📚 2026-02-17 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 Experiential Reinforcement Learning ⬆️26
- 📊📄 DeepImageSearch: Benchmarking Multimodal Agen… ⬆️25
- 📊📄 REDSearcher: A Scalable and Cost-Efficient Fr… ⬆️17 ❌
- 📊📕 STATe-of-Thoughts: Structured Action Template… ⬆️16
- 📊📄 Query as Anchor: Scenario-Adaptive User Repre… ⬆️15
- 🤖📕 BitDance: Scaling Autoregressive Generative M… ⬆️15 ❌
- 🤖📄 Nanbeige4.1-3B: A Small General Model that Re… ⬆️13
- 🤖📄 Learning to Configure Agentic AI Systems ⬆️6
- 🤖📄 MoRL: Reinforced Reasoning for Unified Motion… ⬆️2
- 🤖📄 AnchorWeave: World-Consistent Video Generatio… ⬆️1 ❌
1. Experiential Reinforcement Learning
arXiv: 2602.13949 | 기관: Microsoft | ⬆️ 26 📊 순위선정 | 📄 HTML 태그:
experiential-learningreinforcement-learningagentic-aireflectionsparse-rewardsllm-reasoningmodel-improvement사전 지식: 강화학습(Reinforcement Learning), 언어 모델(Language Model), 희소 보상(Sparse Reward), 신용 할당 문제(Credit Assignment Problem), 에이전트(Agent)

한 줄 요약
희소하고 지연된 피드백(Sparse and Delayed Feedback) 환경에서 강화학습의 효율성을 극대화하기 위해 경험-반성-통합(Experience-Reflection-Consolidation) 루프를 도입하여, 언어 모델이 인간처럼 시행착오를 통해 스스로 고민하고 행동을 교정하는 법을 학습하게 한 점이 매우 중요합니다.
💡 핵심 아이디어
이 논문의 핵심 아이디어는 마치 수학 문제를 푸는 학생이 틀렸을 때, 단순히 점수만 확인하는 것이 아니라 틀린 이유를 반성(Reflection)하고 다시 풀어본 뒤, 그 올바른 풀이 과정을 머릿속에 각인(Consolidation)시키는 과정과 같습니다. 모델은 처음 시도한 후 환경으로부터 결과를 받고, 스스로 피드백을 분석하여 반성문을 생성합니다. 이 반성을 바탕으로 두 번째 시도를 더 나은 방식으로 수행하며, 이 두 번째 시도의 성공 여부를 통해 최종적으로 모델을 업데이트하므로 학습 효율이 비약적으로 향상됩니다.
문제 정의
현재 언어 모델을 에이전트(Agent, 환경과 상호작용하며 목표를 달성하는 시스템)로 사용할 때 직면하는 가장 큰 문제는 희소하고 지연된 보상(Sparse and Delayed Rewards)입니다. 즉, 모델이 긴 일련의 행동을 취한 뒤 맨 마지막에 성공했다는 사실만 알려줄 뿐, 그중 어떤 행동이 잘못되었는지 알려주지 않습니다. 이로 인해 모델은 무엇을 고쳐야 할지 암묵적으로 추론해야 하므로 학습이 불안정하고 매우 많은 시도가 필요하다는 문제가 있습니다.
🔬 방법론 상세
- 경험-반성-수정(Reflection-Guided Revision) 루프 모델이 초기 시도(Initial Attempt)를 하고 환경으로부터 피드백(성공/실패, 보상 등)을 받으면, 이를 바탕으로 자연어 형태의 반성(Reflection)을 생성합니다. 이 반성은 단순한 오류 표시가 아니라 “왜 실패했는지, 앞으로 어떻게 해야 하는지”에 대한 구체적인 가이드를 포함합니다. 모델은 이 가이드를 참조하여 수정된 두 번째 시도(Refined Attempt)를 수행합니다.
- 통합(Consolidation) 과정 이 방법의 핵심은 두 번째 시도를 할 때마다 항상 반성을 거쳐야 하는 것이 아니라, 두 번째 시도 중 성공한 케이스를 통해 얻은 정책을 원본 베이스 모델(Base Policy)에 내면화하는 단계입니다. 즉, 학습 시에는 반성을 통해 도움을 받지만, 실제 서비스(Inference) 시에는 추가적인 계산 비용 없이 즉시 올바른 행동을 취할 수 있도록 모델 자체의 지능을 향상시킵니다.
- 평가 없이 학습하기 Sokoban이나 Frozen Lake와 같은 벤치마크에서는 게임의 규칙이나 환역의 역학(Dynamics, 상태가 변화하는 원리)을 전혀 알려주지 않습니다. 모델은 오직 행동(Action)과 결과(Observation)만을 통해 규칙을 스스로 터득해야 하므로, 순수한 경험적 학습 능력을 평가하기에 최적화된 설정을 사용했습니다.
핵심 기법
가장 중요한 기법은 ‘반성을 통한 수정(Reflection-Guided Revision)‘입니다. 기존 강화학습이 수백 번의 시행착오를 통해 우연히 정답을 찾는 것에 비좁다면, ERL은 한 번의 실패 후 “이곳에 구멍이 있으니 피해야 해”라고 스스로 말해주는 과정을 거칩니다. 이를 통해 모델은 단순한 반복 학습이 아닌, 논리적인 추론 과정을 통해 불확실한 환경을 빠르게 이해하고 적응할 수 있습니다.
📊 정량적 결과
주요 성과
- Sokoban(창고 보기 게임) 환경에서 Qwen3-4B 모델은 기존 RLVR 방식 대비 성공률이 0.06에서 0.87로 약 1,350% 이상 개선되었습니다.
- 동일한 Sokoban 환경에서 Olmo3-7B 모델은 0.04에서 0.20으로 5배 상승하는 등, 장기적 계획이 필요한 작업에서 획기적인 성과를 보였습니다.
