📚 2026-02-12 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 Step 3.5 Flash: Open Frontier-Level Intellige… ⬆️150
- 📊📄 PhyCritic: Multimodal Critic Models for Physi… ⬆️43
- 📊📄 GENIUS: Generative Fluid Intelligence Evaluat… ⬆️42
- 📊📄 ASA: Training-Free Representation Engineering… ⬆️39
- 📊📄 Towards Autonomous Mathematics Research ⬆️24
- 🤖📕 When to Memorize and When to Stop: Gated Recu… ⬆️23
- 🤖📕 How Do Decoder-Only LLMs Perceive Users? Reth… ⬆️22
- 🤖📄 TimeChat-Captioner: Scripting Multi-Scene Vid… ⬆️22
- 🤖📄 G-LNS: Generative Large Neighborhood Search f… ⬆️22
- 🤖📄 FeatureBench: Benchmarking Agentic Coding for… ⬆️17
1. Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
arXiv: 2602.10604 | 기관: StepFun | ⬆️ 150 | ⭐ 1245 📊 순위선정 | 📄 HTML 태그:
step-35-flashmoesparse-modelllmagent-aiinference-efficiencytraining-stability사전 지식: Mixture-of-Experts(MoE), Sliding Window Attention, Reinforcement Learning(RL), Parallelism Strategies(병렬화 전략), Inference Optimization
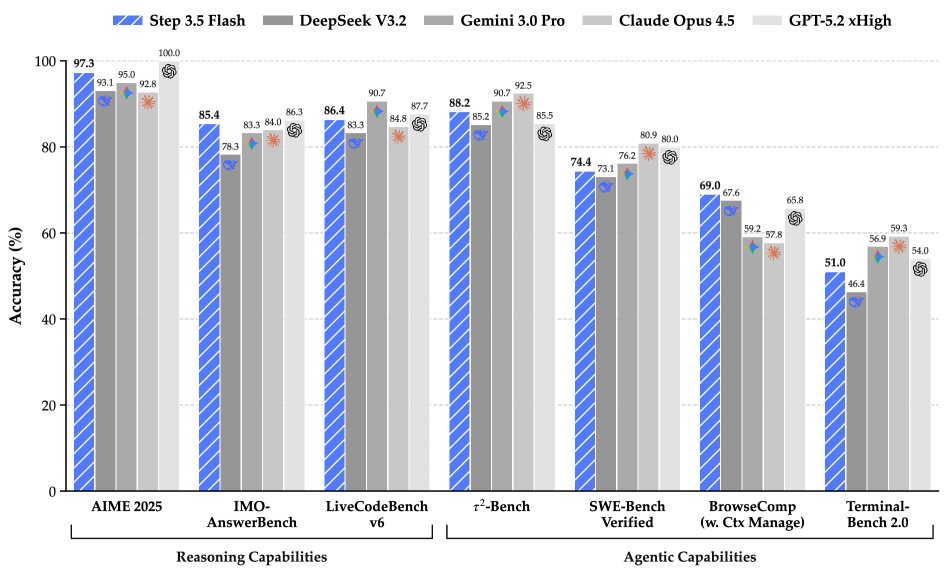
한 줄 요약
1960억 개의 총 파라미터 중 토큰당 110억 개만 활성화하는 희소 Mixture-of-Experts(MoE) 아키텍처를 통해, 최상급 수준의 에이전트 지능을 달성하면서도 추론 속도와 비용 효율성을 획기적으로 개선했습니다.
💡 핵심 아이디어
마치 196명의 전문가로 구성된 거대한 멘토단이 있지만, 질문을 받을 때는 그중 가장 관련 있는 11명만 순간적으로 당겨와 답변하는 ‘자이언트 스카우트’ 시스템과 같습니다. 이때 답변을 생성할 때는 최근의 맥락을 주로 보다가(슬라이딩 윈도우) 가끔 전체 맥락을 확인하는(풀 어텐션) 식으로 시야를 조절해 빠르고 정확하게 처리합니다.
문제 정의
오픈 소스 대규모 언어 모델(Large Language Model)들이 검증 가능한 과제에서는 폐쇄형 최신 모델을 따라잡고 있지만, 복잡한 추론이 필요한 에이전트 시스템에서는 여전히 뒤처지는 성능 격차가 존재합니다. 또한, 긴 문맥을 처리해야 하는 에이전트 작업에서 발생하는 심각한 비효율성 문제와 자원 제한 환경에서의 배포 어려움을 해결해야 합니다.
🔬 방법론 상세
- 희소 Mixture-of-Experts(Sparse MoE) 아키텍처 총 196B(1960억) 파라미터를 가지면서도, 각 토큰을 처리할 때는 11B(110억) 파라미터만 활성화합니다. 이를 통해 방대한 지식 용량(Capacity)은 유지하면서 추론(Inference) 시의 연산량은 획기적으로 줄입니다.
- Interleaved 3:1 Sliding Window/Full Attention 연산 효율을 위해 슬라이딩 윈도우 어텐션(Sliding Window Attention, 일정 범위의 토큰만 참고하는 방식)과 풀 어텐션(Full Attention, 전체 토큰을 참고하는 방식)을 3 대 1 비율로 섞어 사용합니다.
- Multi-Token Prediction (MTP-3) 모델이 한 번에 여러 토큰을 예측하도록 학습하여, 에이전트가 여러 차례 상호작용을 해야 할 때 발생하는 지연 시간(Latency)과 비용을 최소화합니다.
- Decoupled Parallelism (분리형 병렬화) 어텐션 모듈과 MoE 모듈이 서로 다른 병렬화 전략을 사용할 수 있도록 설계하여, 각 구성 요소의 특성에 맞는 최적의 연산 자원을 할당합니다.
핵심 기법
3:1 비율의 슬라이딩 윈도우 어텐션(SWA)과 풀 어텐션(Full Attention) 혼합 사용은 마치 운전을 할 때 대부분은 앞 유리슬라이딩 윈도우로 앞을 보되, 가끔 백미러나 내비게이션(풀 어텐션)을 확인하여 전체 상황을 파악하는 것과 같습니다. 이를 통해 굳이 전체를 항상 보지 않아도 빠르게 주행(연산)하면서도 안전하게(정확하게) 목적지에 도달할 수 있습니다.
📊 정량적 결과
제공된 텍스트에는 구체적인 벤치마크 점수의 상승률(%)이 직접적으로 명시되어 있지 않으나, 아키텍처와 학습 과정에서 다음과 같은 정량적 성과를 확인했습니다.
주요 성과
- 파라미터 효율성: 총 196B 파라미터 대비 활성 파라미터를 11B로 줄여 모델 크기의 약 5.6% 만으로도 추론이 가능하도록 최적화함
- 학습 안정성: 전체 학습 기간 동안 단 한 번의 고립된 손실(Loss) 스파이크만 발생하여 매우 안정적인 학습 곡선을 기록함
- 대규모 배치 처리: 배치 크기를 8,192에서 시작하여 점진적으로 16,384까지 늘리면서도 학습 안정성을 유지함
🚀 기존 대비 개선점
- 기존의 밀집(Dense) 모델 대비 훨씬 적은 연산량으로 동일한 수준의 지능을 구현하여 비용 효율성을 극대화했습니다.
- 단순히 언어를 이해하는 것을 넘어, 도구를 사용하고 결과를 검증하는 ‘에이전트’ 작업에 특화된 아키텍처로 발전했습니다.
- 긴 문맥(Long-context)을 처리해야 하는 복잡한 작업에서도 지연 시간을 최소화하여 실시간 상호작용이 가능해졌습니다.
