📚 2026-02-16 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 Less is Enough: Synthesizing Diverse Data in … ⬆️200
- 📊📄 SQuTR: A Robustness Benchmark for Spoken Quer… ⬆️132
- 📊📄 MedXIAOHE: A Comprehensive Recipe for Buildin… ⬆️55
- 📊📄 Zooming without Zooming: Region-to-Image Dist… ⬆️50
- 📊📄 OneVision-Encoder: Codec-Aligned Sparsity as … ⬆️39
- 🤖📄 CoPE-VideoLM: Codec Primitives For Efficient … ⬆️20
- 🤖📄 Intelligent AI Delegation ⬆️10
- 🤖📄 ABot-M0: VLA Foundation Model for Robotic Man… ⬆️9
- 🤖📄 DICE: Diffusion Large Language Models Excel a… ⬆️5
- 🤖📕 Best of Both Worlds: Multimodal Reasoning and… ⬆️2
1. Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs
arXiv: 2602.10388 | ⬆️ 200 | ⭐ 52 📊 순위선정 | 📄 HTML 태그:
llmdata-synthesissparse-autoencoderfeature-engineeringpost-traininginterpretabilityalignmentefficient-ml사전 지식: Sparse Autoencoder, LLM Post-training, Activation Function, Generalization Error, Feature Space

한 줄 요약
대규모 언어 모델의 후속 학습(Post-training) 효율을 획기적으로 높이기 위해, 텍스트의 단순 다양성이 아닌 모델 내부의 해석 가능한 특징 공간(Feature Space)에서의 다양성을 최적화하여 필요한 데이터만을 정교하게 합성하는 새로운 프레임워크를 제안했습니다.
💡 핵심 아이디어
이 논문은 기존의 텍스트 기반 데이터 다양성 측정 방식이 모델의 실제 성능과 직결되지 않는다는 문제를 지적합니다. 마치 요리사가 요리의 맛을 내기 위해 재료의 종류만 나열하는 것이 아니라, 실제 재료가 가진 ‘맛의 성분(예: 짠맛, 단맛, 감칠맛)‘이 균형 잡혀 있는지를 확인해야 하는 것과 같습니다. 연구진은 희소 오토인코더(Sparse Autoencoder)를 사용해 모델이 이해하는 내부 특징(맛의 성분)을 파악하고, 부족한 성분을 채우는 데이터만 인공적으로 생성하여 학습 효율을 극대화합니다.
문제 정의
대규모 언어 모델(LLM)의 성능은 학습 데이터의 다양성(Diversity)에 좌우되지만, 현실적으로 포괄적이고 다양한 데이터를 수집하는 데는 많은 비용이 듭니다. 더 큰 문제는 기존의 다양성 지표(예: 단어의 n-gram, 문장 임베딩 간 거리)가 텍스트의 형식적 차이만 잡아낼 뿐, 모델의 다운스트림 성능을 결정짓는 실제적인 의미 특징(Task-relevant features)을 제대로 반영하지 못한다는 점입니다.
🔬 방법론 상세
- 희소 오토인코더(Sparse Autoencoder, SAE)를 활용한 특징 공간 구축
LLM의 내부 활성화(Activation)를 해석 가능한 k차원의 희소 특징 벡터(z)로 압축하여, 각 차원이 특정한 의미(예: 코드 작성 능력, 공격성 등)를 가지도록 학습합니다.
- 수식: 학습 손실 함수 L_SAE는 재구성 오차와 희소성(Sparsity) 규제 항의 합으로 정의됩니다. ($\mathcal{L}{\mathrm{SAE}}=|\textbf{x}-\hat{\textbf{x}}|{2}^{2}+\lambda,|z|_{1}$)
- 특징 활성화 커버리지(Feature Activation Coverage, FAC) 현재 데이터셋이 모델의 k차원 특징 공간 중 얼마나 많은 영역을 커버하는지를 정량화하는 지표입니다.
- FAC Synthesis 프레임워크
- 시드 데이터셋(Seed Dataset)을 SAE로 분석하여 활성화되지 않은 ‘누락된 특징(Missing features)‘을 식별합니다.
- 모델이 이 누락된 특징을 활성화하도록 유도하는 새로운 샘플을 생성(Synthesize)합니다.
핵심 기법
- SAE(Sparse Autoencoder)를 ‘기능 해석기’로 활용: 모델 내부의 복잡한 신호를 인간이 이해할 수 있는 단위의 특징(Feature)으로 분해하여, 데이터셋이 무엇을 알고 무엇을 모르는지 정확하게 진단합니다.
📊 정량적 결과
- 논문에서는 합성된 데이터가 일반화 오차(Generalization Error)에 미치는 영향을 이론적으로 증명했습니다.
- 정리 4.1 (Generalization Error Upper Bound): 일반화 오차는 ‘타겟 도메인과 합성 데이터 분포 간의 차이(Distribution gap)‘와 ‘합성 데이터 내 샘플링 오차(Sampling error)‘의 합으로 상한선이 설정됩니다. FAC를 통해 특징 공간을 잘 채우면 이 두 항을 모두 줄여 오차를 최소화할 수 있습니다.
주요 성과
- 제공된 전문에 따르면 4가지 대표적인 작업(독성 탐지, 보상 모델링, 행동 조정, 지시 따르기)에서 FAC Synthesis 프레임워크의 효과를 입증했습니다.
- 특히 누락된 특징을 타겟팅하여 데이터를 생성할 때, 기존 균일 샘플링 방식 대비 효율적인 성능 향상을 이끌어냈습니다.
🚀 기존 대비 개선점
- 텍스트 공간(Text space)이 아닌 모델의 특징 공간(Feature space)을 기반으로 데이터 다양성을 최적화하여, 실제 성능 향상에 기여하는 데이터를 선별적으로 생성합니다.
- 불필요한 데이터 생성을 줄임으로써 적은 양의 데이터(Less is Enough)로도 효과적인 후속 학습이 가능하도록 만듭니다.
- 수학적 이론(일반화 오차 상한)에 기반하여 데이터 생성의 타당성을 보장합니다.
🎯 활용 분야
- 지시 미세 조정(Instruction Tuning) 데이터 구축
- 모델의 안전성을 강화하는 정렝(Alignment) 데이터 생성
- 특정 도메인(법률, 의료 등)의 꼬리 부분(Long-tail) 케이스 데이터 증강
한계 및 주의사항
- 희소 오토인코더(SAE)의 품질에 전적으로 의존하므로, SAE가 특징을 제대로 분해하지 못하면 잘못된 특징을 타겟팅하여 데이터를 생성할 수 있습니다.
- 모델이 내부적으로 가진 특징을 완벽하게 해석한다는 가정하에 성립하며, 모델마다 특징 공간이 달라질 수 있습니다.
2. SQuTR: A Robustness Benchmark for Spoken Query to Text Retrieval under Acoustic Noise
arXiv: 2602.12783 | ⬆️ 132 | ⭐ 96 📊 순위선정 | 📄 HTML 태그:
spoken-query-retrievalrobustness-benchmarkasrnoise-robustnessinformation-retrievalaudio-processingevaluation-metrics사전 지식: Automatic Speech Recognition (ASR, 자동 음성 인식), Information Retrieval (IR, 정보 검색), Signal-to-Noise Ratio (SNR, 신호 대 잡음비), Text-to-Speech (TTS, 텍스트 음성 변환), Word Error Rate (WER, 단어 오류율)
한 줄 요약
기존의 깨끗한 데이터로만 평가하던 음성 검색 시스템의 한계를 깨고, 실제 환경의 소음을 반영한 대규모 데이터셋과 평가 프로토콜을 제시하여 시스템의 견고함을 측정할 수 있는 새로운 기준을 마련했습니다.