- 전반적인 학습 속도(Wall-clock time) 측면에서도 ERL은 기존 방법보다 더 적은 시간 동안 더 높은 보상(Reward)을 달성하는 것으로 확인되었습니다.
🚀 기존 대비 개선점
- 불안정한 최적화 문제 해결: 기존 방식이 실패의 원인을 찾지 못해 왔다 갔다 하는 탐색(Back-and-forth exploration)을 반복하던 것을, 반성 과정을 통해 명확한 행동 교정이 가능해졌습니다.
- 샘플 효율성(Sample Efficiency) 증대: 더 적은 횟수의 시도로도 환경의 규칙을 습득하여 학습 데이터 소요를 줄였습니다.
- 추론 능력 강화: 단순히 패턴을 외우는 것이 아니라, 환경의 상태와 행동의 결과를 연결하는 심층적인 추론 능력을 모델이 습득하게 했습니다.
🎯 활용 분야
- 복잡한 웹 에이전트(Web Agent): 사용자가 복잡한 질문을 던졌을 때, 검색 도구를 여러 번 사용하며 답을 찾는 멀티홉 질의 응답(Multi-hop QA) 시스템에 적용할 수 있습니다.
- 알 수 없는 규칙이 있는 환경: 게임이나 로봇 제어 등 사전에 규칙을 알려줄 수 없거나 규칙이 변경되는 동적 환경에서 에이전트가 스스로 적응해야 하는 상황에 유용합니다.
- 소프트웨어 디버깅: 코드를 실행해 보고 에러가 발생하면, 그 원인을 분석(반성)하여 수정 코드를 작성하는 자동화된 프로그래밍 보조 도구 개발에 활용될 수 있습니다.
한계 및 주의사항
- 반성 생성의 품질 의존성: 모델이 생성하는 반성(Reflection)의 질이 전체 성능에 큰 영향을 미치므로, 초기 모델의 추론 능력이 일정 수준 이상이어야 합니다.
- 계산 비용 증가 가능성: 하나의 학습 스텝마다 초기 시도와 반성, 수정된 시도를 모두 생성해야 하므로, 단순한 강화학습에 비해 단계별 계산량은 증가할 수 있습니다.
2. DeepImageSearch: Benchmarking Multimodal Agents for Context-Aware Image Retrieval in Visual Histories
arXiv: 2602.10809 | 기관: NLPIR Lab @ RUC | ⬆️ 25 | ⭐ 27 📊 순위선정 | 📄 HTML 태그:
image-retrievalmultimodal-agentcontext-awarevisual-historybenchmarkdeep-image-searchreasoningcomputer-vision사전 지식: Multimodal Retrieval, Agentic Workflow, Context-aware Reasoning, Computer Vision, Natural Language Processing, Semantic Matching

한 줄 요약
기존의 단순 매칭 방식을 넘어, 이미지 간의 시간적 흐름과 맥락을 이해하고 추론해야 하는 ‘맥락 인지형 검색’이라는 새로운 패러다임을 제시하며 멀티모달 에이전트의 능력을 평가할 수 있는 벤치마크를 처음으로 구축했기 때문에 중요합니다.
💡 핵심 아이디어
현재의 이미지 검색 시스템은 마치 도서관에서 책 제목만 보고 원하는 책을 찾는 것과 같습니다. 하지만 이 논문은 탐정이 된 듯이, CCTV 영상이나 개인 사진 앨범의 전체 맥락을 거슬러 올라가며 “파란 로고 콘서트가 열린 날짜 이후에 찍힌 사진”처럼 여러 단서를 연결해 답을 찾아내는 과정을 모델이 수행하도록 만들었습니다.
문제 정의
기존 멀티모달 검색 시스템(Multimodal Retrieval Systems)은 질의(Query)와 이미지를 개별적으로 1:1로 매칭하는 ‘독립적 인스턴스 매칭(Independent Instance Matching)‘에 의존합니다. 이는 사용자의 복잡한 의도를 파악하는 데 한계가 있으며, 특히 정보가 단일 이미지가 아닌 시간 순서의 비주얼 히스토리(Visual Histories)에 분산되어 있는 현실적인 상황을 반영하지 못한다는 문제를 해결하고자 합니다.
🔬 방법론 상세
- DISBench 데이터셋 구축: 맥락 의존적 질의(Context-dependent queries)를 생성하기 위해 인간과 모델이 협력하는 반자동화 파이프라인을 제안했습니다. 이 벤치마크는 시간 순서대로 정렬된 이미지 집합 $\mathcal{C}$과 자연어 질의 $Q$를 입력으로 받아, 조건을 만족하는 대상 집합 $\mathcal{R} \subseteq \mathcal{C}$을 예측하는 ‘맥락 인지형 집합 검색(Context-aware set retrieval)’ 과제로 정식화했습니다.
- ImageSeeker 에이전트 프레임워크: 대규모 사진 컬렉션을 탐색하기 위해 세 가지 핵심 도구(Tools)와 기억(Memory) 메커니즘을 통합한 기본 에이전트를 설계했습니다.
- TgImageSearch: 텍스트, 이미지 또는 혼합 입력을 받아 의미적으로 유사한 사진을 검색합니다.
- TgGetMetadata: 지정된 사진의 타임스탬프와 주소와 같은 메타데이터를 읽어옵니다.
- TgFilterMetadata: 시간적 또는 공간적 조건을 만족하는 사진들을 필터링합니다.
핵심 기법
이 논문의 가장 중요한 방법론은 **‘앵커 기반 추론(Anchor-based Reasoning)‘**을 강제한 점입니다. 예를 들어 “파란색과 흰색 로고가 있는 콘서트”라는 질의가 들어오면, 모델이 단순히 시각적으로 유사한 사진을 찾는 것에 그치지 않고, 먼저 해당 로고가 포함된 사진(앵커)을 데이터셋 내에서 찾아낸 뒤, 그 앵커의 시간 및 위치 정보를 기준으로 최종 목표를 탐색하도록 설계했습니다. 이는 모델이 단순 시각 매칭을 우회하지 못하고 실제로 추론 과정을 거치도록 유도합니다.