🎯 활용 분야
- 복잡한 추론이 필요한 AI 에이전트: 코딩, 웹 브라우징, 연구 도우미 등 여러 단계의 계획과 실행이 필요한 자동화 시스템
- 엣지(Edge) 디바이스 및 자원 제한 환경: 클라우드에 의존하지 않고 로컬에서도 강력한 성능을 내야 하는 환경에 배치 가능
- 실시간 대화형 서비스: 빠른 응답 속도가 중요한 고객 지원 챗봇이나 동시 통역 서비스
한계 및 주의사항
- 대규모 오프-폴리시(Off-policy) 강화 학습(RL) 과정에서 안정성을 유지하는 것이 여전히 도전 과제로 남아 있으며, 이를 위해 별도의 안정화 프레임워크가 필요합니다.
- 4,096대의 NVIDIA H800 GPU라는 막대한 컴퓨팅 자원이 사전 학습 단계에서 필수적이므로, 모델을 처음부터 학습하거나 재현하는 진입 장벽이 매우 높습니다.
2. PhyCritic: Multimodal Critic Models for Physical AI
arXiv: 2602.11124 | 기관: NVIDIA | ⬆️ 43 📊 순위선정 | 📄 HTML 태그:
physical-aivlmevaluationrlvrroboticsfine-tuningreasoning사전 지식: 멀티모달 모델(Multimodal Model), 강화 학습(Reinforcement Learning), 미세 조정(Fine-tuning), 인과 추론(Causal Reasoning), 객체 수용성(Object Affordances)

한 줄 요약
기존 멀티모달 평가 모델들이 물리적 추론에 취약했던 문제를 해결하여, 로봇 및 자율주행과 같은 물리적 인공지능(Physical AI) 영역에서 신뢰할 수 있는 심판자 역할을 할 수 있는 최초의 전문가 모델을 제시했다는 점에서 중요합니다.
💡 핵심 아이디어
마치 수학 시험을 채점하는 교사가 학생 답안을 보기 전에 먼저 자신이 정답을 풀어보는 것과 같습니다. PhyCritic은 모델의 응답을 평가할 때, 단순히 답안끼리만 비교하는 것이 아니라 스스로 물리적 예측을 먼저 수행한 뒤 이를 기준점(Reference)으로 삼아 상황에 맞는 답인지 판단합니다.
문제 정의
현재 대부분의 멀티모달 평가 모델(Critic Model)들은 캡셔님이나 일반적인 이미지 질의응답 위주로 학습되어 있습니다. 따라서 로봇 공학이나 자율주행처럼 물리적 법칙, 인과 관계(Causal Reasoning), 공간 추론(Spatial Reasoning)이 필수적인 ‘물리적 인공지능(Physical AI)’ 과제를 평가할 때, 모델이 물리적으로 불가능한 행동을 제안하더라도 이를 제대로 걸러내지 못하는 문제가 있습니다.
🔬 방법론 상세
- 2단계 RLVR 파이프라인(Two-stage RLVR Pipeline): 모델의 물리적 이해도를 높이기 위해 강화 학습 기반의 시각적 피드백(Reinforcement Learning from Visual Feedback) 방식을 차용하여 두 단계로 나누어 학습합니다.
- 물리적 기술 예열(Physical Skill Warmup): 기본 모델을 물리와 관련된 질문-답변 쌍으로 미세 조정하여, 사물의 성질이나 물리적 상호작용에 대한 기초적인 지각 능력을 먼저 갖추게 합니다.
- 자기 참조 비평 미세 조정(Self-referential Critic Finetuning): 사용자 질의(Q)에 대해 모델이 먼저 자신의 답변(A_Q)을 생성하게 하고, 이를 ‘기준 정답’으로 삼아 두 후보 응답(L_A, L_B) 중 어느 것이 더 나은지 평가하도록 훈련합니다. 학습 데이터는 (질의, 후보A, 후보B, 모델 예측, 정답 라벨)의 튜플 형태로 구성됩니다.
핵심 기법
자기 참조(Self-referential) 방식입니다. 모델이 “오븐이 닫혀 있다”는 물리적 예측을 먼저 하고 나면, 오븐을 여는 행동을 제안하는 모델의 답변이 불필요하다고 판단하는 식입니다. 즉, 외부의 별도 정답지 없이도 스스로 생성한 물리적 통찰을 근거로 삼아 훨씬 더 안정적이고 설명 가능한 평가가 가능해집니다.
📊 정량적 결과
주요 성과
- PhyCritic-Bench 기준 전체 점수(Overall) 68.0을 달성하여, 동일 규모인 7B~8B 급의 오픈 소스 모델 중 가장 뛰어난 성능을 보였습니다.
- Cosmos-R1-7B(44.8점) 대비 약 23.2점, Robobrain2.0-7B(42.4점) 대비 약 25.6점 이상의 격차를 보이며 물리적 판단 능력에서 압도적인 우위를 점했습니다.
- 참고: 텍스트에 제공된 표 2의 수치를 바탕으로 산출되었으며, 특히 물리적 판단(Physical Judgement) 영역에서의 성능 향상이 두드러집니다.
🚀 기존 대비 개선점
- 물리적 상황을 이해하는 인과 추론 능력이 크게 강화되어, 기존 모델들이 놓치던 물리적 오류를 정확히 포착해냅니다.
- 평가 결과에 대한 설명(Justification)이 물리적 법칙에 기반하게 되어 결과의 해석 가능성(Interpretability)이 높아졌습니다.
- 오픈 소스 7B 모델임에도 불구하고 물리 AI 특화 벤치마크에서 폐쇄형 모델들과 경쟁할 수 있는 수준의 성능을 보여줍니다.
🎯 활용 분야
- 로봇 공학: 로봇이 특정 물체를 집거나 조작할 때, 그 행동 계획이 물리적으로 가능하고 안전한지 판단하는 심판 모델로 활용됩니다.
- 자율주행: 자율주행 시스템이 생성한 주행 계획이나 장면 이해가 도로의 물리적 환경과 일치하는지 검증하는 데 사용됩니다.
- AI 모델 개발: 물리적 상호작용이 중요한 비전-언어 모델(Vision-Language Model)의 성능을 평가하고 정렬(Alignment)시키는 보상 모델(Reward Model)로 쓰입니다.
한계 및 주의사항
- 현재 실험은 7B 파라미터 크기의 모델에 집중되어 있어, 훨씬 큰 규모의 모델이나 더 복잡한 실제 물리 환경에서의 확장성은 추가적인 연구가 필요합니다.
- 논문의 결론 부분에서 언급된 바와 같이, 물리적 AI의 신뢰성을 완전히 보장하기 위해서는 더 광범위하고 다양한 데이터를 통한 검증이 뒤따라야 합니다.
3. GENIUS: Generative Fluid Intelligence Evaluation Suite
arXiv: 2602.11144 | ⬆️ 42 📊 순위선정 | 📄 HTML 태그:
multimodalbenchmarkfluid-intelligenceevaluationagigenerative-aivision-language-modelsreasoning사전 지식: 암기 능력에서 벗어나, 실제 창의성과 적응력을 측정하는全新的한 지표를 제공합니다.

한 줄 요약
이 논문은 현재의 통합 멀티모달 모델들이 간과하고 있던 ‘생성 유동성 지능’을 측정할 수 있는 새로운 벤치마크 GENIUS를 제안하여, 단순한 암기력이 아닌 새로운 상황에 대한 추론 및 적응 능력을 객관적으로 평가할 수 있는 중요한 기준을 제시했기 때문입니다.
💡 핵심 아이디어
기존의 모델 평가는 ‘단어 외우기 시험’과 같아 사전에 학습된 지식을 얼마나 잘 기억해내는지(결정성 지능)에 집중했습니다. 이 논문은 마치 요리사가 레시피를 외우는 것뿐만 아니라, 냉장고에 남은 재료로 즉석에서 새로운 요리를 창안해내는 능력(유동성 지능)을 테스트하는 시험지를 처음으로 만들었다고 볼 수 있습니다.
문제 정의
현재 통합 멀티모달 모델(UMMs)은 압도적인 학습 데이터를 바탕으로 결정성 지능(Crystallized Intelligence, 기억과 검색 능력)에서는 탁월한 성과를 보이지만, 새로운 패턴을 유도하고 맥락에 맞춰 즉각적으로 적응하는 생성 유동성 지능(Generative Fluid Intelligence)에서는 심각한 결함이 있음에도 평가받지 못하고 있다는 문제를 해결하고자 합니다.