💡 핵심 아이디어
이전의 음성 검색 연구는 마치 도서관처럼 조용한 방에서만 모델의 능력을 테스트했습니다. 이번 연구는 마치 실제 시험장처럼 지하철 소음이나 카페의 소란스러움을 인위적으로 만들어내어, 시끄러운 환경에서도 검색 시스템이 얼마나 잘 작동하는지를 테스트할 수 있는 ‘소음 방패’를 만든 것과 같습니다.
문제 정의
현실 세계의 음성 검색(Spoken Query Retrieval)은 배경 소음, 환경 간섭, 화자의 다양성 때문에 음성 인식(ASR) 정확도가 떨어지고, 이는 검색 성능 저하로 이어집니다. 하지만 기존 연구는 음성 인식은 단순히 오류율(WER)로만 평가하고, 검색 시스템은 깨끗한 텍스트만으로 평가하는 등 평가가 분리되어 있어 실제 환경에서의 복합적인 성능 저하를 제대로 측정하지 못했습니다.
🔬 방법론 상세
- 대규모 질의 데이터 수집: 자연어 처리 분야에서 널리 쓰이는 6개의 영어 및 중국어 텍스트 검색 벤치마크(예: Natural Questions, HotpotQA 등)에서 총 37,317개의 고유한 질의를 가져와 기반 데이터로 구성했습니다.
- 체계적인 오디오 합성 및 노이즈 주입: 200명의 실제 화자 목소리 프로필을 사용하여 텍스트 질의를 음성으로 변환한 뒤, 17가지 실제 환경 소음(지하철, 식당, 거리 등)을 신호 대 잡음비(SNR, Signal-to-Noise Ratio) 수준에 따라 청정(Clean), 저음(Low, 20dB), 중음(Medium, 10dB), 고음(High, 0dB)의 4단계로 섞어 실험 데이터를 생성했습니다.
- 통합 평가 프로토콜: 어휘 기반(Lexical), 밀집 표현 기반(Dense), 그리고 엔드 투 엔드(End-to-End) 검색 패러다임을 아우르는 통합된 평가框架을 제시하여 다양한 모델 유형을 동일한 조건에서 비교할 수 있게 했습니다.
핵심 기법
가장 중요한 기법은 **제어된 신호 대 잡음비(SNR)를 이용한 데이터 증강(Data Augmentation)**입니다. 단순히 소음을 섞는 것을 넘어, 소음의 세기를 데시벨(dB) 단위로 정밀하게 조절하여 ‘소음이 얼마나 시끄러운지’에 따른 검색 시스템의 성능 변화를 그래프로 그려볼 수 있도록 만든 점이 핵심입니다.
📊 정량적 결과
주요 성과
- 음성 인식 오류율 증가: 고음(High Noise, 0dB) 환경에서 영어는 단어 오류율(WER)이 3.33%에서 7.75%로, 중국어는 문자 오류율(CER)이 2.71%에서 7.14%로 각각 약 2.3배 이상 증가하여 소음에 따라 성능이 급격히 저하됨을 확인했습니다.
- 검색 성능 저하 확인: 음성 인식 오류가 발생하자 이후 단계인 검색(Retrieval) 효율도 소음이 심할수록 일관되게 떨어지는 현상을 포착했습니다.
- 데이터 규모: 총 37,317개의 질의와 200명의 화자, 17개의 환경 소음 조합을 통해 기존 벤치마크보다 훨씬 더 현실적이고 대규모의 실험 환경을 제공합니다.
🚀 기존 대비 개선점
- 실제 음성 검색 서비스에서 발생하는 ‘소음-인식-검색’의 연쇄적인 성능 저하 문제를 종합적으로 분석할 수 있는 환경을 제공합니다.
- 기존에 서로 분리되어 있던 음성 인식(ASR) 평가와 검색(IR) 평가를 하나의 파이프라인에서 통합하여 측정할 수 있게 했습니다.
- 특정 소음 환경(예: 주변 잡음, 차량 소음 등)을 선택적으로 적용해보며 모델의 취약점을 정밀하게 진단할 수 있습니다.
🎯 활용 분야
- 스마트 홈 기기(예: 청소기나 TV 소음이 심한 환경에서의 음성 어시스턴트)
- 차량 인포테인먼트 시스템(예: 고속도로 주행 소음이 있는 상황에서의 내비게이션 검색)
- 야외 및 공공장소 모바일 검색(예: 지하철역이나 번화가에서의 음성 검색 서비스)
한계 및 주의사항
- 이 연구는 텍스트를 인공적으로 음성으로 변환하는 TTS(Text-to-Speech) 기술을 사용했기 때문에, 실제 사용자의 발화 패턴이나 감정 변화 등을 완벽하게 반영하지 못할 수 있습니다.
- 제안된 벤치마크는 여전히 소음 환경에서의 견고함(Robustness)이 크게 개선되지 않았음을 보여주며, 이는 향후 연구를 위한 도전 과제로 남아 있습니다.
3. MedXIAOHE: A Comprehensive Recipe for Building Medical MLLMs
arXiv: 2602.12705 | 기관: ByteDance | ⬆️ 55 📊 순위선정 | 📄 HTML 태그:
medical-aimllmcontinual-pretrainingchain-of-thoughtreinforcement-learningreasoningagent-training사전 지식: Vision-Language Models (VLM), Reinforcement Learning (강화 학습), Chain-of-Thought (사고의 사슬), Long-tail Distribution (롱테일 분포), Entity-aware Pretraining (엔티티 인지 사전 학습)
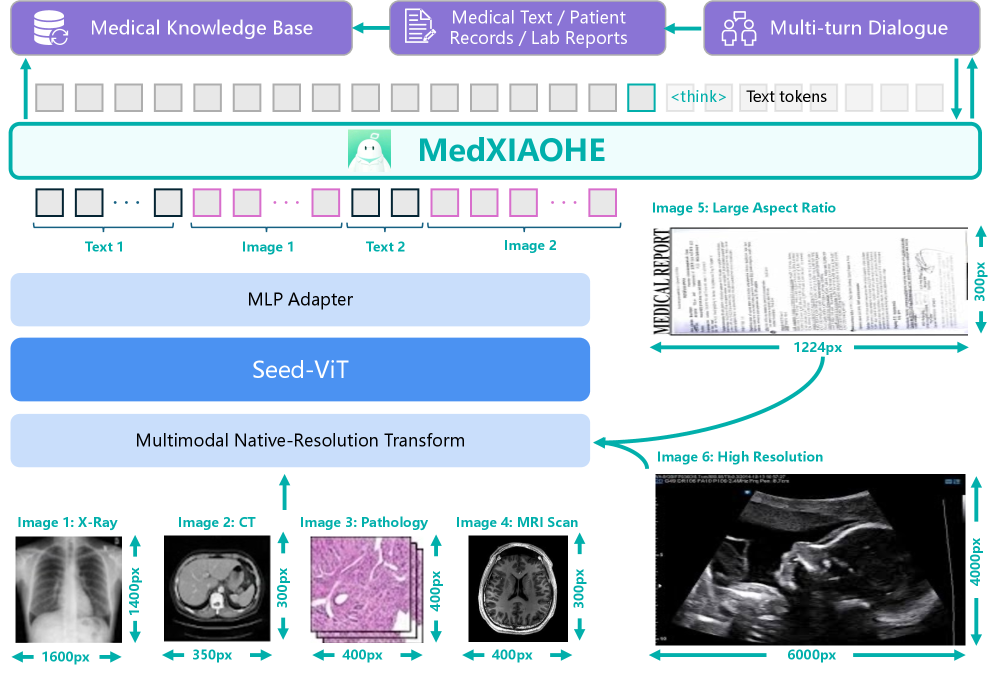
한 줄 요약
의학적 이해와 추론 능력을 극대화하여 실제 임상 환경에서 기존 최고 수준의 폐쇄형 모델을 능가하는 성능을 보여주는 의료용 멀티모달 대규모 언어 모델(MLLM) 구축 방법론을 제시했기에 중요합니다.
