
- 자동화된 AI 연구 어시스턴트 개발 및 검증
- 장기적인 추론(Long-horizon reasoning)이 필요한 에이전트의 신뢰성 테스트
- 연구 개발(R&D) 프로세스에서 인간 연구자를 보조하는 자율 주행형 코딩 에이전트 훈련
한계 및 주의사항
- 에이전트의 성능이 실행마다 크게 달라지는 ‘능력-신뢰성 격차(Capability-Reliability Gap)‘가 심각합니다. 가끔 대박이 나지만 대부분은 실패하거나 평범한 수준에 머릅니다.
- 실험 추적(Experiment tracking), 자원 관리(Resource management), 그리고 긴 문맥 처리(Context degradation) 과정에서의 한계로 인해 연구가 지속되지 못하고 중단되는 경우가 많습니다.
6. UniT: Unified Multimodal Chain-of-Thought Test-time Scaling
arXiv: 2602.12279 | ⬆️ 13 🤖 GLM추천 | 📄 HTML 태그:
multimodaltest-time-scalingchain-of-thoughtgenerative-aiiterative-refinementvisual-reasoningunified-models사전 지식: Test-time Scaling (추론 시간 연산 확장), Chain-of-Thought (사고의 연쇄), Multimodal Models (멀티모달 모델), Agentic Framework (에이전트형 프레임워크), Best-of-N Sampling

한 줄 요약
이 논문이 중요한 이유는 텍스트 모델에서만 가능하던 추론 시간 연산 확장(Test-time Scaling) 기법을 통합 멀티모달 모델로 확장하여, 단일 모델이 스스로 생각하고 검토하며 이미지를 수정하고 정교화하는 능력을 처음으로 구현했기 때문입니다.
💡 핵심 아이디어
기존의 멀티모달 모델은 마치 그림을 한 번에 그리고 말아서 틀리면 처음부터 다시 그려야 했습니다. UniT은 마치 화가가 그림을 그리며 중간마다 한 발 물러나서 구도를 확인하고, 그림자가 어색하면 덧칠하는 과정을 반복하는 것처럼, 모델이 스스로 생성물을 평가(Reflection)하고 수정(Refinement)하는 여러 단계의 사고 과정을 거쳐 결과물을 완성하게 합니다.
문제 정의
이 논문은 하나의 통합된 아키텍처로 시각적 이해와 생성을 모두 수행하는 모델이, 복잡한 공간 구도, 다중 객체 상호작용, evolving instructions(진행형 지시) 같은 복잡한 작업에서 단 한 번의 생성 패스(Single-pass)로는 중간 결과를 평가하거나 수정할 기회가 없어 성능이 제한된다는 문제를 해결하고자 합니다.
🔬 방법론 상세
- 에이전트 기반 멀티모달 사고 데이터 수집: 학습 데이터를 만들기 위해 외부의 여러 모델(Llama-4-Scout, Flux Pro, Qwen3-VL)을 에이전트처럼 협력시킵니다. 프롬프트 생성, 초기 이미지 생성, 이미지가 프롬프트를 만족하는지 평가하는 반사(Reflection) 과정을 자동화하여 모델이 스스로 생각하고 수정하는 데이터를 확보합니다.
- 순차적 사고 연쇄(Sequential Chain-of-Thought) 확장: 병렬로 여러 샘플을 만드는 것(Best-of-N)보다, 순차적으로 생각을 이어가고 수정하는 방식이 효율적임을 입증합니다. 이를 통해 검증(Verification)과 하위 목표 분해(Subgoal decomposition) 같은 인지적 행동이 모델에게서 발현(Emergent)되도록 유도합니다.
- 추론 시 예산 강제(Budget Forcing): 추론 시점에 사용 가능한 계산 자원(Compute Budget, C)을 설정(예: C=1~10)하여, 모델이 할당된 예산 내에서 스스로 계획을 세우고 단계를 나누어 반복적으로 결과를 정교화(Refinement)하도록 제어합니다.