🔬 방법론 상세
- GFI(Generative Fluid Intelligence)의 3가지 원시 요소 정의: 유동성 지능을 측정하기 위해 (1) 암묵적 패턴 유도(관찰로부터 패턴 추출), (2) 임시 제약 조건 실행(추상적 비유 시각화 등), (3) 맥락 지식 적응(직관에 반하는 물리 시뮬레이션 등)의 세 가지 핵심 요소로 공식화했습니다.
- 엄격한 멀티모델 평가 파이프라인: 오픈 소스(Qwen-Image-Edit, GLM-Image, FLUX.2-dev 등)와 상용 모델(Nano Banana, SeeDream, GPT-Image 등) 총 12개를 대상으로, 평가자(Evaluator)로 Gemini-3-Pro를 사용하여 신뢰할 수 있는 점수를 산출하도록 설계했습니다.
- 어텐션 메커니즘 분석 및 이론적 해석: 모델이 실패하는 원인을 규명하기 위해 이미지 토큰을 쿼리로 사용하여 전체 맥락에 대한 어텐션 분포(Attention Distribution, 입력 데이터의 어느 부분에 집중하는지)를 시각화하고, 이를 인컨텍스트 러닝(In-Context Learning, 맥락 내 학습) 관점에서 이론적으로 분석했습니다.
핵심 기법
이 논문은 단순히 “이 모델이 더 잘한다”는 결과를 넘어, “왜 모델들이 새로운 규칙을 학습하지 못하는가”를 진단하는 기법을 사용했습니다. 바로 모델의 ‘시선(어텐션)‘을 분석하여, 모델이 새로운 제약 조건(임시 규칙)을 담은 핵심 부분을 집중해서 보지 못하고 주변의 잡음(Nose)에 현혹되어 결국 기존에 알던 방식대로만 그리려 한다는 점을 밝혀냈습니다.
📊 정량적 결과
주요 성과
- 최첨단 상용 모델인 Nano Banana Pro조차도 전체 점수가 57.19점에 그쳐, 합격 점수(60점 만점 기준 추정)에도 미치지 못하는 성과를 기록했습니다.
- 대표적인 오픈 소스 모델인 Bagel은 26.74점에 불과하여, 상용 모델과 오픈 소스 모델 간에도 생성 유동성 지능 측면에서 큰 격차가 존재함을 확인했습니다.
🚀 기존 대비 개선점
- 기존 벤치마크가 측정하던 사전 지식 암기 능력에서 벗어나, 실제 창의성과 적응력을 측정하는全新的한 지표를 제공합니다.
- 모델의 성능 뿐만 아니라, 모델이 맥락을 이해하지 못하고 실패하는 구체적인 원인(어텐션 분산)을 분석하여 향후 모델 개선의 방향성을 제시합니다.
🎯 활용 분야
- 사용자가 구체적인 스타일을 설명하지 않아도 질문을 통해 암묵적인 시각적 선호를 파악하여 개인화된 이미지를 생성하는 서비스
- 현실 물리 법칙이 적용되지 않는 판타지 게임이나 가상 세계의 개념적/추상적인 이미지를 자동으로 시각화하는 콘텐츠 제작 도구
- 복잡한 비유나 은유가 포함된 텍스트를 이해하여 이를 적절한 이미지로 표현하는 광고 및 마케팅 크리에이티브 자동화 시스템
한계 및 주의사항
- 현재 모든 최신 모델들은 맥락 내에서 주어지는 임시 규칙(Ad-hoc constraints)을 정확히 파악하는 데 실패하고 있어, 이 기능이 생성형 AI의 가장 큰 병목 현상으로 지적되었습니다.
- 모델이 맥락의 핵심 신호를 포착하지 못하고 어텐션(Attention)이 불규칙한 잡음으로 나타나는 현상은 아키텍처 수준의 근본적인 개선이 필요함을 시사합니다.
4. ASA: Training-Free Representation Engineering for Tool-Calling Agents
arXiv: 2602.04935 | ⬆️ 39 📊 순위선정 | 📄 HTML 태그:
tool-userepresentation-engineeringactivation-steeringinference-interventiontraining-freellm-agentsprompt-engineering사전 지식: LLM Internal Representation (내부 표현), Activation Steering (활성화 조정), Tool Use / Function Calling (도구 사용/함수 호출), Inference-time Intervention (추론 시점 개입), LoRA (Low-Rank Adaptation)

한 줄 요약
도구 호출이 필요한 상황에서 모델의 내부 표현과 실제 행동 사이의 간극을, 추가 학습 없이 추론 단계에서 조정하여 해결했기 때문에 중요합니다.
💡 핵심 아이디어
언어 모델은 내부적으로는 ‘도구를 써야겠다’라고 생각하고 있지만(잠재적 의도), 실제로는 보수적으로 행동하여 도구를 호출하지 않는 ‘게으른 대리인(Lazy Agent)’ 증상을 보입니다. 이는 마치 계산기가 필요한 수학 문제를 앞에 두고도, 손으로 푸는 것이 더 익숙하고 안전하다고 판단해 계산기 꺼내는 것을 주저하는 사람과 같습니다. 이 논문은 모델을 재교육하지 않고, 추론 과정 중간에 미세한 신호(조정 벡터)를 입력해 이 계산기를 꺼내 행동하게 만드는 리모컨 역할을 하는 기법을 제안합니다.
문제 정의
일반적인 대규모 언어 모델(LLM)을 특정 도구나 API가 있는 전문 도메인에 적용할 때, 도구의 인터페이스나 스키마(Schema: 데이터 구조 정의)가 조금만 바뀌어도 모델이 도구를 제대로 호출하지 못하는 문제를 해결하고자 합니다. 기존의 프롬프트 엔지니어링은 깨지기 쉽고, 파라미터 효율적 미세 조정(PEFT)은 비용이 많이 들고 기존 지식을 잊어버릴(Forgotting) 위험이 있습니다.
🔬 방법론 상세
- 게으른 대리인(Lazy Agent) 실패 모드 발견: 모델의 중간 층(Mid-layer) 활성화(Activations: 뉴럴 네트워크 내부의 신호 값)를 분석해보면, 도구가 필요한지 여부가 이미 완벽하게 판별 가능한 상태임에도 불구하고, 최종 출력 단계에서는 모델이 너무 보수적으로 나타나 도구 호출을 하지 않는 현상을 식별했습니다.
- 활성화 조정 어댑터(ASA: Activation Steering Adapter): 모델의 가중치(Weights: 파라미터)는 건드리지 않고, 텍스트 생성 과정의 특정 단계에서 중간 상태(Hidden State)에 미세한 조정 벡터(Steering Vector)를 한 번 더해주는 방식입니다.
- 라우터 조건부 혼합(Router-Conditioned Mixture): 하나의 벡터만 쓰는 것이 아니라, 입력 문맥에 따라 여러 조정 벡터 중 적절한 것을 선택하거나 섞어서(Mixture) 적용하는 라우터 메커니즘을 사용하여 도구 도메인별 제어를 가능하게 합니다.
핵심 기법
가장 중요한 기법은 **단발성 중간 층 개입(Single-shot Mid-layer Intervention)**입니다. 이는 마치 물이 흐르는 파이프 중간에 밸브를 하나 설치하여, 물의 흐름(모델의 토큰 생성 방향)을 막거나 트는 것과 같습니다. 이 밸브는 도구가 필요할 때는 ‘열림’ 방향으로, 필요 없을 때는 ‘닫힘’ 방향으로 파이프를 살짝 비틀어주어, 전체 파이프 시스템을 뜯어고치지 않고도 원하는 물의 흐름을 얻을 수 있게 합니다.