📊 정량적 결과
제공된 텍스트에는 구체적인 수치적인 개선 퍼센트(예: 정확도 20% 향상 등)가 포함되어 있지 않습니다. 대신 논문의 결론 부분에서 “광범위한 실험을 통해 이 과제가 최신 모델들에게 상당한 도전 과제를 제기한다는 것을 입증했다”고 언급하고 있습니다. 이는 기존 최신 기술(SOTA)들이 이 새로운 벤치마크에서 낮은 성능을 기록했음을 시사합니다.
주요 성과
- DeepImageSearch라는 새로운 에이전트 패러다임을 통해 이미지 검색을 정적 매칭에서 동적인 탐색 과제로 재정의했습니다.
- 상호 연결된 비주얼 데이터를 기반으로 한 DISBench라는 도전적인 벤치마크를 구축했습니다.
- 시맨틱 검색, 메타데이터 추론, 시각적 검증을 결합한 ImageSeeker라는 기본 에이전트 프레임워크를 제시했습니다.
🚀 기존 대비 개선점
- 단일 이미지 간의 유사도 계산에서 벗어나, 비주얼 히스토리 전체에 분산된 정보를 종합하는 맥락 이해 능력을 요구합니다.
- 사용자가 참조 이미지를 제공하더라도 시스템이 이를 텍스트 설명으로 변환하고, 전체 말뭉치(Corpus)에서 해당 앵커를 먼저 찾아내는 **다단계 추론(Multi-step reasoning)**이 가능합니다.
- 대규모 이미지 탐색 시 발생하는 컨텍스트 길이 한계를 관리하기 위한 기억 상태 유지 메커니즘이 포함되어 있습니다.
🎯 활용 분야
- 개인 사진 관리 앱: “작년 여름에 바닷가로 가는 길에 먹었던 아이스크림 사진 찾아줘”와 같이 복잡한 기억을 조건으로 하는 사진 검색.
- CCTV 및 감시 시스템: “빨간색 세단이 지나간 직후에 입장한 사람 찾기” 등 시간적 전후 관계가 중요한 범죄 수사 또는 보안.
- 전자상거래(E-commerce): “방금 본 빨간 원피스와 어울리는 가방이 있어?”와 같이 시청 이력을 바탕으로 한 추천 및 검색.
한계 및 주의사항
- 맥락 의존적 질의를 생성하는 데 있어 확장성(Scalability) 문제가 여전히 존재하며, 이를 해결하기 위해 인간과 모델이 협력하는 방식을 사용했지만 완전한 자동화는 추가 연구가 필요합니다.
- 제안된 ImageSeeker는 기본적인 기준 모델(Baseline)로서, 복잡한 다중 모달 reasoning을 처리하는 데 있어 여전히 성능 한계를 보일 수 있습니다.
3. REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents
arXiv: 2602.14234 | 기관: Xiaohongshu | ⬆️ 17 | ⭐ 9 📊 순위선정 | 📄 HTML 태그:
ai-paperml

❌ 분석 실패: Post “https://api.z.ai/api/coding/paas/v4/chat/completions”: unexpected EOF
4. STATe-of-Thoughts: Structured Action Templates for Tree-of-Thoughts
arXiv: 2602.14265 | ⬆️ 16 | ⭐ 4 📊 순위선정 | 📕 PDF 태그:
llmtree-of-thoughtsinference-time-computeaction-templatesstructured-generationinterpretable-aireasoning사전 지식: Inference-Time-Compute(ITC, 추론 시간 연산), Tree-of-Thoughts(ToT, 사고의 나무), High-temperature sampling(고온 샘플링, 무작위성이 높은 생성 방식), LLM(대규모 언어 모델), Prompt Engineering(프롬프트 엔지니어링)
한 줄 요약
기존의 추론 시간 연산(ITC) 방식들이 가진 무작위성의 한계를 넘어, 구조화된 행동 템플릿(Action Templates)을 통해 언어 모델이 생성 과정을 체계적이고 해석 가능하게 제어하여 다양성과 품질을 동시에 달성한 방법론을 제시했다는 점에서 중요합니다.
💡 핵심 아이디어
마치 요리사가 감각에만 의존해 요리하던 것(기존 고온 샘플링 방식)에서 벗어나, 각 단계별로 정해진 ‘법인 체인점 매뉴얼(행동 템플릿)‘을 사용하여 요리 스타일과 구성을 체계적으로 바꿔 끼우는 것과 같습니다. 이를 통해 요리(답변)의 품질을 높이면서도 원하는 맛(주제나 스타일)을 의도 있게 다양하게 만들 수 있습니다.
문제 정의
설득력 있는 글쓰기나 창의적 글쓰기 같은 작업에서는 단순히 높은 품질의 답변을 넘어, 특정 ‘차원(예: 수사학적 구조, 주제)‘을 따라 체계적으로 변화하면서도 일관성을 유지하는 답변이 필요합니다. 하지만 기존의 Best-of-N이나 Tree-of-Thoughts(ToT) 같은 방식은 높은 온도(Temperature)의 샘플링을 사용해 다양성을 추구하는데, 이는 종종 의미 없는 무작위성만을 만들어내고 생성 과정을 해석하거나 제어하기 어렵다는 문제가 있습니다.
🔬 방법론 상세
- Action Templates (행동 템플릿) 정의: 연구자가 원하는 텍스트의 특징(예: 논증 구조, 콘텐츠 주제)을 식별한 후, 이를 모델이 수행할 수 있는 구체적인 행동 양식으로 변환하여 정의합니다. 이는 모델이 다음 단계의 사고를 전개할 때 따라야 할 가이드라인이 됩니다.