핵심 기법
가장 중요한 기법은 학습 시와 추론 시의 모델 구성을 분리한 것입니다. 데이터를 만들 때는 여러 전문가 모델들이 힘을 합치지만, 실제로 우리가 사용할 때(추론)는 오직 하나의 통합된 모델(BAGEL)만 사용합니다. 즉, 외부의 도움 없이도 모델 내부에서 계획, 생성, 반성, 수정이 모두 일어나도록 훈련시키는 것이 핵심입니다.
📊 정량적 결과
주요 성과
- OneIG-Bench-EN 및 ImgEdit 벤치마크 등에서 사고 연쇄(Chain-of-Thought)를 적용하지 않은 기본 모델(Bagel) 및 텍스트만 생각하는 모델(Bagel+CoT) 대비 **상당한 성능 향상(Substantial gains)**을 달성했습니다.
- 다단계 편집 작업(ImgEdit)에서 인간 평가자 간의 일치도가 매우 높은(알파값 0.82) 조건에서, 내용 기억(Content memory) 및 이해(Content understanding) 점수가 유의미하게 상승했습니다.
- 최대 계산 예산인 C=10까지 수행할 경우 성능이 지속적으로 개선됨을 확인했으며, 순차적 추론 방식이 병렬 샘플링(Best-of-N) 방식보다 우수한 성능을 보였습니다.
🚀 기존 대비 개선점
- 기존 통합 모델의 한 번 생성 끝 방식(Single-pass)에서 벗어나, 추론 시간을 늘려줌에 따라 성능이 향상되는 Test-time Scaling 효과를 멀티모달 영역으로 확장했습니다.
- 단일 모델이 이해와 생성을 번갈아 가며 수행하면서도 불일치(Interleaving) 문제를 해결하고, 맥락을 지속적으로 추적(Context tracking)하는 능력이 강화되었습니다.
- 복잡한 지시사항을 하위 목표로 자동 분해(Subgoal decomposition)하여 처리하는 능력이 새롭게 발현되었습니다.
🎯 활용 분야
- 구성적 이미지 생성: 여러 객체가 복잡하게 얽혀 있거나 정교한 공간 관계가 필요한 이미지를 생성하는 작업
- 대화형 이미지 편집: 사용자와 여러 번 대화를 주고받으며 이미지를 수정하는 멀티턴 편집(Multi-turn editing) 서비스
- 복합적인 시각적 추론: 이미지를 보고 논리적으로 답을 내야하는 복잡한 시각적 질의응답(Visual Reasoning) 시스템
한계 및 주의사항
- 현재 실험은 GPU 메모리 제약으로 인해 최대 계산 예산 C=10(다단계 편집 시 C=4)으로 제한되었으며, 더 높은 예산에서의 성능 향상 폭은 추가 검증이 필요합니다.
- 고도화된 반사(Reflection) 및 수정(Refinement) 과정을 위해서는 초기 학습 데이터 구축에 상당한 비용과 외부 모델들이 필요합니다.
7. Understanding vs. Generation: Navigating Optimization Dilemma in Multimodal Models
arXiv: 2602.15772 | ⬆️ 5 | ⭐ 2 🤖 GLM추천 | 📄 HTML 태그:
multimodalgenerationunderstandingr3-frameworkoptimization-dilemmavisual-reasoninggenerative-ai사전 지식: Multimodal Models, Visual Question Answering (VQA), Next-Token Prediction, Diffusion Objective, Reward Model

한 줄 요약
멀티모달 모델에서 이해와 생성 능력이 상충하는 근본적인 딜레마를 R3(Reason-Reflect-Refine) 프레임워크를 통해 해결하여 두 능력을 동시에 획기적으로 끌어올린 혁신적인 연구입니다.
💡 핵심 아이디어
마치 글을 쓰는 작가가 초고를 쓴 뒤, 교정자의 눈으로 스스로 내용을 검토하고 피드백을 반영해 완성본을 다시 쓰는 과정과 같습니다. 기존 모델은 단순히 결과물을 만들어내기만 했다면, 이 방법은 모델이 스스로 생성한 결과를 다시 한번 이해하고 분석하는 과정(Reflect)을 거쳐 더 정교한 결과물로 재생성(Refine)하도록 유도합니다.