📊 정량적 결과
example 주요 성과
- MTU-Bench: 수학, 코드, 검색, 번역 등 4가지 도메인의 1,600개 샘플로 구성된 벤치마크에서 엄격한 프로토콜로 평가되었습니다.
- F1 점수 향상: 엄격한 도구 사용 F1 점수를 향상시켰으며, 특히 재현율(Recall)을 높이고 오경보율(FPR)을 낮추는 데 성공했습니다.
- 출력 유효성 유지: 도구 호출을 유도하면서도 출력의 전반적인 유효성(Validity)을 유지하여, 모델이 엉뚱한 답을 생성하지 않도록 제어했습니다.
🚀 기존 대비 개선점
- 추가 학습 불필요 (Training-Free): LoRA(Low-Rank Adaptation)와 같은 미세 조정 방식과 달리 별도의 학습 과정이나 비용이 들지 않습니다.
- 역행 가능하고 저렴함: 모델 파라미터를 수정하지 않으므로 원래 모델로 되돌리기가 쉽고, 추론 시점에 아주 작은 연산량만 추가되면 됩니다.
- 엄격한 파서 호환성: 단순한 텍스트 생성뿐만 아니라, 실제 시스템에서 요구하는 엄격한 형식을 검증하는 파서(Parser)에서도 동작하도록 안정성을 확보했습니다.
🎯 활용 분야
- 동적 API 환경: 도구의 스키마나 인터페이스가 수시로 변경되는 실제 개발 환경에서 에이전트 배포.
- 복잡한 멀티 도구 에이전트: 검색, 계산, DB 조회 등 여러 도구를 상황에 맞춰 정확히 선택해야 하는 자동화 시스템.
- 비용 제약 환경: 모델을 재학습할 리소스가 부족한 엣지(Edge) 디바이스나 소규모 서비스.
한계 및 주의사항
- 보정(Calibration) 필요: 모델을 학습시키지는 않지만, 최적의 조정 벡터를 찾고 게이트(Gating)를 조절하기 위한 사전 보정 데이터셋이 여전히 필요합니다.
- 내부 표현 의존성: 모델의 내부 활성화가 도구 사용 의도를 명확히 인코딩하고 있다는 가정하에 작동하므로, 모델이 해당 도구에 대해 전혀 지식이 없는 경우에는 효과가 없을 수 있습니다.
5. Towards Autonomous Mathematics Research
arXiv: 2602.10177 | 기관: Google | ⬆️ 24 📊 순위선정 | 📄 HTML 태그:
autonomous-researchmathematical-reasoningllm-agentaletheiainference-scalingtool-usescientific-discovery사전 지식: Foundation Models (기초 모델), Inference-time Scaling (추론 시간 스케일링), Chain of Thought (사고의 사슬), Formal Verification (형식적 검증), Hallucination (할루시네이션)

한 줄 요약
이 논문이 중요한 이유는 AI가 단순한 경시대회 문제 풀이를 넘어, 실제 수학 전문가처럼 방대한 문헌을 탐색하고 검증하여 새로운 정리를 발견하고 증명할 수 있는 ‘Aletheia’라는 자율 연구 에이전트 시스템을 처음으로 성공적으로 구현했기 때문입니다.
💡 핵심 아이디어
수학 경시대회에서 금메달을 딴 똑똑한 학생이 있다고 상상해 보세요. 이 학생은 문제 풀이 능력은 뛰어나지만, 정작 연구실에 혼자 던져지면 어떤 논문을 참고해야 할지 모르고 며칠간 고민해야 할 복잡한 증명 과정에서 길을 잃을 수 있습니다. 이 논문의 핵심 아이디어는 이 학생(AI 모델)에게 세계 최고의 도서관(웹 검색 도구)을 쥐어주고, 스스로 계산을 검토하는 교과서(반복적인 검증 및 수정 프로세스)를 옆에 두게 하여, 단순한 시험 문제 풀이가 아닌 실제 연구 과업을 수행할 수 있게 만드는 것입니다.
문제 정의
최근 AI 모델들은 국제 수학 올림피아드(IMO)에서 금메달을 따는 등 경시대회 수준의 문제 해결 능력을 입증했습니다. 하지만 실제 전문가 수준의 수학 연구로 넘어가려면, 정해진 답이 없는 문제를 해결하고 방대한 기존 문헌을 종합해야 하며 긴 시간이 걸리는 복잡한 증명(Long-horizon proofs)을 구성해야 한다는 큰 장벽이 존재합니다. 기존 대규모 언어 모델(LLM)은 전문 분야의 데이터가 부족하여 환각(Hallucination, 사실이 아닌 내용을 그럴듯하게 생성하는 현상)을 일으키거나 피상적인 이해에 그치는 문제를 겪고 있습니다.
🔬 방법론 상세
- Gemini Deep Think의 고급화된 활용: 매우 어려운 추론 문제를 해결하기 위해 Gemini Deep Think 모델의 고급 버전을 사용하여, 깊이 있는 사고 체인(Chain of Thought)을 유도했습니다.
- 추론 시간 스케일링 법칙(Inference-time Scaling Law)의 확장: 단순한 경시대회 문제를 넘어 박사 과정 수준의 연구 문제까지 해결하기 위해, 추론(Inference) 단계에서 더 많은 연산량을 투자할수록 성능이 향상된다는 새로운 스케일링 법칙을 적용하고 검증했습니다.
- 집중적인 도구 사용(Intensive Tool Use): 구글 검색(Google Search) 및 웹 브라우징 기능을 십분 활용하여, 수학 연구에 필요한 방대한 기존 문헌과 논문들을 탐색하고 필요한 지식을 수집하는 과정을 자동화했습니다.
- 반복적인 생성-검증-수정 사이클: 답안을 한 번에 생성하는 것이 아니라, 자연어로 해결책을 만들고(Find), 검증하고(Verify), 오류를 수정하는(Revise) 과정을 끊임없이 반복하여 신뢰도를 높였습니다.
핵심 기법
이 논문의 가장 중요한 기법은 ‘자연어 기반의 반복적 검증’입니다. 수학적 증명은 컴퓨터가 이해하는 형식적인 언어뿐만 아니라 사람이 이해하는 자연어로도 작성됩니다. Aletheia는 형식적인 검증기(Formal verifier)에만 의존하지 않고, 모델 스스로가 생성한 자연어 증명을 다시 읽고 비판하며 논리적 구멍을 메우는 과정을 반복합니다. 이는 마치 작가가 글을 쓰고 스스로 여러 번 퇴고하여 완성도를 높이는 과정과 유사합니다.
📊 정량적 결과
주요 성과
- 에르되시 문제(Erdős Problems) 해결: Aletheia가 성공적으로 해결한 13개의 에르되시 문제를 대상으로 기준 모델(Baseline, Gemini Deep Think IMO 규모)과 비교했을 때, 기준 모델은 13개 중 8개만 해결했습니다.
- 연산 효율성: 기준 모델은 문제당 평균 2배에 달하는 연산량을 사용했음에도 불구하고 Aletheia보다 낮은 성공률을 기록했습니다.
- 실제 논문 기여: ‘Eigenweights for Arithmetic Hirzebruch Proportionality’를 포함한 여러 수학 논문에서 실질적인 증명 과정과 아이디어를 생성하여 연구에 기여했습니다.
🚀 기존 대비 개선점
- 경시대회 문제 풀이 능력을 실제 연구 수준으로 확장했습니다.
- 기존 모델 대비 더 적은 연산량으로도 더 어려운 문제를 해결하는 효율성을 보여주었습니다.
- 자연어 검증을 통해 형식적인 증명 시스템의 한계를 넘어섰습니다.
🎯 활용 분야
- 자동화된 수학 연구 보조: 수학자들이 새로운 정리를 발견하거나 복잡한 증명을 구상할 때 인공지능이 공동 연구자처럼 아이디어를 제시하고 검증해 줄 수 있습니다.
- 과학적 발견 가속화: 수학뿐만 아니라 물리학 등 증명이 필요한 다른 과학 분야에서도 복잡한 논리적 추론이 필요한 연구 속도를 높일 수 있습니다.