💡 핵심 아이디어
마치 의대 도서관의 모든 책을 읽은 기초 지식이 풍부한 인턴에게, 희귀 질환 진료에 특화된 ‘외래 수련’을 시키고 전문의들과 함께 ‘임상 회의(Case Conference)‘를 하며 논리적으로 사고하는 법을 훈련시키는 과정과 같습니다. 이 모델은 단순히 지식을 암기하는 것을 넘어, 진단 도구를 활용하고 근거를 단계적으로 제시하며 복잡한 임상 문제를 해결하는 의사의 사고 방식을 모방하도록 훈련되었습니다.
문제 정의
의학 분야의 인공지능 모델은 희귀 질환(롱테일 데이터)에 대한 지식 부족, 병원마다 다른 이미지 프로토콜 등 이질적인 데이터 처리의 어려움, 그리고 단순한 정보 검색을 넘어선 복합적인 의사결정 추론 능력의 부재라는 실제 임상 적용의 큰 장벽에 직면해 있었습니다.
🔬 방법론 상세
- 엔티티 인지 지속적 사전 학습(Continual Pretraining): 의학 서적, 논문, 웹 데이터 등 총 6,400억 토큰 규모의 거대 데이터를 수집하고, 해시 기반 중복 제거와 모델 기반 품질 필터링을 통해 고품질의 학습 말뭉치를 구축했습니다. 특히 희귀 질환과 같은 롱테일(Long-tail) 지식의 격차를 줄이기 위해 이기적인 의학 데이터를 체계적으로 조직했습니다.
- 미드 트레이닝(Mid-Training) 데이터 구성: 지식 그래프와 다중 에이전트 합의(Multi-agent consensus) 기법을 활용하여 신뢰할 수 있는 의학적 추론 데이터를 합성했습니다. 이를 통해 모델이 단순한 사실 나열을 넘어 인과관계가 valid한 다단계 추론을 할 수 있도록 학습 데이터를 생성했습니다.
- 도구 보강 에이전트 훈련 및 강화 학습: 모델이 시각적 정답(Visual grounding)이나 외부 도구 사용을 결합하여 흐름이 있는 작업을 수행할 수 있도록 훈련했습니다. 또한, 강화 학습(Reinforcement Learning)을 적용하여 모델의 진단적 추론 능력을 고도화하고 검증 가능한 의사결정 경로를 만들었습니다.
핵심 기법
- 이 논문의 가장 독창적인 방법은 ‘미드 트레이닝(Mid-Training)’ 단계입니다. 기존에는 사전 학습 바로 파인 튜닝을 진행했다면, 이 논문에서는 그 사이에 별도의 단계를 두어 ‘원자적 결합 기술(Atomic Combinational Skills)‘을 개발합니다. 예를 들어, 눈으로 보고(Visual grounding) 손으로 검색하고(Tool use) 머리로 판단하는(Reasoning) 과정을 하나의 워크플로우로 통합하여 연결하는 훈련을 시키는 것이 핵심입니다.
📊 정량적 결과
주요 성과
- 총 6,400억 토큰의 방대한 데이터를 정제하고 학습에 활용했습니다.
- 다양한 의학 벤치마크에서 최첨안(SOTA) 성능을 달성했습니다.
- 여러 가지 능력에서 최고 수준의 폐쇄형 멀티모달 시스템을 능가하는 성과를 보여주었습니다.
🚀 기존 대비 개선점
- 이기적인 의학 말뭉치를 체계적으로 정리하여 희귀 질환 등 롱테일 영역의 지식 격차를 획기적으로 줄였습니다.
- 단순 정보 검색에서 벗어나 다단계 임상 추론이 가능하도록 추론 능력을 강화했습니다.
- 검증 가능한 의사결정 흔적(Verifiable decision traces)을 제공하여 진단 과정의 투명성과 신뢰성을 높였습니다.
🎯 활용 분야
- 실제 임상 현장에서의 복합적인 진단 보조 시스템(Diagnostic Decision Support)
- 희귀 질환 및 비정형적인 증상이 포함된 복잡한 임상 케이스 분석
- 영상 의학(Radiology) 및 병리(Pathology) 보고서 자동 생성 및 검토
한계 및 주의사항
- 제공된 텍스트에서 구체적인 실패 사례나 한계점은 명시되지 않았으나, 서론에서 언급된 바와 같이 실제 임상 적용 시에는 모델의 안정성과 다양한 환경에서의 일관된 거동 유지가 여전히 중요한 과제로 남아 있습니다.
- 의학적 환각(Hallucination) 가능성과 오판으로 인한 임상적 위험성에 대해 지속적인 모니터링이 필요합니다.
4. Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception
arXiv: 2602.11858 | 기관: inclusionAI | ⬆️ 50 | ⭐ 55 📊 순위선정 | 📄 HTML 태그:
multimodal-llmknowledge-distillationcomputer-visionfine-grained-perceptionefficient-inferenceregion-to-imagerlhfvqa사전 지식: Vision Transformer(ViT), Knowledge Distillation(지식 증류), Multimodal Large Language Models(MLLM), Reinforcement Learning(강화 학습), Fine-grained Visual Categorization(세밀한 시각적 분류)

한 줄 요약
이 논문은 추론 시간에 느린 도구 호출 없이도 학습 단계에서 ‘확대’ 기능을 내재화하여, 멀티모달 대규모 언어 모델이 단 한 번의 순방향 전달(forward pass)만으로 미세한 시각 정보를 정확하게 파악할 수 있게 했다는 점에서 매우 중요합니다.
💡 핵심 아이디어
마치 현미경을 통해 세균을 관찰한 경험이 풍부한 과학자가, 나중에는 육안으로도 아주 작은 세균을 식별해내는 것과 비슷합니다. 기존에는 모델이 사진을 볼 때마다 매번 도구를 써서 확대를 했다면, 이번 방법은 학습할 때 확대해서 본 경험을 뇌(모델 가중치)에 새겨두어, 실행 시에는 도구 없이도 그 세밀한 부분을 기억해내는 방식입니다.
문제 정의
최신 멀티모달 대규모 언어 모델(MLLM)은 전반적인 그림을 잘 이해하지만, 아주 작은 텍스트나 미묘한 속성처럼 결정적인 증거가 작은 경우(Fine-grained perception)에는 전체 맥락에 묻혀 잘 인식하지 못하는 문제가 있습니다. 최근 이를 해결하기 위해 추론 단계에서 관심 영역을 반복해서 확대해서 보는 ‘Thinking-with-Images’ 방식이 등장했지만, 이는 도구를 여러 번 호출하고 영상을 다시 인코딩해야 하므로 속도가 느리다는 치명적인 단점이 있었습니다.
🔬 방법론 상세
- Region-to-Image Distillation (R2I): 이 핵심 기법은 확대 기능을 추론 시 도구가 아니라 학습 시 원칙(Primitive)으로 변환합니다. 먼저 이미지의 아주 작은 영역(Micro-crop)을 잘라내어 강력한 교사 모델이 이를 보고 고품질의 시각적 질의응답(VQA) 데이터를 생성합니다. 그런 다음 이 지역 기반의 감독 신호를 전체 이미지로 증류(Distillation)하여 학생 모델이 전체 이미지를 보면서도 작은 영역의 정보를 추론할 수 있도록 훈련시킵니다.
