📚 2026-02-10 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 QuantaAlpha: An Evolutionary Framework for LL… ⬆️174
- 📊📄 Weak-Driven Learning: How Weak Agents make St… ⬆️165
- 📊📕 MOVA: Towards Scalable and Synchronized Video… ⬆️141
- 📊📄 Modality Gap-Driven Subspace Alignment Traini… ⬆️127
- 📊📄 Recurrent-Depth VLA: Implicit Test-Time Compu… ⬆️63
- 🤖📄 AIRS-Bench: a Suite of Tasks for Frontier AI … ⬆️61
- 🤖📕 InternAgent-1.5: A Unified Agentic Framework … ⬆️59
- 🤖📕 LLaDA2.1: Speeding Up Text Diffusion via Toke… ⬆️53
- 🤖📄 RLinf-USER: A Unified and Extensible System f… ⬆️46
- 🤖📄 Towards Agentic Intelligence for Materials Sc… ⬆️43
1. QuantaAlpha: An Evolutionary Framework for LLM-Driven Alpha Mining
arXiv: 2602.07085 | 기관: QuantaAlpha | ⬆️ 174 | ⭐ 156 📊 순위선정 | 📄 HTML 태그:
quantaalphaalpha-miningllm-agentevolutionary-algorithmquantitative-financetrajectory-optimizationfinancial-ai사전 지식: 알파 팩터 마이닝, 백테스팅, 비정상성, 유전 알고리즘, LLM 에이전트

한 줄 요약
이 논문은 거대 언어 모델(LLM) 기반의 요인 탐색 과정을 하나의 궤적으로 정의하고, 여기에 유전 알고리즘의 돌연변이와 교차 과정을 적용하여 금융 시장의 잡음과 비정상성 문제를 극복하고 알파 발견의 효율성을 획기적으로 높였다는 점에서 매우 중요합니다.
💡 핵심 아이디어
퀀트 투자 전략을 개발하는 과정을 요리법 개발에 비유할 수 있습니다. 기존 방식은 맛집 사장이 매번 처음부터 요리를 시도해보고 맛없으면 버리는 방식이었다면, QuantaAlpha는 성공한 요리법(궤적)을 분석하여 ‘소스를 만드는 단계’만 실패했는지, 아니면 ‘재료 선정 단계’가 문제였는지를 찾아냅니다. 그 후, 다른 성공한 요리법의 좋은 단계와 합체(교차)하거나 실패한 단계를 수정(돌연변이)하여 더 완벽한 레시피를 진화시키는 방식입니다.
문제 정의
금융 시장은 매우 시끄러운(Noisy) 데이터와 비정상성(Non-stationary, 시간이 지남에 따라 데이터의 성질이 변하는 특성)을 가지고 있어, 백테스트 결과가 과적합되기 쉽고 시장 상황이 급변할 때 전략이 망가지기 쉽습니다. 기존의 LLM 에이전트 프레임워크는 이러한 검증된 경험을 효과적으로 재사용하지 못하고, 제어 가능한 다중 라운드 탐색이 어렵다는 한계가 있었습니다.
🔬 방법론 상세
- 알파 마이닝 궤적 정의: 단순한 요인 생성이 아니라, 가설 수립, 실행 코드 구현, 백테스트 평가로 이어지는 전체 과정을 하나의 궤적(Trajectory)으로 정의하고 이를 진화의 단위로 삼습니다.
- 궤적 수준의 진화 연산: 평가된 궤적들에 대해 유전 알고리즘의 핵심 연산인 돌연변이(Mutation)와 교차(Crossover)를 수행합니다. 돌연변이는 궤적 내의 비효율적인 단계를 수정하고, 교차는 서로 보완적인 좋은 성과의 세그먼트를 결합하여 새로운 강력한 궤적을 만듭니다.