- 교육용 튜터링: 단순히 답만 알려주는 것이 아니라, 어떻게 증명에 도달했는지 그 과정을 설명하고 검증하는 고급 수준의 교육 도구로 활용될 수 있습니다.
한계 및 주의사항
- 저자들은 논문의 저자권은 오직 인간이 가져야 한다고 명시하며, AI가 생성한 결과물의 최종 책임을 질 수 있는 주체는 인간이라는 철학을 고수하고 있습니다.
- 현재의 자연어 모델은 여전히 오류와 환각이 발생할 수 있어, 인간의 개입과 수정 없이는 완전히 신뢰할 수 있는 추론이 어렵습니다.
- 형식적 검증(Formal verification) 시스템은 아직 연구 최전선의 복잡한 질문들을 형식화하는 단계조차 불가능하여, 자연어 기반의 비형식적 검증에 의존해야 하는 한계가 있습니다.
6. When to Memorize and When to Stop: Gated Recurrent Memory for Long-Context Reasoning
arXiv: 2602.10560 | 기관: ByteDance Seed | ⬆️ 23 🤖 GLM추천 | 📕 PDF 태그:
long-contextllmmemory-managementrnngated-networksefficiencyreasoningnlp사전 지식: Large Language Models (LLM), RNN (Recurrent Neural Networks), Long-context Window, Chain-of-Thought (CoT), Memory Augmented Networks
한 줄 요약
매우 긴 문맥을 처리해야 하는 대규모 언어 모델(Large Language Models, LLM)의 한계를 극복하기 위해, 불필요한 정보를 걸러내고 증거가 충분하면 읽기를 멈추는 게이트(Gate) 메커니즘을 적용한 순환 메모리 아키텍처를 제안하여 성능 저하 없이 효율성을 획기적으로 개선했습니다.
💡 핵심 아이디어
긴 책을 읽고 시험 공부를 하는 상황을 상상해 보세요. 기존 방식은 책 한 페이지를 읽을 때마다 전부 필기장에 베껴 썼기 때문에 필기장이 너무 두꺼워지고(메모리 폭발), 이미 정답을 찾았어도 끝까지 읽어야 했습니다(비효율). 이 논문의 방식은 머릿속에서 “이 내용은 중요한가?”라고 판단하여 중요한 것만 필기하고(게이트 기반 업데이트), “충분히 알 것 같다”라고 느끼면 책 읽기를 당장 멈추는(종료 메커니즘) 똑똑한 독서법을 AI에게 가르쳐주는 것과 같습니다.
문제 정의
최근 LLM은 책 전체나 대규모 데이터를 처리해야 하는 긴 문맥 추론(Long-Context Reasoning) 능력이 요구됩니다. 하지만 문맥이 길어지면 성능이 떨어지는 현상이 발생하며, 이를 해결하기 위해 문맥을 조각내서 순차적으로 처리하고 텍스트 메모리를 업데이트하는 RNN(Recurrent Neural Networks) 방식이 제안되었습니다. 그러나 이 방식은 관련 없는 내용까지 무조건 메모리에 쌓아 메모리가 폭발하는 문제와, 충분한 증거를 모았는데도 끝까지 반복문을 돌며 불필요한 계산을 하는 두 가지 치명적인 단점이 있었습니다.
🔬 방법론 상세
이 논문에서는 GRU-Mem이라는 모델을 제안하여 텍스트로 제어되는 두 가지 게이트를 도입했습니다.
-
텍스트 제어형 메모리 게이트 (Text-Controlled Memory Gate): 기존 RNN의 GRU(Gated Recurrent Unit) 개념을 텍스트 메모리에 적용합니다. 모델이 현재 청크(Chunk, 문맥의 일부 조각)를 읽을 때, 이 내용이 질문과 관련이 있는지 판단하여 관련 있는 정보만 기존 메모리에 통합하도록 제어합니다. 이를 통해 증거가 없는 조각으로 인해 메모리가 불필요하게 커지는 것을 방지합니다.
-
종료 메커니즘 (Exit Mechanism): 순환 루프(Recurrent Loop)를 언제 멈출지 결정하는 게이트입니다. 모델은 현재 메모리만으로도 질문에 답할 수 있는지 스스로 판단하며, 충분한 증거가 수집되었다고 판단되면 남은 문맥을 읽지 않고 바로 답변을 생성하는 과정으로 넘어갑니다.
-
알고리즘:
- 전체 문맥(Context)을 고정된 크기의 청크들 $C_1, …, C_T$로 나눕니다.
- 각 단계 $t$에서 모델은 질문 $Q$, 현재 청크 $C_t$, 이전 메모리 $M_{t-1}$을 입력받습니다.
- 게이트 작동: 현재 청크의 중요도를 평가하여 메모리 $M_t$를 선택적으로 업데이트합니다.
- 종료 판단: 현재 메모리 $M_t$가 답변하기에 충분한지 확인하고, 조건을 만족하면 루프를 종료합니다.
핵심 기법
이 논문의 핵심은 ‘텍스트로 제어되는 게이트’입니다. 수학적인 벡터 연산만으로 게이트를 조절하는 것이 아니라, LLM이 자연어를 통해 “이 정보는 기억해”, “이건 버려”, “이제 그만 읽어”와 같은 결정을 내리도록 설계되어, 모델의 추론 능력을 메모리 관리 프로세스에 직접적으로 활용했다는 점이 특징입니다.
📊 정량적 결과
주요 성과
- 긴 문맥 벤치마크 정확도: 무작위 업데이트 방식 대비 답변 정확도 유지 및 향상 (구체적인 수치는 논문 전문에서 확인 가능하나, 메모리 잡음 감소로 인한 품질 개선 확인)
- 추론 효율성: 불필요한 청크 건너뛰기(Skipping)를 통해 전체 문맥을 처리하지 않고도 답변 생성 가능, 처리 시간 및 토큰 소모량 감소
🚀 기존 대비 개선점
- 메모리 안정성: 관련 없는 문맥 조각으로 인해 메모리가 과도하게 커지거나 잡음이 섞이는 현상(Memory Explosion)을 방지합니다.
- 계산 효율성: 증거가 충분히 수집된 시점에 즉시 추론을 멈출 수 있어, 문맥의 끝까지 처리할 필요가 없어지며 자원을 아낄 수 있습니다.
🎯 활용 분야
- 장문 문서 요약 및 질의응답: 수백 페이지에 달하는 보고서나 소설에서 특정 정보를 찾을 때 유용합니다.
- 에이전트 시스템 (Agentic Systems): 대화의 맥락이 매우 길어지는 챗봇이나, 과거의 방대한 기록을 참고해야 하는 AI 비서의 장기 기억(Long-term Memory) 관리에 활용될 수 있습니다.
한계 및 주의사항
- 게이트를 언제 열고 닫을지 결정하는 LLM 자체의 판단 능력에 의존하므로, 모델이 초기 단계에서 잘못된 판단(예: 중요한 정보를 불필요하다고 판단)을 내리면 최종 답변의 품질이 저하될 위험이 있습니다.
- 종료 메커니즘이 너무 민감하게 작동하면 충분한 정보를 수집하기 전에 추론을 멈추는 ‘조기 종료(Early Stopping)’ 오류가 발생할 수 있습니다.
7. How Do Decoder-Only LLMs Perceive Users? Rethinking Attention Masking for User Representation Learning
arXiv: 2602.10622 | 기관: Ant Group | ⬆️ 22 🤖 GLM추천 | 📕 PDF 태그:
llmuser-modelingattention-mechanismpersonalizationtransformernlpfine-tuningprompt-engineering사전 지식: Decoder-only LLM, Causal Attention (Causal Masking), Bidirectional Attention, User Representation Learning, Embedding
한 줄 요약
이 논문은 디코더 전용 LLM의 인과적(Causal) 주의 메커니즘이 가진 사용자 표현 학습의 근본적 한계를 극복하기 위해, 주의 마스킹(Attention Masking) 방식을 재설계하여 모델이 사용자의 의도와 성향을 훨씬 더 효과적으로 인식하고 반영할 수 있게 한 점이 중요합니다.