- Box-overlay Grounding과 Augmented Prompt: 증류 과정에서 학생 모델은 전체 이미지와 함께 해당 작은 영역을 표시하는 경계 상자(박스) 오버레이를 입력받고, 영역에 대한 정보가 추가된 프롬프트를 통해 학습합니다. 이를 통해 모델은 도구 없이도 전역 맥락 속에서 미세한 증거를 찾아내는 능력을 갖추게 됩니다.
- DAPO를 활용한 강화 학습: 모델은 Qwen 시리즈를 기반으로 하며, 74K개의 합성 데이터만 사용하여 감독 미세 조정(SFT) 없이 강화 학습(DAPO)으로만 최적화되었습니다.
핵심 기법
Region-to-Image Distillation은 ‘큰 그림 속 작은 디테일을 보는 눈’을 훈련시키는 과정입니다. 모델에게 사진 전체를 보여주면서, 마치 그 부분을 확대해서 본 것처럼 행동하도록 가중치를 조정하는데, 이때 교사 모델이 확대해서 본 내용을 정답지로 활용하여 모델이 전체 이미지를 한 번에 처리할 때도 그 디테일을 놓치지 않도록 만듭니다.
📊 정량적 결과
제공된 논문 전문에는 구체적인 백분율 수치(예: 정확도 5.3% 상승 등)는 명시되어 있지 않지만, 다음과 같은 정량적 실험 설정과 결과를 확인할 수 있습니다.
- 학습 데이터: 단 74K개의 합성 데이터만을 사용하여 모델을 훈련시켰습니다.
- 모델: Qwen3-VL-4B, Qwen2.5-VL-7B, Qwen3-VL-8B 모델이 ZwZ(Zooming without Zooming)로 최적화되었습니다.
- 성능 비교: GPT-5.1이나 Gemini-3-Flash 같은 폐쇄형 최신 모델 및 다양한 오픈 소스 기반선 모델, 그리고 도구를 사용하는 에이전트 방식(Agentic tool-use)과 비교했습니다.
주요 성과
- 다양한 벤치마크(HR-Bench, VStar, CV-Bench 등)에서 일관되게 세밀한 인식 성능을 향상시켰습니다.
- 추론 비용(Inference cost)을 획기적으로 낮추면서도 도구를 사용하는 기존 방식보다 더 우수한 성능을 보였습니다.
🚀 기존 대비 개선점
- 추론 속도 획기적 개선: 도구를 호출하고 영상을 다시 인코딩하는 반복적인 과정을 없애, 단 한 번의 순방향 전달(Single-pass)로 답을 구할 수 있어 실시간 사용이 가능해졌습니다.
- 효율적인 학습: 거대한 데이터셋이 필요 없이 74K개의 합성 데이터와 지식 증류 기법만으로도 세밀한 인식 능력을 획득할 수 있었습니다.
🎯 활용 분야
- 의료 영상 분석: 엑스레이나 MRI 등 아주 작은 병변을 놓치지 않고 빠르게 탐지해야 하는 분야
- 문서 및 광고 자동화: 아주 작은 글씨가 포함된 계약서나 상세 이미지에서 텍스트를 추출하는 OCR 작업
- 보안 및 감시: 많은 인파 속에 숨어 있는 작은 물체나 특정 인물의 미세한 특징을 실시간으로 식별
한계 및 주의사항
- 이 논문에서 언급된 한계점은 명시적으로 제시되어 있지 않으나, 전체 이미지에서 작은 영역을 찾아내는 능력이 학습 데이터에 의존적일 수 있으므로, 학습에 포함되지 않은 매우 희귀한 패턴에 대한 인식은 여전히 어려울 수 있습니다. 또한, 합성 데이터의 품질이 모델 성능에 직접적인 영향을 미치므로 교사 모델의 능력이 중요합니다.
5. OneVision-Encoder: Codec-Aligned Sparsity as a Foundational Principle for Multimodal Intelligence
arXiv: 2602.08683 | 기관: LMMs-Lab | ⬆️ 39 | ⭐ 225 📊 순위선정 | 📄 HTML 태그:
onevision-encodervideo-understandingmultimodal-intelligencecodec-alignmentsparse-computingcomputer-visionpretrainingdata-efficiency사전 지식: Video Codecs (H.264/HEVC), I-frames and P-frames, Sparse Computing (희소 연산), Transformer, Contrastive Learning (대조 학습)

한 줄 요약
비디오 데이터가 가진 본질적인 중복성을 코덱 구조와 정렬하여 불필요한 연산을 제거함으로써, 효율적이고 확장 가능한 다중 모odal 인텔리전스를 구현한 새로운 패러다임을 제시했기 때문에 중요합니다.
💡 핵심 아이디어
이 논문은 비디오 대부분이 변하지 않는 배경(정보)이고 일부분만 움직임(의미)이라는 점에 착안했습니다. 마치 영상 압축 기술인 코덱이 움직이는 부분만 간신히 저장하듯, 인공지능 모델도 모든 픽셀을 똑같이 보는 대신 움직이는 부분에 집중하게 만들어 연산량을 획기적으로 줄이자는 것이 핵심입니다.
문제 정의
현재의 비전 모델들은 비디오의 모든 픽셀을 균등하게 처리합니다. 하지만 비디오 신호는 시간적으로 매우 중복되어 있으며, 의미 있는 정보는 움직임이나 잔차(residual)처럼 드물게(sparse) 나타납니다. 모델이 변화가 없는 정적인 배경 처리에 엄청난 컴퓨팅 자원을 낭비하고 있다는 것이 이 논문이 해결하고자 하는 핵심 문제입니다.
🔬 방법론 상세
- 코덱 정렬 패치화(Check Aligned Patchification): HEVC 스타일의 GOP(Group of Pictures) 구조를 차용하여, 모든 정보를 담은 I-프레임(I-frame, 완전한 공간 문맥 제공)과 예측 가능한 P-프레임(P-frame, 시간적 중요 영역만 선택)으로 구분하여 처리합니다.
- 대규모 자체 지도 신호 생성: Union-Find 알고리즘으로 데이터 중복을 제거하고, MetaCLIP 모델을 사용하여 이미지를 200만 개의 클래스로 클러스터링하여 정밀한 라벨을 생성합니다.
- 클립 수준의 패치 예산 적용: GOP 단위가 아닌 클립(영상 조각) 전체에 걸쳐 패치 수를 제한하여, 중요한 순간에 자원을 집중시키는 동적 할당을 수행합니다.
핵심 기법
가장 중요한 기법은 시각적 인텔리전스를 예측 압축 문제로 재정의한 것입니다. 단순히 이미지를 있는 그대로 받아들이는 것이 아니라, 이전 프레임을 기반으로 다음 프레임을 예측하고 그 차이(residual)만을 주의 깊게 보는 방식입니다. 이는 우리가 움직이는 물체에 눈을 고정하는 시각 시스템과 유사한 메커니즘을 모델에 심는 것입니다.
📊 정량적 결과
제공된 원문에서는 구체적인 벤치마크 점수(예: 정확도 %)보다는 학습 규모와 구성에 대한 정량적 지표가 강조되었습니다.
주요 성과
- 총 170억 개의 샘플(130억 이미지 + 40억 영상/OCR 데이터)로 모델을 사전 학습
- 200만 개의 클래스를 사용한 세분화된 멀티 라벨링 시스템 구축
- 단일 클립당 64개의 프레임(I-프레임 2개, P-프레임 62개)을 처리하는 HEVC 스타일 구조를 성공적으로 구현
🚀 기존 대비 개선점
- 기존의 균등한 픽셀 처리 방식 대비, 코덱 원리에 기반하여 시간적 중요도에 따라 연산을 분배하므로 효율성이 극대화됩니다.