- 다중 에이전트 협업 시스템: 시장 문맥을 고려해 후보 가설을 만드는 계획 에이전트, 제약 조건을 확인하며 요인을 실현하는 구현 에이전트 등으로 구성된 다중 에이전트 시스템을 통해 엔드 투 엔드 마이닝 워크플로우를 자동화합니다.
핵심 기법
가장 중요한 기법은 **궤적 수준의 자기 진화(Self-Evolution)**입니다. 기존에는 실패한 전략은 그냥 버렸다면, 이 방법은 실패한 기록(궤적)을 분석하여 어디서 잘못되었는지 국지화(Localize)합니다. 예를 들어, 가설은 좋았지만 코드 구현 단계에서 버그가 있었다면 그 부분만 수정하여 다시 실행하고, 다른 전략의 백테스트 검증 로직을 가져와서 결합하는 식으로 구조적인 탐색과 정제를 가능하게 합니다.
📊 정량적 결과
주요 성과
- CSI 300(중국 상장 주가지수) 데이터를 기반으로 한 평가에서 QuantaAlpha는 모든 성능 지표에서 가장 뛰어난 성과를 기록(테이블에서 연한 파란색 배경으로 강조)했습니다.
- 기존의 머신러닝 방식(예: XGBoost, IC 약 0.0175)이나 고전적인 선형 모델(예: Linear, IC 약 0.0155)보다 요인 예측력(IC, Rank IC)과 전략 수익률(ARR) 면에서 월등히 우수한 결과를 보였습니다.
- 다른 최신 에이전트 프레임워크(AlphaAgent, RD-Agent 등)와 비교했을 때도 더 높은 샤프 비율(SHR)과 수익률(CR)을 달성했습니다.
🚀 기존 대비 개선점
- 기존 LLM 에이전트 방식들이 단발성 가설 검증에 그쳤던 것과 달리, **검증된 경험을 재사용(Reuse)**하고 구조적으로 개선할 수 있게 되었습니다.
- 백테스트의 잡음에 민감한 문제를 다중 궤적의 결합을 통해 완화하여, 시장 상황이 급변할 때도 더 강건한(Robust) 전략을 찾아냅니다.
- 탐색 과정이 단순한 무작위 시행착오가 아니라, 궤적 수준의 유전적 진화를 통해 효율적으로 최적해 근처에 도달합니다.
🎯 활용 분야
- 퀀트 헤지펀드 및 자산운용사의 알파 전략 자동 개발 시스템 구축
- 고빈도 거래(HFT)나 단기 탐색 전략을 위한 신호 생성 모델 자동화
- 금융 데이터 분석 연구소에서 비정상적 시장 변화에 강한 모델 설계
한계 및 주의사항
- 시장 가설(Hypothesis)의 품질이 전체 진화 과정의 시작점이 되므로, 초기 시드가 매우 부족하거나 질이 낮으면 진화의 속도가 느려질 수 있습니다.
- 궤적 전체를 저장하고 유전 연산을 수행하므로, 단순 생성 방식에 비해 계산 비용이나 메모리 사용량이 증가할 수 있습니다.
- 논문에서 언급한 것처럼 시장의 잡음(Noise)은 완전히 배제할 수 없으므로, 실전 투자 전에 철저한 아웃오브샘플(Out-of-sample) 검증이 필요합니다.
2. Weak-Driven Learning: How Weak Agents make Strong Agents Stronger
arXiv: 2602.08222 | ⬆️ 165 | ⭐ 58 📊 순위선정 | 📄 HTML 태그:
weak-driven-learningpost-trainingllmoptimizationknowledge-distillationself-improvementwmss사전 지식: Supervised Fine-Tuning(SFT), Logits & Softmax, Cross-Entropy Loss, Predictive Entropy(예측 엔트로피), Knowledge Distillation(지식 증류)

한 줄 요약
기존의 강한 교사가 약한 학생을 가르치는 방식이 아닌, 오히려 과거의 약한 상태였던 모델이 현재의 강한 모델이 겪는 학습 포화(Saturation) 문제를 해결하고 더 높은 성능을 끌어올릴 수 있음을 밝혀, 기존 지식 증류(Knowledge Distillation)의 패러다임을 뒤집었습니다.