- STAT Controller (STAT 컨트롤러) 메커니즘: 추론 과정의 각 단계에서 STAT 컨트롤러가 상황에 맞는 적절한 행동 템플릿을 선택하고 적용합니다. 이를 통해 모델이 단순히 확률적으로 다음 단어를 예측하는 것이 아니라, 구조화된 틀 안에서 사고를 전개하도록 유도합니다.
- 평가 메트릭과 연계: 출력물의 평가 지표를 수집하고, 이가 어떤 행동 선택과 연관되는지 분석하여 템플릿을 지속적으로 정교화합니다.
핵심 기법
가장 중요한 점은 ‘추상적인 원하는 스타일’을 ‘구체적인 행동 템플릿’으로 번역하는 과정입니다. 예를 들어 “공감 어조로 작성하라”는 추상적인 지시 대신, “독자의 경험을 언급하는 문장을 삽입하라”는 구체적인 템플릿을 제시하여 모델이 정확히 무엇을 해야 할지 알게 만드는 것이 핵심입니다.
📊 정량적 결과
주요 성과
- 제공된 논문 초록에는 구체적인 수치적인 개선 폭(예: 정확도 % 상승)이 명시되어 있지 않으나, 기존 고온 샘플링 기반 방식이 달성하지 못한 ‘의미 있는 출력 다양성’과 ‘해석 가능한 제어’를 동시에 달성했다고 주장합니다.
- 연구자가 관심 있는 차원(예: 설득력을 위한 수사학적 구조)을 따라 텍스트를 체계적으로 변화시키면서도 응집성과 품질을 유지하는 데 성공했습니다.
🚀 기존 대비 개선점
- 단순 무작위성이 아닌 의도적이고 구조화된 다양성 생성 가능
- 텍스트가 생성되는 과정을 해석하고 제어 가능 (Inference-Time-Compute의 활용도 증대)
- 주관적인 작업(창작, 설득 등)에서 연구자가 원하는 특정 스타일이나 주제를 반영하여 출력 가능
🎯 활용 분야
- 설득력 있는 글쓰기 연구: 특정 수사학적 구조나 주제가 사람들의 믿음 변화에 미치는 영향을 연구할 때, 해당 변수만 체계적으로 조절하여 텍스트 생성
- 창의적 글쓰기: 독자의 선호도를 만족시키면서도 다양한 스타일과 줄거리를 가진 고품질 스토리 생성
- LLM (대규모 언어 모델) 추론 제어: 모델이 복잡한 문제를 해결할 때, 특정 추론 경로나 스타일로 사고하도록 유도하여 신뢰성 높은 답변 도출
한계 및 주의사항
- 제공된 텍스트에는 저자가 언급한 기술적 한계점이 직접적으로 포함되어 있지 않으나, ‘행동 템플릿’을 사전에 정의하고 설계하는 데 있어 도메인 전문가의 개입이나 상당한 설계 비용이 들 수 있다는 점은 예상되는 한계입니다.
- 해당 기술은 특허 출원(Patent Application)이 진행 중인 상태이므로, 상업적 활용 시에는 라이선스 확인이 필요할 수 있습니다.
5. Query as Anchor: Scenario-Adaptive User Representation via Large Language Model
arXiv: 2602.14492 | 기관: Ant Group | ⬆️ 15 | ⭐ 2 📊 순위선정 | 📄 HTML 태그:
user-representationllmquery-conditioningsoft-promptmultimodal-learningrecommendation-systemadaptive-embedding사전 지식: User Representation Learning, Large Language Models (LLM), Soft Prompt Tuning, Multi-modal Learning, Contrastive Learning (대조 학습)
한 줄 요약
정적이고 단일한 사용자 임베딩의 한계를 극복하여, 쿼리(Query)를 기준으로 상황에 맞게 동적으로 변하는 적응형 사용자 표현 프레임워크를 제안함으로써 실제 산업 환경에서의 요구사항 다양성 문제를 해결했습니다.
💡 핵심 아이디어
사용자를 설명하는 프로필을 마치 ‘수하물’이라고 가정해 봅시다. 기존 방식은 여행지가 어디든 무조건 똑같은 가방을 싸서 주는 방식이라면, 이 논문의 방식은 ‘여행지(쿼리)‘를 물어보면 그 상황에 딱 맞는 옷가지만 뽑아서 가방을 싸주는 전문 개인 스타일러와 같습니다. 즉, 사용자의 고정된 특성만 보는 것이 아니라, 지금 수행하려는 작업(쿼리)을 기준점(Anchor)으로 삼아 사용자의 다양한 행동 데이터 중 필요한 정보만 동적으로 조합해 표현합니다.
문제 정의
기존의 사용자 표현 학습(User Representation Learning) 방식들은 주로 정적이고 특정 작업에만 최적화된 임베딩(Embedding, 데이터를 벡터 공간에 매핑한 것)을 생성합니다. 이로 인해 추천, 마케팅, 리스크 관리 등 서로 다른 목적을 가진 다양한 비즈니스 시나리오에서 하나의 모델을 유연하게 사용하기 어렵습니다. 또한, 텍스트, 거래 내역, 검색 기록 등 서로 다른 성격을 가진 이종(Heterogeneous)의 데이터를 결합할 때 발생하는 잡음(Noise)과 모달리티 간 충돌 문제로 인해 표현의 정확도가 떨어지는 문제가 있었습니다.
🔬 방법론 상세
- UserU 데이터셋 구축: 대규모 사전 학습을 위해 과거 90일간의 사용자 행동(결제, 미니 프로그램 이용, 검색어 등)을 포함한 멀티모달(Multi-modal, 여러 형태의 데이터를 통합) 프로필을 구축했습니다. 여기에 규칙 기반의 미래 행동 예측과 LLM이 생성한 사용자 질의응답(QA)을 결합하여 시간적 동태와 의미적 이해를 데이터에 주입했습니다.