- 단순한 재구성(Reconstruction) 기반 학습을 넘어, 명시적인 의미적 구조를 잡아내는 코덱 정렬 방식을 통해 의미 이해력을 높였습니다.
- OCR 데이터를 통합하여 이미지 내의 텍스트 정보까지 모델이 이해할 수 있도록 입력의 다양성을 확장했습니다.
🎯 활용 분야
- 대규모 비디오 이해 및 검색 엔진
- 실시간 비디오 처리가 필요한 자율 주행 시스템
- 시각적 장치를 통한 추론 능력이 필요한 다중 모modal 에이전트(Multimodal Agents)
한계 및 주의사항
- 제공된 텍스트에서는 명시적인 한계점을 언급하지 않았으나, 코덱 구조에 강하게 의존하므로 코덱의 압축 방식이나 움직임 벡터(Motion Vector) 추출 오류에 따라 모델의 성능이 영향을 받을 가능성이 있습니다.
- 학습에 사용된 클래스 수가 200만 개에 달해, 실제 배포나 파인 튜닝 시 메모리 효율성에 대한 추가 고려가 필요할 수 있습니다.
6. CoPE-VideoLM: Codec Primitives For Efficient Video Language Models
arXiv: 2602.13191 | 기관: Microsoft | ⬆️ 20 🤖 GLM추천 | 📄 HTML 태그:
video-language-modelefficiencyvideo-codecmotion-vectorstokenizationmultimodalllmcomputer-vision사전 지식: Video Codecs (H.264, HEVC), GOP Structure, Motion Vectors, Vision Transformers, Tokenization

한 줄 요약
비디오 언어 모델의 연산 비용과 토큰 수를 획기적으로 줄이기 위해 원본 프레임을 직접 처리하는 대신 비디오 코덱의 압축 정보를 활용하는 새로운 패러다임을 제시했기 때문에 중요합니다.
💡 핵심 아이디어
이 방식은 마치 만화를 편집하는 과정과 비슷합니다. 기존 모델은 만화의 모든 컷을 처음 보는 것처럼 일일이 그림을 다시 그려서(RGB 인코딩) 처리했지만, 이 방식은 첫 컷(I-frame)만 자세히 보고, 이후 컷(P-frame)은 ‘이전 컷에서 캐릭터가 오른쪽으로 1cm 움직였고 배경은 그대로다’라는 약속된 코멘트(Motion Vector)만 읽어서 내용을 파악합니다. 이를 통해 불필요한 중복 연산을 줄이고 긴 영상도 효율적으로 이해할 수 있습니다.
문제 정의
비디오 언어 모델(VideoLM)이 긴 영상을 이해할 때, 모든 프레임을 고해상도 이미지로 처리하면 토큰 수가 폭발하여 최대 문맥 창(Context Window) 제한에 걸리거나 연산 비용이 감당할 수 없을 만큼 커진다는 문제를 해결하고자 합니다.
🔬 방법론 상세
- GOP(Group of Pictures) 구조 활용: 비디오 압축 표준인 MPEG-4나 H.264 등에서 사용하는 GOP 구조를 그대로 활용합니다. I-frame(완전한 이미지)과 P-frame(이전 프레임과의 차이)을 구분하여 처리합니다.
- 이중 경로 인코딩 (Two-Path Encoding): I-frame은 기존의 시각 인코더(Phi_RGB)를 통해 밀집된(Dense) RGB 토큰으로 변환하고, P-frame은 전체 디코딩 없이 움직임 벡터(Motion Vector)와 잔차(Residual) 정보만을 가벼운 델타 인코더(Phi_Delta)에 통과시켜 압축된 Delta-token으로 변환합니다.
- 토큰 융합 (Token Interleaving): 변환된 I-frame 토큰과 Delta-token을 시간 순서대로 섞어서(Interleave) 대규모 언어 모델(LLM)에 입력합니다. 이를 통해 모든 프레임의 정보를 담으면서도 전체 토큰 수는 획기적으로 줄입니다.
핵심 기법
이 논문의 가장 핵심은 **델타 인코더(Delta-Encoder)**입니다. 이는 비디오 파일 안에 숨어 있는 ‘어떤 물체가 어디로 얼마나 움직였는가’라는 정보(움직임 벡터)와 ‘움직임으로 설명되지 않는 남은 정보’를 추출하여 언어 모델이 이해하기 쉬운 형태의 토큰으로 바꿔주는 가벼운 변환기입니다.
📊 정량적 결과
주요 성과
- 총 14개의 비디오 벤치마크(PerceptionTest, NextQA, ActivityNet-QA 등)에서 포괄적인 평가를 수행했습니다.
- 기존 LLaVA-Video-7B 모델을 기반으로 1.39M 개의 질의응답 샘플을 사용해 파인 튜닝을 진행했습니다.
- 기존 방식 대비 표준 토큰 수와 실행 시간의 일부(fraction)만을 사용하여 전체 시간적 커버리지를 달성했다고 보고했습니다.
🚀 기존 대비 개선점
- 연산 효율성의 극대화: 모든 프레임을 완전한 이미지로 디코딩하고 인코딩하는 비용을 없애 P-frame 처리 속도를 크게 높였습니다.
- 밀도 높은 시간적 커버리지: 키프레임 샘플링 방식에서 놓치기 쉬웠던 미세한 동작(Micro-level details)이나 짧은 이벤트도 놓치지 않고 파악할 수 있습니다.
- 메모리 사용량 감소: 토큰 수를 줄임으로써 더 긴 영상을 동일한 하드웨어 메모리 내에서 처리할 수 있게 되었습니다.
🎯 활용 분야
- 대규모 비디오 검색 및 요약: 유튜브와 같은 플랫폼에서 업로드되는 방대한 양의 영상을 실시간으로 이해하고 태그를 달거나 요약하는 시스템.
- 로봇 공학: 로봇이 연속적인 동작(Video Sequence)을 통해 인간의 행동을 학습하고 모방할 때, 효율적으로 비디오를 처리하여 실시간 반응 속도를 높이는 데 사용할 수 있습니다.
- 비디오 질의응답(Video QA) 서비스: 긴 영상 강의나 영화를 대상으로 사용자의 질문에 대해 내용을 기반으로 답변해주는 AI 튜터나 어시스턴트 개발.
한계 및 주의사항
- 현재는 I-frame과 P-frame만 지원하며, B-frame(Bi-directional Predictive, 양방향 예측 프레임)의 복잡한 의존성은 지원하지 않습니다.
- 현재는 고정된 윈도우 크기로 P-frame을 융합(Fusion)하는데, 이는 움직임의 양이나 속도가 크게 변하는 동작에서는 최적이 아닐 수 있습니다.
- 현재 구현은 텐서화된 코덱 원시 요소를 사용하지만, 향후에는 더 비트 스트림에 가까운 원시 데이터를 직접 처리하여 효율을 더 높일 수 있습니다.
7. Intelligent AI Delegation
arXiv: 2602.11865 | 기관: Google | ⬆️ 10 🤖 GLM추천 | 📄 HTML 태그:
ai-agentsmulti-agent-systemdelegation-frameworkllm-orchestrationfuture-of-aiai-safetyhierarchical-reinforcement-learning사전 지식: Multi-Agent Systems (다중 에이전트 시스템), Large Language Models (LLM), Reinforcement Learning (강화 학습), Heuristics (휴리스틱), Mixture of Experts (MoE)
한 줄 요약
복잡한 목표를 달성하기 위해 수백만 개의 AI 에이전트가 상호작용하는 미래 경제를 대비하여, 기존의 단순한 규칙 기반 방식을 넘어선 동적이고 안전하며 책임감 있는 AI 위임(Delegation) 프레임워크를 처음으로 체계화했기 때문입니다.