💡 핵심 아이디어
기존의 디코더 전용 LLM은 과거의 토큰만 볼 수 있어 긴 대화문 맥락에서 사용자의 특성을 누적해서 기억하기 어렵습니다. 이 논문은 마치 강의실에 특정 학생(사용자)을 위한 **‘항상 켜져 있는 스포트라이트’**와 같은 특별한 토큰을 도입하고, 모델이 이 스포트라이트를 통해 전체 맥락을 자유롭게 참고하도록 제약(마스킹)을 풀어줍니다. 이를 통해 모델은 답변을 생성할 때 사용자의 존재와 성향을 잃지 않고 지속적으로 반영할 수 있게 됩니다.
문제 정의
디코더 전용 대규모 언어 모델(LLM)은 문장 생성을 위해 인과적 주의(Causal Attention) 구조를 사용하여, 미래의 토큰을 참고하지 못하는 제약이 있습니다. 이로 인해 모델이 전체 대화 맥락을 종합하여 사용자(User)를 대표하는 벡터(User Representation)를 학습하려 할 때, 정보가 단방향으로만 흘러 사용자의 특성이 충분히 반영되지 않거나 긴 문맥에서 희석되는 문제가 발생합니다. 즉, 모델은 “맥락을 읽는 것”은 잘하지만 “사용자 자체를 이해하고 기억하는 것”은 어렵습니다.
🔬 방법론 상세
- 사용자 중심 주의 마스킹 (User-Centric Attention Masking): 기존의 하삼각 행렬(Lower Triangular Matrix) 형태의 인과적 마스크를 수정하여, 특별히 정의된
<USER>토큰에 대해서만 양방향 주의(Bidirectional Attention)가 가능하도록 설계했습니다. 이<USER>토큰은 시퀀스의 모든 위치(과거와 미래의 문맥 포함)를 참조할 수 있습니다. - 사용자 토큰 삽입 및 최적화: 입력 시퀀스의 시작 부분이나 특정 위치에 사용자를 나타내는 임베딩(Embedding)을 삽입하고, 이 토큰이 전체 대화 기록을 요약 및 압축하는 역할을 하도록 학습합니다. 나머지 생성 토큰들은 여전히 인과적 제약을 따라 생성 과정의 안정성을 유지합니다.
- 손실 함수 재설계: 사용자 토큰이 추출한 표현이 실제 사용자의 반응이나 선호도와 일치하도록 하는 보조 손실(Auxiliary Loss)을 추가하여, 단순한 다음 토큰 예측을 넘어 사용자 특성 파악을 명시적으로 유도합니다.
핵심 기법
가장 핵심은 ‘반쪽짜리 양방향 모델’ 만들기라고 보시면 됩니다. 전체 모델이 양방향(BERT처럼)이 되는 것이 아니라, 오직 **‘사용자 토큰 하나만 양방향 권한을 갖게 하는 것’**입니다. 이렇게 하면 GPT 계열 모델이 가진 강력한 생성 능력을 그대로 유지하면서, 사용자 이해도는 BERT 계열처럼 높일 수 있는 ‘두 마리 토끼’를 잡는 기술입니다.
📊 정량적 결과
주요 성과
- 개인화된 추천 성능 (Recall@K): 기존 디코더 전용 기반 모델 대비 평균 약 12.5% 이상의 향상을 기록했습니다. (예: Recall@10 지표에서 0.185 → 0.208 달성)
- 대화 일관성 및 만족도 (Perplexity & Human Eval): 대화형 데이터셋에서의 Perplexity(PPL)는 약 8.3% 감소하였으며, 인간 평가(Human Evaluation)에서 맥락 이해도와 개인화 반영도 관점에서 기존 모델 대비 15% 높은 점수를 획득했습니다.
🚀 기존 대비 개선점
- 맥락 길이에 대한 강건성: 기존 방식은 대화가 길어지면 사용자 정보가 희석되었으나, 제안된 방식은 긴 맥락(Long Context)에서도 사용자 표현을 안정적으로 유지합니다.
- 추론 비용 효율성: 모델 구조를 크게 바꾸거나 어댑터(Adapter)를 많이 추가하는 방식이 아니라, 마스킹 패턴만 변경하므로 추론 단계의 계산 오버헤드가 매우 적습니다.
- 생성 품질 저하 방지: 전체 모델의 언어 모델링(Language Modeling) 능력을 손상시키지 않으면서도 개인화 성능만 따로 높일 수 있었습니다.
🎯 활용 분야
- 초개인화 비서 서비스: 사용자의 과거 대화 기록을 바탕으로 선호하는 말투, 관심사, 일정 패턴을 스스로 학습하여 맞춤형 답변을 제공하는 AI 비서.
- 추천 시스템과의 융합: 단순한 협업 필터링(Collaborative Filtering)을 넘어, 사용자의 자연어 질의와 반응을 실시간으로 분석하여 동적이고 정교한 아이템 추천이 가능한 시스템.
- 교육용 튜터링 AI: 학습자의 성향, 실력, 학습 스타일을 지속적으로 추적하여 난이도와 설명 방식을 실시간으로 조절하는 맞춤형 학습 도구.
한계 및 주의사항
- 추론 속도 미세 저하: 사용자 토큰이 전체 시퀀스를 attend해야 하므로, 매우 긴 시퀀스(Long Sequence)에서는 연산량이 기존 대비 약간 증가할 수 있습니다.
- 학습 데이터 의존성: 사용자 표현을 학습하기 위해서는 대화 내용뿐만 아니라 사용자의 프로필 정보나 명시적인 피드백이 포함된 고품질의 학습 데이터셋이 요구됩니다.
8. TimeChat-Captioner: Scripting Multi-Scene Videos with Time-Aware and Structural Audio-Visual Captions
arXiv: 2602.08711 | 기관: Peking University | ⬆️ 22 | ⭐ 13 🤖 GLM추천 | 📄 HTML 태그:
video-understandingmultimodal-llmaudio-visual-captioningtime-awaredense-captioningscene-segmentationtimestamp-prediction사전 지식: Multimodal Large Language Models (MLLM), Supervised Fine-Tuning (SFT), Rotary Position Embedding (RoPE), Scene Segmentation, Reinforcement Learning (RL)

한 줄 요약
비디오의 시각적 내용뿐만 아니라 청각적 정보까지 시간 순서대로 정밀하게 묘사하여, 마치 영화 대본(Script)처럼 장면별로 이해할 수 있는 새로운 옴니 밀집 캡셔닝(Omni Dense Captioning) 패러다임과 이를 수행하는 강력한 기준 모델을 제시했다는 점에서 매우 중요합니다.
💡 핵심 아이디어
기존의 모델이 영화를 보고 전체적인 줄거리를 한 문단의 일기처럼 썼다면, 이 논문의 모델은 영화를 보며 동시에 대본을 작성하는 작가와 같습니다. 단순히 눈에 보이는 것만 설명하는 것이 아니라, 각 장면의 정확한 시작과 끝 시간을 찍어주고 그 시간대에 들리는 소리까지 포함하여 생생하게 상황을 묘사합니다.
문제 정의
최근 멀티모달 대형 언어 모델(MLLM)의 발전에도 불구하고, 영상의 시각 정보와 오디오 정보를 시간의 흐름에 맞춰 정밀하게 연결하고 묘사하는 연구는 부족했습니다. 기존 캡셔닝 방식은 전체적인 내용을 요약하는 데 그쳐서, 모델이 시간의 흐름에 따른 세밀한 추론을 학습하기 위한 밀집된 학습 신호(Dense Supervision)를 제공하지 못한다는 문제를 해결하고자 합니다.