- Q-Anchor 임베딩 아키텍처: 서로 다른 유형의 사용자 행동 데이터를 각각 전용 인코더(gte-base 등)로 처리한 후, 이를 통합하여 백본 LLM(Qwen2.5)에 입력합니다. 이때 단순히 데이터를 합치는 것이 아니라, 쿼리(Query)를 중심축(Anchor)으로 삼아 이질적인 데이터들을 정렬(Alignment)합니다.
- 소프트 프롬프트 튜닝(Soft Prompt Tuning): 전체 모델을 재학습시키는 대신, 학습 가능한 적은 수의 토큰(예: 6개)을 추가하여 하류 작업에 맞게 모델을 효율적으로 미세 조정합니다. 이를 통해 ‘시맨틱 리-앵커링(Semantic Re-anchoring)‘을 수행하여 모달리티들이 하류 의사결정 경계에 맞춰 재조정되도록 합니다.
핵심 기법
**쿼리 기반 앵커링(Query-as-Anchor)**이 핵심입니다. 사용자 벡터를 고정된 값으로 만드는 대신, “지금 이 사용자가 무엇을 원하는가?”라는 질문(Query)에 따라 사용자의 정보를 해석하는 기준점(Anchor)을 이동시킵니다. 예를 들어, 같은 사용자라도 ‘할인 쿠폰 검색’을 했을 때와 ‘투자 상품 조회’를 했을 때, 시스템이 바라보는 사용자의 임베딩은 완전히 다른 방향으로 조정되어 각 상황에 최적화된 응답을 가능하게 합니다.
📊 정량적 결과
주요 성과
- 총 10개의 실제 벤치마크 데이터셋과 2개의 온라인 A/B 테스트를 수행한 결과, 기존的一般 텍스트 임베딩 모델 및 최신 모델들 대비 전반적으로 우월한 성능을 보여주었습니다. - (구체적인 개선 수치는 제공된 텍스트에 명시되지 않았으나, 전반적인 성능 우위와 온라인 테스트 통과를 주요 성과로 언급함)
- 기존 강력한 베이스라인인 Qwen2.5, KaLM-Embedding 등과 비교하여 하류 작업 적응력 면에서 월등한 효율성을 입증했습니다.
🚀 기존 대비 개선점
- 상황 적응성: 기존의 정적인 임베딩 방식이 다양한 비즈니스 시나리오에 유연하게 대처하지 못하는 문제를 해결하여, 하나의 모델로 여러 작업을 수행할 수 있게 되었습니다.
- 데이터 통합 효율성: 텍스트, 정형 데이터, 행동 로그 등 이질적인 데이터를 쿼리를 중심으로 정렬하여, 데이터 간의 충돌과 잡음을 최소화하고 의미 있는 표현으로 증류(Distill)했습니다.
- 운영 효율성: 여러 개의 작업 특화 모델을 유지하던 기존 시스템의 복잡성과 배포 오버헤드를 줄일 수 있습니다.
🎯 활용 분야
- 개인화된 추천 시스템: 사용자의 현재 검색이나 상황에 따라 추천 아이템의 순위를 동적으로 조정.
- 디지털 마케팅: 사용자의 과거 구매 내역뿐만 아니라 현재 의도(Query)를 반영한 맞춤형 광고 제공.
- 리스크 관리: 사용자의 일반적인 행동 패턴과 특정 거래 시도의 문맥을 비교하여 실시간 사기 탐지 등에 활용.
한계 및 주의사항
- 제공된 본문 요약에서는 명시적인 한계점을 언급하지 않았으나, 일반적으로 멀티모달 데이터를 통합할 때 각 모달리티(텍스트, 테이블 등)의 인코더를 유지해야 하므로 시스템 전체의 복잡도가 다소 높을 수 있습니다.
- 또한, 백본으로 사용하는 LLM의 용량(Qwen2.5-0.5B)이나 추론 비용 등이 실시간 서비스에 미치는 영향에 대한 고려가 필요할 수 있습니다.
6. BitDance: Scaling Autoregressive Generative Models with Binary Tokens
arXiv: 2602.14041 | ⬆️ 15 | ⭐ 109 🤖 GLM추천 | 📕 PDF 태그:
ai-paperml
❌ 분석 실패: Post “https://api.z.ai/api/coding/paas/v4/chat/completions”: unexpected EOF
7. Nanbeige4.1-3B: A Small General Model that Reasons, Aligns, and Acts
arXiv: 2602.13367 | 기관: Nanbeige LLM Lab | ⬆️ 13 🤖 GLM추천 | 📄 HTML 태그:
slmnllmagentrlhfcode-generationreasoningmodel-optimizationnanbeige사전 지식: Small Language Model (SLM), Reinforcement Learning from Human Feedback (RLHF), Reward Modeling (보상 모델링), Agentic Behavior (에이전트 행동), Alignment (정렬)
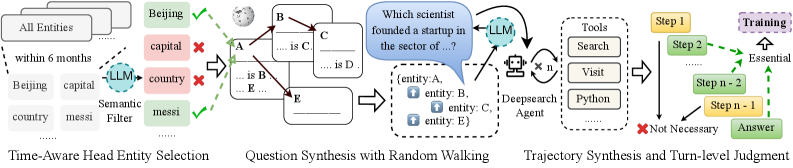
한 줄 요약
30억 개의 작은 파라미터로도 추론, 코딩, 에이전트 행동을 모두 수행하는 최초의 통합형 오픈소스 모델을 구현하여, 큰 모델에 의존하던 에이전트 및 복잡한 작업 수행의 경제성과 효율성을 획기적으로 개선했기 때문에 중요합니다.