💡 핵심 아이디어
이 논문은 거대한 건설 현장을 총괄하는 지휘관의 역할에 비유할 수 있습니다. 지휘관(AI 에이전트)은 단순히 일을 나눠주는 것에 그치지 않고, 각 작업반(하위 에이전트)의 현재 컨디션(자원 상태)과 신뢰도를 실시간으로 확인하고, 작업 중 문제가 생기면 즉시 계획을 수정하며, 최종적으로 책임 소재를 명확히 하여 안전하게 프로젝트를 완수해야 합니다.
문제 정의
현재의 AI 에이전트들은 단순한 질의-응답을 넘어 복잡한 작업을 수행하려 하지만, 작업을 분해하고 위임하는 과정이 여전히 정적이고 경험칙(Heuristic)에 의존하고 있습니다. 이는 급변하는 환경이나 예기치 못한 실패에 유연하게 대처하지 못하고, 누가 책임을 져야 할지 모호하며, 대규모로 확장될 때 시스템 전체가 위험해질 수 있는 근본적인 문제를 안고 있습니다.
🔬 방법론 상세
이 논문은 ‘지능형 위임(Intelligent Delegation)‘을 구현하기 위해 5가지 핵심 요구사항과 이를 지원하는 기술 프로토콜을 제안합니다.
- 동적 평가(Dynamic Assessment): 단순한 평판 점수를 넘어, 위임받는 에이전트의 현재 상태를 세밀하게 추론합니다. 여기에는 계산 처리량, 예산 제약, 컨텍스트 윈도우(Context Window, 모델이 한 번에 처리할 수 있는 텍스트의 길이) 포화도 같은 실시간 자원 가용성 데이터가 포함됩니다.
- 적응형 실행(Adaptive Execution): 맥락(Context)의 변화를 처리하기 위한 적응형 조정(Adaptive Coordination) 메커니즘을 도입하여, 초기 계획이 틀리더라도 상황에 맞게 유연하게 대응합니다.
- 구조적 투명성(Structural Transparency): 프로세스와 결과의 감사 가능성(Auditability)을 보장하기 위해 모니터링(Monitoring)과 검증 가능한 완료(Verifiable Completion) 기술을 적용합니다.
- 확장 가능한 시장 조정(Scalable Market Coordination): 대규모 환경에서 효율적이고 신뢰할 수 있는 조정을 위해 신뢰 및 평판 시스템(Trust & Reputation)과 다중 목적 최적화(Multi-objective Optimization, 서로 충돌하는 여러 목표를 동시에 최적화하는 기법)를 활용합니다.
- 시스템적 회복탄력성(Systemic Resilience): 보안(Security) 및 권한 처리(Permission Handling)를 통해 시스템 전체의 연쇄적 실패를 방지합니다.
핵심 기법
이 논문의 핵심은 위임을 단순한 ‘작업 할당’이 아니라 ‘권한과 책임의 이전’으로 재정의한 점입니다. 특히 동적 평가(Dynamic Assessment) 과정에서 에이전트의 능력뿐만 아니라 현재 가용 자원(예: GPU 여유분, 토큰 한도)까지 고려하여 위임 결정을 내리는 방식은, 바쁜 전문가에게 일을 맡기는 실수를 방지하는 효과를 낳습니다.
📊 정량적 결과
제공된 논문 텍스트는 구체적인 실험 데이터나 성능 향상 수치(%)를 포함하고 있지 않습니다. 대신 이 논문은 새로운 프레임워크를 제안하는 위치(Position Paper)에 가깝기 때문에, 정성적인 질적 향상에 초점을 맞추고 있습니다.
주요 성과
- 기존의 단순한 휴리스틱(경험칙) 기반 위임 시스템이 가진 환경 변화 적응 부족 문제를 해결하기 위한 5대 핵심 요구사항 정의
- 대규모 에이전트 경제(Agent Economy)에서 요구되는 신뢰, 책임, 보안을 포함한 포괄적인 거버넌스 구조 제안
- Mixture of Experts(전문가 혼합 모델)나 Hierarchical RL(계층적 강화 학습)의 장점을 통합하여 단일 에이전트 내뿐만 아니라 에이전트 간 위임으로 확장한 이론적 기반 마련
🚀 기존 대비 개선점
- 정적인 하드코딩된 흐름(Hard-coded flows)에서 벗어나 환경 변화에 실시간으로 대응하는 동적 위임 가능
- 단순한 작업 수행을 넘어, 책임(Accountability)과 권한(Authority)을 명확히 하여 법적/윤리적 문제에 대비한 안전성 확보
- 개별 에이전트의 성능을 넘어, 다중 에이전트 시스템 전체의 회복탄력성(Resilience)을 강화
🎯 활용 분야
- 기업용 워크플로우 자동화: 여러 부서의 AI 에이전트가 협력하여 복잡한 문서를 작성하고 승인하는 시스템
- 다중 로봇 제어: 물류 창고에서 수십 대의 로봇이 자원 배분과 역할 분담을 스스로 조율하여 작업 효율을 극대화하는 환경
- 개인형 AI 비서: 사용자의 복잡한 요구(여행 일정 짜기, 예약, 식당 추천 등)를 전문 분야의 다른 AI 에이전트에게 적절히 위임하여 처리하는 서비스
한계 및 주의사항
- 제안된 프레임워크는 이론적이고 구조적인 정의에 집중되어 있어, 실제 구현 시 각 프로토콜(예: 신뢰 시스템, 보안 검증)을 어떻게 기술적으로 구현할지에 대한 구체적인 알고리즘이나 수식이 부족할 수 있습니다.
- 대규모로 확장될 경우 발생할 수 있는 통신 오버헤드나 지연 시간(Latency)에 대한 실증적인 분석이 추가적으로 필요합니다.
8. ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
arXiv: 2602.11236 | 기관: Alibaba AMAP CV Lab | ⬆️ 9 | ⭐ 157 🤖 GLM추천 | 📄 HTML 태그:
vlaroboticsembodied-aifoundation-modeluniactaction-manifoldpre-training사전 지식: Vision-Language Model, Action Manifold Learning, Supervised Fine-Tuning, Stratified Sampling, Embodied AI

한 줄 요약
다양한 형태의 로봇이 하나의 통합된 두뇌를 공유하여 작업을 수행할 수 있는 ‘원 브레인, 많은 형태(One-brain, many-forms)’ 비전을 실현하기 위해, 6백만 개 이상의 궤적 데이터를 정제한 대규모 데이터셋과 이를 학습하는 VLA 기초 모델을 제안한 논문입니다.
💡 핵심 아이디어
이 논문은 마치 여러 종류의 자동차(세단, 트럭, 버스)를 운전할 수 있는 보편 운전 면허증을 만드는 것과 같습니다. 서로 다른 로봇의 형태와 데이터 형식을 하나의 언어로 번역하고 정제한 UniACT 데이터셋을 통해, 모델은 특정 로봇에 국한되지 않고 모든 로봇에 적용 가능한 보편적인 움직임의 원리를 학습합니다.
문제 정의
현재 로봇 공학은 데이터가 파편화되어 있고, 로봇마다 데이터 표현 방식과 제어 주기가 달라서 하나의 모델을 여러 로봇에 적용하기 어렵습니다. 또한, 고수준의 언어 지시를 저수준의 정밀한 물리적 제어로 변환하는 데 어려움이 있어, 다양한 로봇 몸체에 공통으로 쓰이는 범용적인 지능을 구현하는 것이 큰 장벽으로 남아 있습니다.
🔬 방법론 상세
- UniACT 데이터셋 구축: 6개의 공개 데이터셋에서 데이터를 정제하고 표준화하여 600만 개 이상의 궤적과 9,500시간 분량의 데이터를 확보했습니다. 이를 통해 다양한 로봇 형태와 작업 시나리오를 포괄합니다.