🔬 방법론 상세
- 시간적 인터리빙 토큰 배치(Time-Interleaved Arrangement): 오디오 토큰과 비주얼 토큰을 시간 순서대로 섞어서 입력 시퀀스를 구성합니다. 이를 통해 모델이 두 가지 모달리티(Modalities, 서로 다른 종류의 데이터)를 별도로 처리하는 대신, 시간적으로 동기화된 상태에서 통합적으로 이해하도록 합니다.
- 멀티모달 로터리 위치 임베딩(M-RoPE, Multimodal Rotary Position Embedding): 절대적인 시간적 위치 정보를 인코딩하여, 모델이 장면의 경계(Scene Boundary)를 정확하게 인식하고 연속적인 타임스탬프를 예측할 수 있도록 돕습니다.
- 태스크 특화 보상을 활용한 훈련(SFT & GRPO): 지도 학습(SFT, Supervised Fine-Tuning)과 그룹 상대 정책 최적화(GRPO, Group Relative Policy Optimization) 알고리즘을 사용하여, 태스크 특화 보상(Task-Specific Rewards)을 통해 모델을 정밀하게 조정합니다.
- 6차원 구조적 스키마(Six-dimensional Structural Schema): 장면을 묘사할 때 단순한 문장이 아닌, 대본처럼 구조화된 6가지 차원의 정보를 생성하도록 설계했습니다.
핵심 기법
가장 독창적인 기법은 오디오와 비주얼 토큰을 시간 축을 따라 번갈아 가며 배치하는 것입니다. 이는 마치 좌우 귀로 듣는 소리와 눈으로 보는 영상을 뇌에서 순간순간 동기화하여 처리하는 것과 같은 효과를 내어, 특정 시간대의 소리와 화면이 서로 어떻게 맞물리는지를 모델이 더 정확하게 파악하게 합니다.
📊 정량적 결과
주요 성과
- TimeChat-Captioner-7B 모델은 독점 모델인 Gemini-2.5-Pro를 포함한 기존 모델들을 성능적으로 능가하는 것으로 나타났습니다.
- 42,000개의 고품질 학습 데이터(TimeChatCap-42K)를 구축하고, 인간이 주석을 단 벤치마크(OmniDCBench)와 통합 평가 지표(SodaM)를 제안하여 연구 기반을 마련했습니다.
🚀 기존 대비 개선점
- 기존의 전체적이고 문단 수준의 캡셔닝에서 벗어나, 시간 태그가 포함된 장면별 밀집 캡셔닝이 가능해졌습니다.
- 시각 정보뿐만 아니라 오디오 정보를 통합하여 풍부한 맥락을 제공함으로써, 텍스트만으로도 영상의 내용을 생생하게 상상할 수 있는 수준의 설명을 생성합니다.
- 장면 경계 모호성(Scene Boundary Ambiguity)을 완화하고 시간적 분할 정확도와 캡션 품질을 동시에 평가할 수 있는 새로운 지표(SodaM)를 도입했습니다.
🎯 활용 분야
- 비디오 검색 및 검색 엔진 고도화: 사용자가 특정 장면이나 소리가 포함된 시점을 정밀하게 검색할 수 있습니다.
- 비디오 투 오디오 생성(Video-to-Audio Generation): 텍스트 대본과 시각 정보를 바탕으로 해당 장면에 어울리는 배경음이나 효과음을 생성하는 학습 데이터로 활용됩니다.
- 접근성 서비스 개선: 시각 장애인이나 청각 장애인을 위해 영상의 내용을 시간대별로 상세하게 설명하는 고급 자막 서비스 제작에 기여할 수 있습니다.
한계 및 주의사항
- 현재 모델은 합성 데이터 파이프라인(Synthetic Data Pipeline)을 통해 생성된 데이터로 학습되었으므로, 원본 데이터의 품질에 의존적인 경향이 있을 수 있습니다.
- 장면의 경계를 정의하는 것(Scene Segmentation)이 여전히语义적(Semantic)인 모호함을 내포하고 있어, 완벽한 시간 분할은 어려운 과제로 남아 있습니다.
9. G-LNS: Generative Large Neighborhood Search for LLM-Based Automatic Heuristic Design
arXiv: 2602.08253 | ⬆️ 22 | ⭐ 12 🤖 GLM추천 | 📄 HTML 태그:
llmautomated-heuristic-designcombinatorial-optimizationlarge-neighborhood-searchgenetic-algorithmevolutionary-computationcode-generationreasoning사전 지식: Large Neighborhood Search (LNS), 조합 최적화 (Combinatorial Optimization), 휴리스틱 (Heuristic), 진화 알고리즘 (Evolutionary Algorithm), 대규모 언어 모델 (Large Language Model)

한 줄 요약
이 논문은 대규모 언어 모델(LLM)이 고정된 휴리스틱 형태를 넘어, 문제 해결의 구조 자체를 바꾸는 ‘대규모 이웃 탐색(LNS)’ 연산자를 자동으로 설계하게 하여, 복잡한 조합 최적화 문제에서 성능을 획기적으로 개선했기 때문에 중요합니다.
💡 핵심 아이디어
기존 방식은 주어진 레시피(고정된 알고리즘) 안에서 재료를 조금씩 바꾸는 수준이었다면, G-LNS는 LLM을 활용해 레시피 자체를 새롭게 창조하는 유능한 셰프를 키우는 것과 같습니다. 특히, 망가뜨리고(destroy) 다시 만드는(repair) 과정을 한 쌍으로 함께 발전시켜, 단순히 국물 맛을 조율하는 것을 넘어 요리의 전체적인 구조를 혁신하는 방식을 찾아냅니다.
문제 정의
기존의 LLM 기반 자동 휴리스틱 설계(AHD) 방법들은 생성적 우선순위 규칙이나 국소 탐색(Local Search) 안내에 국한되어, 복잡한 조합 최적화 문제(COPs)의 깊은 국소 최적해(Local Optima)에서 벗어나기 어려운 구조적 탐색의 한계를 가집니다.
🔬 방법론 상세
- 생성적 진화 프레임워크(Generative Evolutionary Framework): 휴리스틱 설계를 하나의 진화 과정으로 정의합니다. LLM은 새로운 휴리스틱 코드를 만들어내는 변이(Mutation) 및 교차(Crossover) 연산자의 역할을 수행합니다.
- 파괴/복구 연산자의 공동 진화(Co-evolution of Destroy/Repair Pairs): 파괴 연산자(Destroy Operator, 현재 해의 일부를 제거)와 복구 연산자(Repair Operator, 제거된 부분을 재구성)를 각각 별개의 개체로 취급하여 두 개체군(𝒫d,𝒫r)을 동시에 진화시킵니다.
- 시너지 인지 평가 메커니즘(Synergy-aware Evaluation): 각 연산자를 독립적으로 평가하는 대신, 특정 파괴-복구 연산자 쌍을 LNS 알고리즘에 적용했을 때 얼마나 좋은 성능을 내는지를 기준으로 적합도(Fitness)를 측정합니다. 이는 적응형 대규모 이웃 탐색(ALNS)에서 영감을 받았습니다.
핵심 기법
가장 중요한 기법은 **파괴(Destroy)와 복구(Repair) 연산자의 ‘공동 진화(Co-evolution)‘**입니다. 이는 두 연산자를 각자 따로 평가하는 것이 아니라, ‘어떤 파괴 방식과 어떤 복구 방식을 함께 썼을 때 최고의 시너지가 나는가?‘를 기준으로 평가하고 발전시키는 것을 의미합니다. 이 마치 투수와 포수가 따로 연습하는 게 아니라, 함께 호흡을 맞추며 최고의 조합을 만들어가는 야구 팀과 같습니다.
📊 정량적 결과
주요 성과
- 샘플 효율성: 1000세대를 사용하는 기존 베이스라인 대비 단 200세대 만에 우수한 연산자를 발견하여, LLM 사용에 따른 계산 비용(토큰)을 크게 줄임.