💡 핵심 아이디어
마치 ‘스위스 아미 나이프(Swiss Army Knife)‘와 같습니다. 기존의 작은 언어 모델(SLM)들은 계산기나 가위 같은 단순한 도구 하나에만 특화되어 있었지만, 이 모델은 계산, 코드 작성, 복잡한 계획 수립 기능을 하나의 작은 몸체에 통합하여, 큰 도구(거대 모델)를 들지 않고도 다양한 문제를 해결할 수 있게 만들었습니다.
문제 정의
소형 언어 모델(SLM)들은 보통 수학이나 코드 같은 특정 분야에서만 강점을 보이고, 도구를 여러 번 사용해야 하는 복잡한 상황(Long-horizon interactions)이나 창의적인 글쓰기 같은 일반적인 추론 능력은 부족했습니다. 이 논문은 “도대체 30억 파라미터(3B) 모델을 얼마나 강력한 올라운더(Generalist)로 키울 수 있을까?”라는 질문에 답하고자 합니다.
🔬 방법론 상세
- 결합형 보상 모델링 (Point-wise and Pair-wise Reward Modeling): 단순히 답변이 맞는지 틀리는지(Point-wise)만 보는 것이 아니라, 두 답변 중 어느 쪽이 더 나은지(Pair-wise) 비교하는 방식을 섞어 사용했습니다. 이를 통해 모델이 정답을 맞히는 것뿐만 아니라 인간이 더 선호하는 답변을 생성하도록 정렬(Alignment)했습니다.
- 복잡도 인지 강화학습 (Complexity-aware Rewards in RL): 코드 생성 과정에서 단순히 ‘돌아가는 코드’를 작성하는 것에 그치지 않고, 알고리즘의 효율성(시간 복잡도 등)까지 고려하여 보상(Reward)을 설계했습니다. 즉, 정답이더라도 비효율적인 코드는 벌점을 받고, 깔끔한 코드는 보상을 받도록 학습했습니다.
- 턴 수준 감독 (Turn-level Supervision): 검색이나 계산 등 여러 단계가 필요한 복잡한 작업(Deep Search)을 학습할 때, 전체 과정이 끝났을 때만 평가하는 것이 아니라 대화의 각 단계(Turn)마다 올바른 행동을 취했는지 감독 신호를 주어 학습 안정성을 높였습니다.
핵심 기법
이 논문의 가장 큰 힘은 **‘하이브리드 피드백(Hybrid Feedback)‘**에 있습니다. 마치 학생을 가르칠 때 단답형 채점(O/X)만 하는 것이 아니라, 서로 다른 답안을 비교해 어떤 것이 더 논리적인지 설명해주는 튜터링(Tutoring)을 병행한 것과 같습니다. 이를 통해 모델은 단순한 사실 암기를 넘어, 인간의 기준에 맞는 훨씬 더 섬세한 추론 능력을 갖추게 되었습니다.
📊 정량적 결과
주요 성과
- Nanbeige4.1-3B는 유사한 크기의 작은 모델(SLM)들을 다양한 벤치마크에서 지속적으로 능가했습니다.
- 더 큰 파라미터를 가진 기본 모델(Baselines)과 비교해도 경쟁력 있는 성능을 보여주며, LiveCodeBench, GPQA, Arena-Hard-V2 등 코드, 과학, 정렬 영역에서 두각을 나타냈습니다.
🚀 기존 대비 개선점
- 통합성: 기존 SLM들이 가졌던 조각난 능력(Fragmented capabilities)을 하나의 모델 안에서 추론, 코딩, 도구 사용 능력으로 통합했습니다.
- 정렬 및 품질: Point-wise와 Pair-wise 방식을 결합하여 일반적인 대화 및 창의적 글쓰기에서 인간의 선호도를 더 잘 반영하는 고품질 답변 생성이 가능해졌습니다.
- 코드 효율성: 단순히 코드가 작동하는지를 넘어, 복잡도를 고려한 효율적인 알고리즘을 작성하도록 최적화되었습니다.
🎯 활용 분야
- 온디바이스 AI 에이전트: 개인정보 보호가 중요한 로컬 기기에서 작동하면서도 검색, 계획 수립 등 복잡한 작업을 수행하는 스마트 비서.
- 효율적인 코딩 어시스턴트: 단순한 코드 생성을 넘어, 최적화된 알고리즘을 제안하여 개발자의 생산성을 높이는 도구.
- 교육용 튜터링 봇: 수학이나 과학 문제를 풀면서 과정을 단계별로 설명하고 추론할 수 있는 저비용 교육 AI.
한계 및 주의사항
- 저자들은 모델의 효율성을 더 높이기 위해, 더 짧은 출력과 더 적은 도구 호출로 문제를 해결할 수 있도록 만드는 것이 향후 과제라고 언급했습니다.
- 현재 성능이 큰 모델과 경쟁적이긴 하지만, 아주 복잡한 연구 에이전트 시나리오에서는 아직 한계가 있을 수 있어 추가적인 아키텍처 혁신이 필요합니다.
8. Learning to Configure Agentic AI Systems
arXiv: 2602.11574 | 기관: LENS Lab | ⬆️ 6 | ⭐ 2 🤖 GLM추천 | 📄 HTML 태그:
agentic-aireinforcement-learningllmconfiguration-optimizationefficiencyhierarchical-policyresource-allocationreasoning사전 지식: Large Language Models, Reinforcement Learning, Multi-Agent Systems, Prompt Engineering, Fine-tuning

한 줄 요약
복잡한 에이전트 시스템의 구성 방식을 고정된 휴리스틱(Heuristic)에서 벗어나, 강화 학습을 통해 각 질의의 난이도에 맞춰 도구와 워크플로우를 동적으로 최적화하여 비용 효율성과 성능을 동시에 극대화하는 방법론을 제시했기 때문에 중요합니다.