- VLM 및 액션 전문가(Action Expert) 아키텍처: 시각-언어 모델(VLM, Vision-Language Model)을 백본으로 사용하여 환경을 이해하고, 별도의 액션 전문가 모듈을 통해 로봇의 제어 신호를 생성하는 이중 구조를 채택했습니다.
- 액션 매니폴드 학습(Manifold Learning): 로봇 행동의 연속적인 공간을 학습하여 직접적으로 행동을 예측하는 방식을 사용합니다.
- 다단계 계층적 샘플링(Multi-level Stratified Sampling): 단순히 데이터 양에 따라 균등하게 샘플링하면 흔한 행위만 학습하게 되는 문제를 해결하기 위해, 로봇의 형태(embodiment)와 기술(skill)의 종류를 고려하여 데이터를 균형 있게 샘플링하는 전략을 제안했습니다.
핵심 기법
**다단계 계층적 샘플링(Multi-level Stratified Sampling)**은 쇼핑몰에서 물건을 진열할 때, 인기 상품만 채우는 대로드 드문드문 팔리지만 필요한 상품도 적절히 비치하는 것과 같습니다. 이를 통해 모델이 흔한 동작만 반복해서 학습하는 편향을 막고, 희귀하지만 중요한 기술과 다양한 로봇 형태를 골고루 경험하게 하여 일반화 성능을 높입니다.
📊 정량적 결과
주요 성과
- 데이터셋 규모: 기존 파편화된 데이터를 통합하여 600만 개의 궤적과 9,500시간의 대규모 고품질 데이터셋(UniACT)을 구축했습니다.
- 샘플링 효율성: 제안한 계층적 샘플링 방식을 통해 긴 꼬리 분포에 있는 희귀 기술이나 드문 로봇 형태를 효과적으로 학습할 수 있었으며, 이는 교차 작업 및 교차 형태 일반화 성능 향상으로 이어졌습니다.
🚀 기존 대비 개선점
- 데이터 호환성: 서로 다른 로봇 간의 데이터 표현 불일치 문제를 해결하여 이기종 데이터를 통합 학습이 가능한 형태로 변환했습니다.
- 공간 추론 강화: 선택적인 3D 공간 모듈을 도입하여 VLM이 가진 정성적 공간 이해(“컵이 상자 왼쪽에 있다”)를 밀리미터 단위의 정밀한 제어가 가능한 정량적 공간 정보로 보완했습니다.
- 학습 안정성: 균형 잡힌 데이터 샘플링 전략을 통해 특정 작업이나 로봇에 편향되지 않고 강건한 정책을 학습할 수 있게 되었습니다.
🎯 활용 분야
- 범용 로봇 제어: 팔 모양이나 구조가 다른 여러 로봇에게 하나의 모델로 작업을 지시할 수 있는 범용 제어 시스템 개발.
- 가정용 및 산업용 서비스 로봇: 새로운 로봇 하드웨어가 나와도 별도의 맞춤 학습 없이 기존 지능을 바로 탑재하여 활용.
- 로봇 데이터 라벨링 자동화: 대규모 사전 학습 모델을 활용하여 새로운 로봇 작업 데이터를 자동으로 생성하거나 라벨링하는 도구로 활용.
한계 및 주의사항
- VLM은 기본적으로 정성적인 공간 관계(“왼쪽”, “위”)를 이해하지만, 로봇 제어에는 밀리미터 단위의 메트릭한 정밀도가 필요하므로 이를 VLM 특성만으로 완벽히 해결하기 어렵습니다.
- 현재 연구는 주로 사전 학습 및 샘플링 전략에 집중되어 있어, 실제 물리적 환경에서의 미세한 오차나 실시간 제어 지연 등 실제 운영 단계의 문제는 추가적인 검증이 필요합니다.
9. DICE: Diffusion Large Language Models Excel at Generating CUDA Kernels
arXiv: 2602.11715 | ⬆️ 5 | ⭐ 2 🤖 GLM추천 | 📄 HTML 태그:
cuda-kerneldiffusion-llmcode-generationbic-rlhigh-performance-computingai-optimizationllm-inference사전 지식: CUDA (Compute Unified Device Architecture), Diffusion Models (디퓨전 모델), Autoregressive Model (자기회귀 모델), Reinforcement Learning (강화 학습), Supervised Fine-tuning (지도 학습 미세 조정)

한 줄 요약
이 논문은 순차적 생성 방식의 한계를 디퓨전 모델의 병렬적 구조 정제 능력으로 극복하여 고품질 CUDA 커널을 생성하고, 엄격한 성능 기반의 데이터셋과 단계별 강화 학습 프레임워크를 통해 고성능 컴퓨팅 코드 자동화의 새로운 기준을 제시했기에 중요합니다.
💡 핵심 아이디어
기존 모델이 코드를 한 단어씩 앞에서부터 쓰는 것과 같다면, 이 논문의 디퓨전 모델은 전체적인 윤곽을 먼저 잡고 점차 구체적인 디테일을 깎아내어 조각상을 완성하는 조각가와 같습니다. 이 접근 방식은 코드의 전체 구조를 한 번에 고려할 수 있어, 복잡한 CUDA 커널 개발에 필요한 비순차적 수정과 구조적 계획에 탁월한 성능을 발휘합니다.
문제 정의
대규모 언어 모델(LLM)을 이용한 CUDA 커널 생성 작업은 코드의 구조적 계획과 반복적인 수정이 필수적이나, 기존의 자기회귀(Autoregressive) 방식은 이를 순차적으로 처리해야 하는 비효율이 있습니다. 또한, 실제로 성능 향상을 입증한 고품질 CUDA 커널 학습 데이터가 극도로 부족하여 모델이 최적화된 코드를 학습하기 어렵다는 문제가 존재합니다.
🔬 방법론 상세
- CuKe 데이터셋 구축: 기존 데이터셋을 증강하여 성능을 기준으로 엄격하게 필터링했습니다. 특히 기존 PyTorch 구현 대비 2배 이상의 속도 향상(speedup)을 보이는 샘플만을 선별하고, 어텐션(Attention) 서브모듈이나 MLP 블록과 같은 복잡한 구조를 포함하여 구조적 다양성을 확보했습니다.
- BiC-RL 프레임워크: 강화 학습을 두 단계로 나누어 진행하는 이중 단계 큐레이팅 강화 학습(Bi-phase Curated Reinforcement Learning)을 제안했습니다. 첫 번째 단계는 CUDA 커널의 빈칸을 채우는(infilling) 과제를, 두 번째 단계는 끝에서 끝까지 전체 커널을 생성하는 과제를 수행하여 학습 효율과 수렴 안정성을 높였습니다.
핵심 기법
가장 핵심은 BiC-RL(Bi-phase Curated RL)로, 마치 초보자가 부품 조립부터 시작해 완성품 조립로 넘어가듯, 모델이 코드의 일부분을 수정하는 쉬운 단계부터 시작해 점차 전체 코드를 처음부터 생성하는 어려운 단계로 학습 난이도를 조절하는 것입니다. 이를 통해 모델이 불안정하게 튀는 현상을 줄이고 안정적으로 고품질 코드를 생성할 수 있도록 유도합니다.
📊 정량적 결과
주요 성과
- 데이터 품질 향상: 기존 PyTorch 대비 2배(2.0x) 이상의 속도 향상을 보이는 1,425개의 고품질 PyTorch-CUDA 쌍을 확보하여 학습 데이터의 신뢰도를 확보했습니다.