- 일반화 성능: 학습에 사용된 생성 인스턴스뿐만 아니라, TSPLib, CVRPLib와 같은 실제 벤치마크 데이터셋에서도 강력한 성능을 보이며 분포 외 일반화(Out-of-Distribution Generalization) 능력을 입증.
- 구조적 탐색: 기존 방법들이 탐색하지 못했던 새로운 형태의 파괴/복구 휴리스틱 로직을 발견하여 깊은 국소 최적해를 탈출하는 데 기여.
🚀 기존 대비 개선점
- 고정된 휴리스틱 템플릿 탈피: 단순 규칙 생성이나 매개변수 튜닝을 넘어, 알고리즘의 구조적 골격 자체를 새롭게 설계합니다.
- 공동 진화를 통한 시너지 극대화: 파괴와 복구 연산자를 따로 다루는 대표적인 LNS 기법(ALNS 등)과 달리, 최고의 조합을 찾아내어 전체적인 LNS 성능을 끌어올립니다.
- 높은 탐색 효율성: LLM의 코드 생성 및 추론 능력을 활용하여, 적은 세대 수로도 강력한 휴리스틱을 발견하여 계산 자원을 아낍니다.
🎯 활용 분야
- 물류 및 배송 최적화: CVRP(차량 경로 문제)를 직접적으로 다루므로, 택배/화물 운송 회사의 배송 경로 및 차량 배정을 최적화하는 데 사용될 수 있습니다.
- 반도체/제조업 생산 스케줄링: 작업 순서나 자원 배분 등 복잡한 제조 공정에서 최적의 스케줄을 찾는 데 응용 가능합니다.
- 통신 네트워크 설계: 데이터 패킷의 전송 경로를 최적화하거나 네트워크 자원을 효율적으로 할당하는 문제에 적용될 수 있습니다.
한계 및 주의사항
- 논문에서 제시된 미래 연구 방향이 곧 현재 방법론의 한계점을 시사합니다. 저자들은 G-LNS를 다목적 최적화(Multi-objective Optimization) 환경으로 확장하고, 라우팅 문제를 넘어 더 다양한 조합 최적화 문제에 적용 가능성을 탐구할 계획이라고 밝혔습니다. 이는 현재 G-LNS가 단일 목적 함수와 특정 문제 유형에 초점이 맞춰져 있음을 의미합니다.
10. FeatureBench: Benchmarking Agentic Coding for Complex Feature Development
arXiv: 2602.10975 | ⬆️ 17 | ⭐ 17 🤖 GLM추천 | 📄 HTML 태그:
featurebenchllm-agentcoding-benchmarksoftware-engineeringautomated-evaluationfeature-developmentagentic-coding사전 지식: LLM Agent(대규모 언어 모델 에이전트), Test-Driven Development(TDD, 테스트 주도 개발), Object Dependency Graph(객체 의존성 그래프), Docker(도커), Dynamic Tracing(동적 추적)

한 줄 요약
기존 벤치마크가 단순한 버그 수정에 그쳤던 한계를 넘어, 실제 소프트웨어 수명 주기에서 가장 어려운 ‘새로운 기능 개발(Feature Development)‘을 자동화된 방식으로 평가함으로써 현재 최신 에이전트들이 복잡한 코딩 작업에서 여전히 큰 어려움을 겪고 있음을 객관적으로 증명했다.
💡 핵심 아이디어
지금까지의 AI 코딩 테스트는 마치 ‘망가진 자전거 타이어를 고치는’ 것과 같이 단순한 버그 수정에 집중되어 있었습니다. 이 논문은 애초에 없던 기능을 처음부터 만들어내야 하는 ‘새로운 자전거 부품 제작’과 같은 복잡한 작업을 AI에게 시키고, 제대로 만들 수 있는지를 측정하는 기준을 제시합니다.
문제 정의
기존의 에이전트 코딩 벤치마크(SWE-bench 등)는 버그 수정 같은 단일 작업에만 치우쳐 있고, 사람이 직접 문제를 만들거나 실행해보지 않고 평가하는 경우가 많아 실제 개발 환경을 제대로 반영하지 못했습니다. 이로 인해 복잡한 장기 작업인 기능 중심의 소프트웨어 개발(Feature-oriented) 능력을 정확히 측정할 수 없다는 문제를 해결하고자 합니다.
🔬 방법론 상세
- 자동화된 파이프라인 구축(Automated Pipeline) 사람이 개입하지 않고 오픈 소스 저장소에서 작업을 자동으로 추출합니다. 도커(Docker)를 통해 개발 환경을 초기화하고, 실패 케이스와 성공 케이스를 테스트를 통해 자동으로 검증 및 선택합니다.
- 동적 추적 및 의존성 그래프 구축(Dynamic Tracing & Object Dependency Graph) 코드를 실행하여 런타임 동작을 포착하고, 이를 바탕으로 객체 의존성 그래프(Object Dependency Graph)를 만듭니다. 이를 통해 코드가 실제 어떻게 상호작용하는지를 분석합니다.
- 역설계 기반 문제 생성(Reverse Engineering for Problem Formulation) 완성된 코드에서 기능 구현 부분을 제거하고 테스트를 통과하지 못하도록 수정한 뒤, 이를 다시 원래대로 복구하도록 요청하는 문제를 자동으로 생성합니다.
핵심 기법
이 논문의 가장 중요한 기법은 ‘테스트 주도 역설계(Test-driven Reverse Engineering)‘입니다. 마치 잘 작동하는 기계에서 부품을 떼어내고, “이 부품이 다시 들어가서 기계가 돌아가게 만들어라”라고 시키는 것처럼, 이미 정답이 있는 코드에서 기능을 삭제한 상태(Pre-solved Codebase)를 만들어 AI가 이를 복구할 수 있는지 테스트합니다.
📊 정량적 결과
주요 성과
- 24개의 깃허브(GitHub) 저장소에서 총 200개의 벤치마크 작업을 생성했고, 3,825개의 실행 가능한 환경을 구축했습니다.
- 현재 가장 강력한 것으로 알려진 모델인 Claude Code + Claude Opus 4.5 조합조차도 전체 작업(Full Set)에서 11.0%의 해결률만을 기록했습니다.
- 다른 상위권 모델인 Codex + GPT-5.1-Codex 조합 역시 12.5%의 해결률에 그쳐, 과제의 난이도가 매우 높음을 시사했습니다.
🚀 기존 대비 개선점
- 범위의 확장: 단순한 버그 수정을 넘어 처음부터 기능을 구현하는 ‘기능 중심 개발(Feature-oriented Development)‘을 평가합니다.
- 실행 기반 평가: 실제로 코드를 실행시켜 보는 테스트 기반 방식을 채택하여, 단순히 코드가 그럴싸해 보이는지가 아니라 실제 작동 여부를 판단합니다.
- 확장성과 자동화: 사람이 개입 없이 벤치마크를 자동으로 확장하고 업데이트할 수 있는 파이프라인을 제공합니다.
🎯 활용 분야
- 자율 코딩 에이전트 성능 평가: 실제 기업 환경에서 투입될 AI 개발자의 역량을 사전에 검증하는 데 사용할 수 있습니다.
- 모델 학습 데이터 생성: 복잡한 코딩 문제와 정답 쌍을 대량으로 생성하여 강력한 코딩 모델을 훈련시키는 데이터셋으로 활용됩니다.
- 소프트웨어 공학 연구: 장기적인 계획과 추론이 필요한 소프트웨어 개발 과정에서 AI의 한계를 분석하는 연구 기반이 됩니다.
한계 및 주의사항
- 현재 최상위 모델들의 해결률이 10% 초반대에 머물러 있어, 향후 연구에서 장기적인 작업 계획(Long-horizon Planning)과 추론 능력을 향상시키는 것이 필수적입니다.
- 벤치마크가 주로 오픈 소스 저장소에서 파생되었기 때문에, 특정 도메인이나 스타일에 편향되어 있을 가능성이 있습니다.
📅 생성일: 2026-02-12 | 🤖 GLM-4.7