💡 핵심 아이디어
스마트한 프로젝트 매니저가 업무의 난이도에 따라 팀 구성과 예산을 달리 배정하는 것과 같습니다. 쉬운 단순 연산 문제에는 적은 인원과 간단한 도구를 할당하고, 복잡한 분석 문제에는 정예 요원과 고가의 장비를 배치하듯, ARC는 입력된 질문에 따라 LLM(Large Language Model) 에이전트가 사용할 도구, 토큰 예산, 워크플로우를 자동으로 맞춤 설정합니다.
문제 정의
기존의 LLM 기반 에이전트 시스템은 모든 질문에 대해 동일한 무거운 설정(방대한 맥락, 복잡한 검증 루프 등)을 적용하는 “원 사이즈 피츠 올(One-size-fits-all)” 방식을 사용했습니다. 이는 단순 질문에도 불필요한 연산 자원을 낭비하게 만들고, 긴 맥락(Long Context) 처리로 인해 정보를 놓치는 “로스트 인 더 미들(Lost-in-the-middle)” 현상을 유발하여 성능을 저하시키는 문제가 있었습니다.
🔬 방법론 상세
- 계층적 정책(Hierarchical Policy) 학습: 방대한 조합 설계 공간(Workflow, Tool, Budget, Prompt)을 탐색하기 위해 정책 $\pi$를 두 개의 수준으로 분해하여, 상위 수준에서는 대략적인 방향을 결정하고 하위 수준에서는 구체적인 설정을 결정하는 계층적 구조를 사용합니다.
- 효용 함수(Utility Function) 최적화: 정확도와 비용의 균형을 맞추기 위해 다음과 같은 보상(Reward) 함수를 정의하고 이를 최대화하는 방향으로 학습합니다. $$U(q,c) = \mathbb{I}[\hat{a}=a] - \lambda C_{\text{cost}}(c)$$ 여기서 $\mathbb{I}$는 정답 여부(0 또는 1), $\lambda$는 비용 중요도 가중치, $C_{\text{cost}}$는 토큰 사용량 및 실행 시간 등의 계산 비용입니다.
- 마스킹된 강화 학습(Masked RL)과 SFT 결합: 불가능하거나 의미 없는 설정의 탐색을 제한(Masking)하여 학습 효율을 높이고, 강화 학습으로 탐색한 후 높은 보상을 받은 설정들을 지도 학습(Supervised Fine-Tuning)으로 정제하여 정책을 안정화합니다.
핵심 기법
가장 중요한 기법은 **질의별 적응형 구성(Query-wise Adaptive Configuration)**입니다. 이는 모든 질문에 똑같은 복잡한 에이전트 시스템을 돌리는 대신, 질문이 들어오면 그 즉시 해당 질문을 풀기에 가장 적절한 “가벼운” 설정인지 아니면 “무거운” 설정인지를 판단하여 동적으로 에이전트의 구조를 바꿔서 실행하는 기술입니다.
📊 정량적 결과
주요 성과
- 이전 방식 대비 최대 **16% 더 높은 정확도(Accuracy)**를 기록했습니다.
- 불필요한 토큰 사용을 최소화하여 **계산 효율성(Computational Efficiency)**을 크게 개선했습니다.
- 추론(Reasoning) 및 도구 사용(Tool-Use)을 포함한 다양한 벤치마크(GSM8k, HotPotQA, GAIA 등)에서 기존 수작업 기반 및 기타 RL 기반 방법론을 지속적으로 능가했습니다.
🚀 기존 대비 개선점
- 자원 효율성: 쉬운 질문에는 가벼운 워크플로우를, 어려운 질문에는 집중적인 자원을 할당하여 연산 비용과 지연 시간(Latency)을 절감합니다.
- 성능 안정성: 긴 맥락 처리로 인한 성능 저하 현상을 방지하고, 상황에 맞는 최적의 프롬프트와 도구를 선택하여 답변의 정확도를 높입니다.
- 자동화: Grid Search나 Greedy Search처럼 사람이 직접 조합을 찾는 것이 아니라, 에이전트가 스스로 최적의 구성을 학습하여 찾아냅니다.
🎯 활용 분야
- 복잡한 도구 검색이 필요한 지능형 검색 엔진
- 비용 효율성이 중요한 기업용 고객 센터 봇
- 수학적 추론이나 의료 진단 등 난이도가 들쭉날쭉한 문제를 해결하는 전문가 AI 시스템
한계 및 주의사항
- 제공된 본문에는 명시적인 한계점이 상세히 나와 있지 않으나, 일반적으로 이러한 접근 방식은 정책(Policy)을 학습하기 위한 초기 데이터셋이 필요하며, 강화 학습 과정 자체가 추가적인 학습 비용과 시간을 소모할 수 있습니다.
- 완전히 새로운 도구나 도메인이 추가될 경우, 정책이 이를 반영하도록 재학습하거나 파인 튜닝(Fine-tuning)해야 할 수 있습니다.
9. MoRL: Reinforced Reasoning for Unified Motion Understanding and Generation
arXiv: 2602.14534 | 기관: Peking University | ⬆️ 2 | ⭐ 1 🤖 GLM추천 | 📄 HTML 태그:
motion-generationmotion-understandingreinforcement-learningchain-of-thoughtmultimodal-llmhuman-motion-analysisvqvae사전 지식: 멀티모달 대규모 언어 모델(Multimodal Large Language Model), 강화학습(Reinforcement Learning), Chain-of-Thought 프롬프팅, 변분 오토인코더(Variational Autoencoder, VAE), SMPL-X

한 줄 요약
이 논문이 중요한 이유는, 강화학습과 단계별 추론 기법을 통해 인간 동작의 이해와 생성이라는 두 과제를 하나의 모델로 통합하고, 논리적 일관성과 물리적 현실감을 동시에 크게 향상시켰기 때문입니다.