문제 정의
현재의 멀티모달 모델들은 생성 능력(예: 그림 그리기)과 이해 능력(예: 그림 속 물체 세기, 공간 추론)을 동시에 높이기 어려운 운명적인 상충 관계에 있습니다. 생성에 특화된 모델은 정밀한 이해를 못하고, 이해에 특화된 모델은 창의적인 생성을 못하는 ‘최적화 딜레마(Optimization Dilemma)‘가 핵심 문제입니다.
🔬 방법론 상세
- Reason-Reflect-Refine (R3) 프레임워크: 단일 스텝 생성 과정을 이유 추론(Reason) - 반성(Reflect) - 재생성(Refine)의 다단계 과정으로 변형합니다.
- 생성-이해-재생성 흐름: 모델이 이미지를 생성하면, 해당 이미지를 다시 입력으로 받아 이해하고, 이를 바탕으로 초기 프롬프트를 수정하거나 생성 파라미터를 조정하여 이미지를 다시 생성합니다.
- 다단계 반복 학습: 기본적으로 1단계의 추론 이후 4단계의 반영 및 정제 과정을 거치도록 설계하여, 반복할수록 결과물의 품질과 정합성이 높아집니다.
- 보상 모델(Reward Model) 활용: Qwen-2.5-VL-72B와 같은 고성능 보상 모델을 사용하여 생성된 결과물의 품질과 프롬프트 일치도를 평가하고, 이를 학습에 반영합니다.
핵심 기법
이 논문의 핵심은 모델이 결과물을 만들기만 하고 끝내는 게 아니라, **‘자기가 만든 것을 스스로 검수하는 과정을 학습 과정에 포함시킨 것’**입니다. 마치 퀴즈를 풀 때 답을 적고 나서 문제를 다시 읽어보며 오류를 바로잡는 ‘메타 인지’ 전략을 AI 모델에 구현한 셈입니다.
📊 정량적 결과
주요 성과
- GenEval++ 벤치마크: 기존 방식 대비 더 강력한 생성 결과를 달성했습니다.
- 이해 능력 향상: 구성적 시각 질의 응답(Compositional VQA)과 이미지-텍스트 정렬(ITA) 평가 지표에서 이해 능력이 유의미하게 개선되었습니다.
- 수치적 개선: 제공된 논문 텍스트에는 구체적인 백분율 수치가 포함된 테이블이 생략되어 있으나, GPT-4.1 기반 평가와 Gemini-2.5-Flash를 통한 골드 스탠다드(Gold-standard) 비교를 통해 기존 모델(BAGEL 등) 대비 생성 품질과 이해력이 모두 상승했음이 입증되었습니다.
🚀 기존 대비 개선점
- 생성과 이해가 경쟁하던 최적화 목표를, 이해를 생성의 하위 과정으로 통합하여 상호 보완적으로 만들었습니다.
- 별도의 토크나이저(Tokenizer)나 아키텍처 수정 없이도 알고리즘적 접근(프레임워크 변경)만으로 성능을 끌어올렸습니다.
- 모델이 스스로 생성된 결과를 피드백으로 활용하여 점진적으로 품질을 높이는 자가 개선(Self-improvement) 능력을 갖추게 했습니다.
🎯 활용 분야
- 고정밀 이미지 생성: 복잡한 공간적 배치나 물체의 개수를 정확히 준수해야 하는 고품질 이미지 생성 시스템.
- 통합형 멀티모달 에이전트: 시각 정보를 이해하여 판단하고, 그에 따라 새로운 이미지를 생성해야 하는 AGI(Artificial General Intelligence) 에이전트.
- 크리에이티브 도구: 사용자의 복잡한 요구 사항을 더 정확하게 반영하는 AI 디자인 및 편집 도구.
한계 및 주의사항
- 다단계 생성 과정(Reasoning 및 4단계의 Reflection)을 거치므로, 단일 스텝 생성 방식에 비해 추론 속도가 느리고 연산 비용이 증가할 수 있습니다.
- 시스템의 성능이 보상 모델(Reward Model)의 품질에 크게 의존하므로, 보상 모델이 편향되어 있을 경우 전체 시스템의 성능에 영향을 줄 수 있습니다.