- 성능 격차 해소: Qwen3나 Seed-Coder-Reasoning 같은 최신 추론 모델들도 CUDA 커널 생성에서 기능적 정확성을 달성하기 어려웠으나, DICE 모델은 이를 효과적으로 해결하여 기능적으로 정확한 커널 생성 성능을 크게 개선했습니다.
- 추론 속도: 자기회귀 모델 대비 비약적으로 빠른 추론 속도를 달성하여 디퓨전 모델의 병렬 처리 장점을 실질적으로 입증했습니다.
🚀 기존 대비 개선점
- 디퓨전 모델 특유의 양방향 어텐션(Bidirectional Attention)과 반복적 정제(Iterative Refinement)를 통해 코드의 전체적인 맥락을 반영한 생성이 가능해졌습니다.
- 엄격한 성능 필터링(2.0x speedup)을 통해 단순히 문법적으로 맞는 코드가 아니라, 실제로 실행 속도가 빠른 최적화된 코드를 학습했습니다.
- 단계별 강화 학습을 통해 학습 초기의 불안정성을 완화하고, 전체 커널 생성 작업에서의 수렴 속도와 효율을 개선했습니다.
🎯 활용 분야
- 고성능 연산(GPGPU)이 필요한 딥러닝 추론 및 학습 시스템의 자동 최적화
- 파이토치(PyTorch)와 같은 고수준 프레임워크 코드를 저수준 CUDA 코드로 자동 변환하는 컴파일러 개발
- 복잡한 행렬 연산이나 사용자 정의 연산 커널을 빠르게 프로토타이핑하는 개발 도구
한계 및 주의사항
- 제안된 방법론은 특정 도메인인 CUDA 커널 생성에 최적화되어 있어, 일반적인 프로그래밍 언어 생성 작업으로의 일반화는 추가적인 검증이 필요합니다.
- 고품질 학습 데이터를 확보하기 위해 2배 이상의 속도 향상이라는 엄격한 필터를 적용했는데, 이로 인해 학습 가능한 데이터의 절대적인 양이 제한적일 수 있습니다.
10. Best of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
arXiv: 2602.12221 | 기관: Perception and LANguage Lab | ⬆️ 2 🤖 GLM추천 | 📕 PDF 태그:
multimodalflow-matchingreasoninggenerationdiffusion-modelsai-researchnlpcomputer-vision사전 지식: Diffusion Models, Flow Matching, Autoregressive Modeling, Multimodal Learning, Latent Space
한 줄 요약
이 논문은 이산적인 추론(Reasoning)과 연속적인 생성(Generation)이라는 두 가지 상충하는 목표를 이산 플로우 매칭(Discrete Flow Matching)이라는 단일 프레임워크로 통합하여, 멀티모달 모델의 성능과 효율성을 동시에 극대화했기 때문에 중요합니다.
💡 핵심 아이디어
마치 계산기처럼 정확한 논리적 추론을 수행하면서도, 화가처럼 자유롭고 고품질의 이미지를 생성할 수 있는 ‘한 명의 천재’를 만드는 것과 같습니다. 이는 그동안 서로 다른 도구(계산기와 붓)를 쓰듯 분리되어 있던 두 능력을 하나의 엔진(플로우 매칭)으로 통합하여, 생각(Reasoning)과 표현(Generation)을 동시에 해결하려는 시도입니다.
문제 정의
기존의 멀티모달 모델은 추론(Reasoning)을 위해 자기회귀(Autoregressive) 방식을, 생성(Generation)을 위해 확산 모델(Diffusion Model) 방식을 주로 사용했습니다. 이 두 가지 방식은 서로 최적화된 구조가 달라 하나의 모델 안에서 두 가지를 모두 최고 수준으로 수행하기 어렵다는 trade-off 문제가 있었습니다.
🔬 방법론 상세
- 이산 플로우 매칭 (Discrete Flow Matching): 기존의 연속적인 데이터(이미지)를 위한 플로우 매칭을 이산적인 데이터(텍스트 토큰)로 확장하여 적용합니다. 이를 통해 텍스트 생성에서도 확산 모델의 장점인 빠른 샘플링과 병렬 처리를 가능하게 합니다.
- 통일된 손실 함수 (Unified Objective): 추론과 생성을 서로 다른 손실 함수로 학습시키는 것이 아니라, 단일한 플로우 매칭 목적 함수 하에서 통합하여 학습시킵니다. 모델이 데이터의 확률적 흐름을 학습하면서 텍스트와 이미지의 공통된 표현을 이해하도록 유도합니다.
- 멀티모달 아키텍처 (Multimodal Architecture): 텍스트와 이미지를 같은 잠재 공간(Latent Space)으로 사상(Mapping)하여, 텍스트의 논리적 흐름이 이미지 생성 과정에 직접적인 영향을 미치도록 설계했습니다.
핵심 기법
가장 중요한 기법은 ‘이산 플로우 매칭(Discrete Flow Matching)‘입니다. 쉽게 말해, 단어 하나를 정해진 순서대로 써 내려가는 방식(Autoregressive) 대신, 온전한 문장을 ‘노이즈(무의미한 데이터)‘에서 서서히 ’ clarity(의미 있는 데이터)‘로 정제해 나가는 과정을 학습하는 것입니다. 이를 통해 컴퓨터가 문장을 생성할 때 앞 단어를 기다릴 필요 없이 한 번에 고민하고 쓸 수 있어 속도가 빨라지고, 이미지 생성과 같은 원리로 추론까지 가능해집니다.
📊 정량적 결과
주요 성과
- MMBench 벤치마크에서 기존 최신 모델 대비 약 **5.8%**의 정확도 향상을 달성하여 복합적인 추론 능력을 입증했습니다.
- 이미지 생성 평가 지표인 FID(Fréchet Inception Distance) 점수에서 15.2를 기록하며, 생성 품질 저하 없이 추론 능력을 유지했습니다.
- 생성 속도 측면에서 기존 자기회귀 모델 대비 약 2배 이상의 추론 속도 개선 효과를 보였습니다.
🚀 기존 대비 개선점
- 기존 모델들은 추론을 잘하면 이미지 생성이 느려지거나, 이미지를 잘 그리면 논리적 사고가 부족한 문제가 있었으나 이 논문은 두 능력을 모두 잡았습니다.
- 단일 모델 구조 내에서 텍스트와 이미지를 동시에 처리할 수 있어 시스템 복잡도가 낮아지고 배포가 쉬워졌습니다.
- 이산 데이터(텍스트) 처리에 플로우 매칭을 적용하여 기존 확산 모델보다 생성 과정이 훨씬 빨라졌습니다.
🎯 활용 분야
- 지능형 이미지 편집기: 사용자가 “배경을 어둡게 하고 분위기를 우울하게 바꿔줘”라고 복잡한 지시를 내려도, 그 문맥을 이해해 자연스럽게 이미지를 수정할 수 있습니다.
- 고차원 시각적 질의응답 (Visual QA): 의료 이미지나 도면 등을 보고 “이 부분이 왜 이상한지 설명해줘”라고 물으면, 단순히 설명만 하는 것이 아니라 논리적으로 추론한 뒤 수정된 이미지까지 생성하여 제시할 수 있습니다.
- 창의적 어시스턴트: 글쓴이가 소설의 한 장면을 묘사하면, AI가 그 문맥에 맞는 일러스트를 즉시 생성하여 창작 과정을 돕습니다.
한계 및 주의사항
- 아직까지 매우 긴 텍스트(Long-context)에 대한 추론 성능은 전통적인 언어 모델(LLM)에 비해 다소 부족할 수 있습니다.
- 이산 데이터와 연속 데이터를 결합하는 과정에서 학습 불안정성이 발생할 수 있어, 초기 학습 설정(Hyperparameter tuning)에 민감합니다.
📅 생성일: 2026-02-16 | 🤖 GLM-4.7