💡 핵심 아이디어
MoRL은 마치 전문 무용수이자 안무가와 같습니다. 단순히 특정 춤을 추거나(생성), 어떤 춤인지 설명하는(이해) 것을 넘어, 왜 그 동작을 해야 하는지, 그리고 다음 동작으로 어떻게 자연스럽게 연결해야 하는지를 단계별로 설명하고 계획할 수 있습니다. 이처럼 ‘생각의 사슬(Chain-of-Thought)‘을 동작에 적용하여, 더 합리적이고 사실적인 움직임을 만들어냅니다.
문제 정의
기존 인간 동작 모델들은 움직임을 생성하거나 이해하는 능력은 있었지만, 복잡한 맥락에서 추론(reasoning)하거나, 실행 시점(test-time)에 단계적으로 계획(planning)하는 능력이 부족했습니다. 예를 들어, “공중제비를 돌며 착지하는” 동작을 만들 때, ‘왜’ 팔을 벌려야 공중에서 균형을 잡는지, ‘어떻게’ 착지 충격을 줄이는지에 대한 논리적 연결이 약했습니다.
🔬 방법론 상세
- 통합 멀티모달 모델 (Unified Multimodal Model): 텍스트와 동작을 함께 처리하는 단일 대규모 언어 모델(MLLM) 기반으로, 동작 이해와 생성을 하나의 프레임워크에서 수행합니다. Qwen3-4B-Instruct를 기반 모델로 사용합니다.
- 두 단계 학습 전략:
- 지도 학습 미세조정 (Supervised Fine-Tuning, SFT): Gemini-2.5-pro를 이용해 만든 대규모 ‘사고의 사슬(Chain-of-Thought, CoT)’ 데이터셋(MoUnd-CoT-140K, MoGen-CoT-140K)으로 모델의 초기 추론 능력을 학습시킵니다.
- 과업별 강화학습 (Task-Specific Reinforcement Learning, RL): 동작 이해에는 ‘의미적 일관성 및 추론의 논리성’을, 동작 생성에는 ‘물리적 타당성 및 텍스트-동작 일관성’을 보상(reward)으로 설계하여, 각 과업에 최적화된 성능을 끌어냅니다.
- Chain-of-Motion (CoM) 추론: 실행 시점에 모델이 동작을 생성하거나 이해할 때, 한 번에 결론 내리는 대신 “1단계: 준비 자세, 2단계: 점프, 3단계: 회전, 4단계: 착지”와 같이 단계별 계획과 반성(reflection) 과정을 거치도록 하는 추론 기법입니다.
핵심 기법
가장 핵심적인 기법은 과업별 맞춤형 보상을 사용하는 강화학습입니다. 동작을 ‘이해’하는 것과 ‘생성’하는 것은 평가 기준이 다릅니다. 이해는 정확한 설명이 중요하고, 생성은 자연스러움이 중요합니다. MoRL은 이 점을 파고들어, 이해 과제에서는 모델의 설명이 얼마나 논리적인지를, 생성 과제에서는 결과물이 물리적으로 가능한지를 각각 다른 보상 함수로 측정하고 개선합니다. 이는 마치 시험을 볼 때, 서술형 문제(이해)와 실기 평가(생성)를 각각 다른 채점 기준으로 평가하는 것과 같습니다.
📊 정량적 결과
주요 성과
- 제공된 논문 전문에는 구체적인 수치(예: FID 10% 향상)가 명시되어 있지 않습니다.
- 다만, HumanML3D와 KIT-ML이라는 동작 분야의 표준 벤치마크에서 기존 최첨단(SOTA) 모델들의 성능을 뛰어넘었다고 주장합니다.
🚀 기존 대비 개선점
- 향상된 추론 능력: 단순 동작 나열을 넘어, 동작 간의 인과관계와 단계별 계획을 포함하는 심층적인 추론이 가능해졌습니다.
- 개선된 물리적 현실감: 강화학습을 통해 물리적으로 불가능하거나 부자연스러운 동작을 줄이고, 실제 사람처럼 자연스러운 움직임을 생성합니다.
- 통합적 접근: 이해와 생성을 별개의 모델로 다루던 기존 방식과 달리, 하나의 모델에서 두 가지를 모두 해결하여 효율성과 일관성을 높였습니다.
🎯 활용 분야
- 캐릭터 애니메이션 및 게임 개발: 텍스트 설명만으로 논리적이고 사실적인 게임 캐릭터의 움직임을 실시간으로 생성할 수 있습니다.
- 로보틱스: 로봇이 인간의 동작을 보고 그 의도를 파악하거나, 복잡한 작업을 여러 단계로 나누어 안전하게 수행하도록 계획하는 데 활용될 수 있습니다.
- 가상 현실(VR) 및 메타버스: 사용자의 텍스트 입력에 따라 아바타가 더 사실적이고 맥락에 맞는 동작을 수행하여 몰입감을 극대화할 수 있습니다.
한계 및 주의사항
- 제공된 논문 전문에는 명시적인 한계점이 언급되어 있지 않습니다. 하지만 다음과 같은 잠재적 한계가 존재할 수 있습니다.
- 합성 데이터 의존성: 대규모 CoT 데이터셋을 인공적으로 생성(synthesis)했기 때문에, 실제 세계의 미묘한 뉘앙스나 데이터에 없는 예외적인 상황에 대한 처리가 부족할 수 있습니다.
- 계산 복잡성: 강화학습 훈련과 Chain-of-Motion 같은 단계별 추론은 많은 계산 자원을 요구하여 실시간 애플리케이션에 적용하기에 부담이 될 수 있습니다.
10. AnchorWeave: World-Consistent Video Generation with Retrieved Local Spatial Memories
arXiv: 2602.14941 | 기관: University of North Carolina at Chapel Hill | ⬆️ 1 | ⭐ 1 🤖 GLM추천 | 📄 HTML 태그:
ai-paperml

❌ 분석 실패: Post “https://api.z.ai/api/coding/paas/v4/chat/completions”: unexpected EOF
📅 생성일: 2026-02-17 | 🤖 GLM-4.7