8. On Surprising Effectiveness of Masking Updates in Adaptive Optimizers
arXiv: 2602.15322 | 기관: Google | ⬆️ 5 🤖 GLM추천 | 📄 HTML 태그:
llmoptimizerpre-trainingmagmamaskingefficiencyadaptive-methodsdeep-learning사전 지식: Stochastic Gradient Descent (SGD), Adaptive Optimizer (Adam, RMSProp), Momentum, Backpropagation, Perplexity

한 줄 요약
거대 언어 모델 학습의 표준인 Dense 업데이트(모든 파라미터를 업데이트하는 방식)가 최적이 아니라는 사실을 밝히며, 무작위 마스킹과 모멘텀 정렬을 통해 학습 안정성과 성능을 동시에 끌어올린 획기적인 옵티마이저 최적화 기법입니다.
💡 핵심 아이디어
수많은 파라미터를 한 번에 모두 고치는 것보다, 일부는 건너뛰거나(Masking) 중요한 부분만 집중적으로 관리하는 것이 더 효과적일 수 있다는 발상입니다. 마치 거대한 건물을 리모델링할 때, 모든 벽을 매일 다시 씻기보다 중요한 구조적 부분을 중심으로 손질하고 나머지는 확률적으로 건너뛰는 것이 오히려 건물을 더 튼튼하게 만드는 것과 비슷합니다.
문제 정의
현재 대규모 언어 모델(LLM)을 학습할 때는 주로 Adam과 같은 Dense 옵티마이저(모든 파라미터를 매번 업데이트하는 방식)를 표준처럼 사용합니다. 그러나 이 방식은 연산량이 많고, 학습 경로가 불안정해지거나 노이즈(Noise)에 취약한 구조적 불일치 문제가 있습니다. 본 논문은 모든 파라미터를 빠짐없이 업데이트하는 것이 과연 최선인지에 의문을 제기합니다.
🔬 방법론 상세
- SkipUpdate (기본 마스킹): 파라미터 업데이트 단계에서 50%의 확률(Bernoulli 분포)로 업데이트를 건너뛰는 무작위 마스킹을 적용합니다. 이를 통해 학습 궤적을 부드럽게 만드는 곡률 의존적 기하학적 정규화(Curvature-dependent geometric regularization) 효과를 유도합니다.
- Magma (Momentum-aligned gradient masking): 단순한 무작위 마스킹을 넘어, 모멘텀(이전 그라디언트의 이동 평균)과 현재 그라디언트가 얼마나 일치하는지를 기준으로 업데이트 강도를 조절합니다.
- 핵심 알고리즘:
- 모멘텀($\mu_t$)과 그라디언트($g_t$) 간의 코사인 유사도(Cosine similarity)를 측정합니다.
- 이를 시그모이드(Sigmoid) 함수에 통과시켜 스케일링 계수($\tilde{s}_t$)를 계산합니다.
- 이 계수를 지수 이동 평균(EMA)으로 smoothing 하여 최종 업데이트 비율($s_t$)을 결정합니다.
- 최종 파라미터 업데이트 시 무작위 마스크($m_t$)와 계수($s_t$)를 곱하여 적용합니다. $$ \theta_{t+1} = \theta_{t} - s_t \cdot m_t \cdot \Delta_t $$
핵심 기법
가장 중요한 기법은 모멘텀과 그라디언트의 정렬(Alignment)을 이용한 스마트한 필터링입니다. 쉽게 말해, 모멘텀(관성)이 가리키는 방향과 현재 그라디언트(기울기)의 방향이 같을 때는 “이건 중요한 신호다”라고 판단해 업데이트를 확실히 하고, 방향이 엇갈릴 때는 “노이즈다”라고 판단해 업데이트를 조심스럽게 진행합니다.
📊 정량적 결과
주요 성과
- Llama 2 아키텍처를 C4 데이터셋으로 사전 학습(Pre-training)한 결과, 10억(1B) 파라미터 모델에서 RMSProp+Magma는 검증 Perplexity(혼란도) 13.19를 기록하여 기존 Adam의 16.35 대비 약 19% 개선된 성능을 보였습니다.
- 최신 옵티마이저인 Muon, APOLLO 등을 포함한 다양한 기법 대비 Magma를 적용한 Adam과 RMSProp이 일관되게 더 낮은 Perplexity(더 좋은 성능)를 기록했습니다.
- 계산 오버헤드는 무시할 수준(Negligible)이었으며, 기존 옵티마이저를 대체하는 드롭인(Drop-in) 솔루션으로 작동했습니다.
🚀 기존 대비 개선점
- 성능 향상: 다양한 모델 규모(60M ~ 1B)에서 기존 SOTA(State-of-the-art) 옵티마이저 대비 더 낮은 Perplexity(데이터 예측력)를 달성했습니다.
- 안정성 확보: 무작위 마스킹이 유도하는 기하학적 정규화 효과로 인해 학습 궤적이 더 매끄러워지고 불안정한 학습이 감소했습니다.
- 구현 용이성: 복잡한 구조 변경 없이 기존 옵티마이저 위에 간단한 로직만 추가하면 되므로 바로 적용 가능합니다.
🎯 활용 분야
- 거대 언어 모델(LLM) 사전 학습: 대규모 트랜스포머 기반 모델을 처음부터 학습할 때 학습 시간 단축 및 최종 성능 향상에 활용할 수 있습니다.
- 고성능 컴퓨팅(HPC) 환경: 연산 리소스가 매우 큰 학습 환경에서 효율적인 업데이트를 통해 비용 효율을 높일 수 있습니다.
- 최적화 불안정 문제 해결: 그라디언트가 폭발하거나 소멸하여 학습이 잘 안 되는 불안정한 모델 학습 시 안정화 장치로 사용할 수 있습니다.
한계 및 주의사항
- 이론적 해석의 완전성: 마스킹이 왜 효과적인지에 대한 기하학적 정규화 설명이 제시되었으나, 모든 상황을 보증하는 이론적 증명은 향후 연구 과제로 남아 있습니다.
- 하이퍼파라미터 튜닝: 논문에서는 $\tau=2$와 같은 기본 설정을 제안했지만, 특이한 데이터셋이나 매우 작은 모델에서는 추가적인 튜닝이 필요할 수 있습니다.
9. Panini: Continual Learning in Token Space via Structured Memory
arXiv: 2602.15156 | ⬆️ 4 🤖 GLM추천 | 📄 HTML 태그:
continual-learningretrieval-augmented-generationsemantic-memoryllm-efficiencynon-parametric-learningnlpknowledge-graphpanini사전 지식: Retrieval-Augmented Generation (RAG), In-context Learning (ICL), Parametric vs Non-parametric Learning, Catastrophic Forgetting, Context Window

한 줄 요약
기존 검색 증강 생성(RAG) 방식의 비효율적인 컴텍스트 사용과 파라메트릭 학습(Parametric Learning)의 단점을 극복하고, 모델 파라미터를 고정한 채 외부의 구조화된 의미 기억을 통해 효율적이고 강력한 지속적 학습이 가능한 프레임워크인 Panini를 제안했기 때문에 중요합니다.
💡 핵심 아이디어
마치 시험 공부를 할 때 매번 방대한 교과서 전체를 다시 읽는 대신(RAG), 배울 때마다 핵심 내용을 추려서 개념도를 업데이트하는 나만의 연습장(Panini)을 활용하는 것과 같습니다. 이 연습장(구조화된 기억)에는 필요한 정보가 통합되어 저장되므로, 문제를 풀 때는 연습장의 핵심 내용만 훑어 훨씬 빠르고 정확하게 답을 찾을 수 있습니다.
문제 정의
이 논문은 대규모 언어 모델이 학습되지 않은 새로운 문서나 정보를 다루어야 할 때 발생하는 문제를 해결하고자 합니다. 기존의 검색 증강 생성(RAG)은 불필요한 문서를 반복해서 읽어 연산 비용이 높고, 문맥 길이 제한(Context Window)으로 인해 정보 누락이 발생합니다. 또한 모델 자체를 업데이트하는 파라메트릭 지속적 학습(Parametric Continual Learning)은 비용이 많이 들고 치명적 망각(Catastrophic Forgetting) 문제가 있습니다.
🔬 방법론 상세
- 인간 같은 비모수적 지속적 학습(Human-like non-parametric continual learning) 프레임워크를 채택하여 베이스 모델(Base Model)의 파라미터는 고정합니다.
- 각각의 새로운 경험을 외부의 의미 기억 상태(External semantic memory state)에 통합(Integrating)하고 정합(Consolidating)하여 학습을 수행합니다.
- 토큰 공간(Token Space)에서 구조화된 메모리를 활용하여 정보를 저장하고 검색하며, 문맥 창(Context Window) 내의 토큰 수를 획기적으로 줄입니다.
핵심 기법
가장 중요한 기법은 **구조화된 의미 기억 상태(Structured Semantic Memory State)**입니다. 단순히 문서 조각(Chunks)을 저장하는 기존 RAG와 달리, Panini는 새로운 정보를 읽을 때마다 이를 외부 기억 상태에 통합하여 구조화합니다. 이를 통해 모델이 답변 생성 시 불필요한 원문을 다시 읽지 않고, 이미 학습된 기억 상태만 참고하므로 토큰 사용량을 2~30배까지 줄일 수 있습니다.
📊 정량적 결과
주요 성과
- 6개 QA 벤치마크에서 평균 56.06%의 F1 점수를 기록하여 가장 강력한 베이스라인인 HippoRAG 2(53.3%)보다 높은 성능을 보였습니다.
- LV-Eval 벤치마크에서는 14.81%를 기록하여 기존 방법들(BM25 7.8%, Dense Retrieval
1011%)을 큰 폭으로 능가했습니다. - 생성 컨텍스트(Generation Context)의 평균 토큰 수가 경쟁 방법 대비 2배에서 최대 30배까지 적게 사용되어 효율성을 입증했습니다.
🚀 기존 대비 개선점
- 기존 검색 방식(BM25, Dense Retrieval) 대비 검색 정확도(F1)가 크게 향상되었습니다(단순 QA 및 멀티홉 QA 모두에서).
- 문맥 창에 들어가는 토큰 수를 획기적으로 줄여 추론 시 연산 비용(Test-time compute)을 절감했습니다.
- RAPTOR나 GraphRAG 같은 구조 증강 RAG 방식보다 적은 토큰으로 더 높은 성능을 달성했습니다.
🎯 활용 분야
- 방대한 내부 문서를 보유한 기업의 지원 시스템(반복적인 질문 처리 최적화).
- 지식이 계속 업데이트되는 뉴스나 연구 분야의 동적 QA 시스템.
- 사용자의 개인 데이터를 장기간 기억하고 학습해야 하는 개인형 비서 AI.
한계 및 주의사항
- 제공된 텍스트에서는 저자가 명시적으로 직접적인 한계점을 언급하지는 않았으나, 구조화된 의미 기억 상태를 유지하고 관리하는 오버헤드(Overhead)가 단순 검색 방식보다 복잡할 수 있습니다.
- 새로운 경험을 기억 상태에 통합하는 방식이 초기 설정에 민감할 수 있으며, 기억의 정합(Consolidation) 과정에서의 오류 가능성은 추가적인 검증이 필요합니다.
10. The Vision Wormhole: Latent-Space Communication in Heterogeneous Multi-Agent Systems
arXiv: 2602.15382 | 기관: Data mining & Machine learning @ Purdue University | ⬆️ 1 | ⭐ 4 🤖 GLM추천 | 📄 HTML 태그:
multi-agent-systemsvlmlatent-spacecommunication-efficiencynlpreasoningai-optimization사전 지식: Latent Space (잠재 공간), Manifold (다양체), Quantization (양자화), Vision-Language Model (시각-언어 모델), Multi-Agent Systems (다중 에이전트 시스템)

한 줄 요약
서로 다른 구조의 모델들이 텍스트 없이 고품질의 잠재 정보를 직접 주고받을 수 있는 ‘비전 웜홀’ 프레임워크를 제안하여, 다중 에이전트 시스템의 통신 병목을 해결하고 효율성을 획기적으로 높였습니다.
💡 핵심 아이디어
서로 다른 언어를 쓰는 외국인들이 번역기를 통해 대화하는 것 대신, 누구나 이해하는 직관적인 그림을 통해 생각을 주고받는 것과 같습니다. 이 방식은 언어(텍스트)로 변환하는 과정에서 생기는 정보 손실과 시간 낭비를 없애고, 더 풍부한 감정과 맥락(잠재 상태)을 빠르게 전달할 있게 합니다.
문제 정의
기존 다중 에이전트 시스템(MAS)은 텍스트로 소통하느라 느리고 정보가 손실되거나, 서로 다른 모델 간 통신을 위해 비싼 번역 모듈을 따로 만들어야 하는 확장성 문제를 겪고 있었습니다.
🔬 방법론 상세
- Universal Visual Codec(범용 시각 코덱): 각 에이전트의 내부 상태를 요약한 잠재 롤아웃(latent rollout)을 추출하고, 이를 고정된 크기의 보편 토큰(universal tokens)으로 압축하는 경량화된 모듈입니다. 이 모듈은 한 번 학습된 후 추론 시에는 동결(frozen)됩니다.
- Affine Alignment(아핀 정렬): 서로 다른 모델 계열의 잠재 공간(Manifold, 다양체)을 하나의 공유된 참조 공간(shared reference space)에 매핑하여, 서로 호환되지 않는 데이터 형식을 통합하는 기법입니다.
- Vision-Token Span Injection: 수신자 모델의 이미지 처리 영역(vision-token span)에 보내온 토큰을 해독한 섭동(perturbation, 작은 변화량)을 직접 주입하여, 텍스트 입력 없이도 정보가 이미지처럼 처리되게 만듭니다.
핵심 기법
시각-언어 모델(VLM)이 이미지를 이해하는 통로를 ‘지름길’로 사용하는 것입니다. 원래는 카메라로 찍은 사진 정보가 들어가야 할 자리에, 보내고 싶은 생각을 압축한 데이터를 몰래 넣어 모델이 마치 이미지를 보고 상대방의 생각을 읽은 것처럼 행동하게 만드는 창의적인 방법입니다.
📊 정량적 결과
주요 성과
- 수학, 과학, 상식 추론, 코드 생성 등 9가지 벤치마크(GSM8K, AIME, HumanEval-Plus 등)에서 텍스트 기반 통신 대비 일관된 속도 향상과 경량 모델 환경에서의 정확도 개선을 보여주었습니다.
- 다중 모델 간 통신 모듈의 필요 개수가 기존 방식의 제곱급(quadratic) 복잡도에서 선형적(linear) 복잡도로 줄어들어 시스템 확장성이 크게 향상되었습니다.
🚀 기존 대비 개선점
- 텍스트를 토큰화(변환)하고 디코딩하는 과정이 없어져 런타임 오버헤드가 크게 감소했습니다.
- 고차원의 내부 상태를 낮은 차원의 텍스트로 줄이는 과정에서 발생하는 정보 손실(Quantization loss)을 원천적으로 차단합니다.
- 사전 학습된 VLM 백본의 파라미터를 수정하지 않고 통신 레이어만 추가하므로, 모델 재학습 없이도 다양한 모델 간 협업이 가능합니다.
🎯 활용 분야
- 전문화된 추론 모델과 창의적인 생성 모델이 협력하여 복잡한 과학 문제를 해결하는 연구 환경.
- 실시간 협업이 필요한 코드 생성 및 디버깅 시스템.
- 다양한 기업이나 기관의 서로 다른 폐쇄형 모델들이 연계하여 복합적인 의사결정을 내려야 하는 금융 또는 의료 분야.
한계 및 주의사항
- 통신하려는 모든 모델이 반드시 시각 인터페이스(Visual Interface)를 지원하는 시각-언어 모델(VLM)이어야 한다는 제약이 있습니다.
- 범용 시각 코덱(Universal Visual Codec)을 훈련시키기 위해서는 어느 정도의 지도 신호(Supervision)가 필요하며, 이 학습 데이터의 질에 성능이 의존할 수 있습니다.
📅 생성일: 2026-02-18 | 🤖 GLM-4.7