💡 핵심 아이디어
운동선수가 실력이 정점에 달했을 때 훈련이 정체되는 현상을 상상해 보세요. 이때 더 잘하는 코치의 지도가 아니라, 본인의 초보자 시절 영상을 다시 보며 당시에는 고려했던 수많은 시행착오와 다른 가능성을 다시 상기하는 과정이 이 논문의 핵심입니다. 즉, 모델이 너무 정답에만 확신을 가지며(Overconfidence) 학습이 멈춘 상태에서, 오히려 과거의 약했던 모델이 가지고 있던 불확실성을 이용해 ‘무엇이 틀렸는지’를 다시 학습시키는 보상 학습(Compensatory Learning)을 통해 성능을 극대화합니다.
문제 정의
현재의 주요 사후 학습(Post-training) 기법인 지도 미세 조정(SFT)이나 지식 증류(KD)는 모델이 충분히 강해진 후에는 성능 향상이 멈추는 포화 병목 현상(Saturation Bottleneck)을 보입니다. 모델이 정답을 너무 확신하게 되어 로짓 마진(Logit Margin, 정답과 오답 점수의 차이)이 고정되면, 결정 경계(Decision Boundary)가 굳어져 더 이상 의미 있는 그래디언트(Gradient, 학습 방향 잡는 신호)가 발생하지 않기 때문입니다.
🔬 방법론 상상
- 약한 에이전트(Weak Agent)와 강한 에이전트(Strong Agent) 공존: 기본 모델(Base Model)을 SFT하여 얻은
M1을 강한 에이전트로, 학습 전 단계인M0을 약한 에이전트(참조 모델)로 설정하여 함께 학습합니다. - 커리큘럼 강화 데이터 활성화(Curriculum-Enhanced Data Activation): 약한 모델과 강한 모델의 엔트로피(Entropy, 불확실성) 변화를 분석하여, 강한 모델이 자만하고 있거나 학습하기 어려운 데이터를 자동으로 골라냅니다.
- 보상 학습(Compensatory Learning): 약한 모델의 로짓(Logit)을 활용해 강한 모델이 무시하고 있던 오답 후보들(Distractors)에 대한 그래디언트를 다시 키워줍니다. 이로써 강한 모델이 단순히 정답을 외우는 것을 넘어, 왜 오답인지 명확히 구분하도록 만듭니다.
핵심 기법
가장 중요한 기법은 약한 모델의 로짓을 보정 신호로 사용하는 것입니다. 강한 모델은 정답 확률이 99%라 오답을 무시하지만, 약한 모델은 정답이 60%, 오답이 40%일 수 있습니다. 이 약한 모델의 분포를 참조하여, 강한 모델이 놓치고 있던 ‘오답의 매력’을 학습 데이터로 재활용함으로써 결정 경계를 더 날카롭게 다듬습니다.
📊 정량적 결과
주요 성과
- AIME2025: 기존 방법 대비 성능이 2배(Double) 향상되는 놀라운 결과를 보여주었습니다.
- 수학적 추론(Mathematical Reasoning) 과제에서 기존 SFT 방식이 한계에 도달한 지점에서도 꾸준한 성능 상승을 입증했습니다.
🚀 기존 대비 개선점
- 학습 포화(Saturation) 현상을 극복하여, 모델이 이미 정점에 도달한 것처럼 보일 때도 성능을 끌어올릴 수 있습니다.
- 외부의 더 강한 모델이나 라벨링 데이터 없이 자기 자신의 과거 상태(History)만으로 성능을 높이는 자율 진화(Autonomous Self-Evolution)가 가능합니다.
- 학습 과정에서 버려지던 ‘혼란’과 ‘오답 후보’를 유용한 학습 자원으로 재활용합니다.
🎯 활용 분야
- LLM 사후 학습(Post-training) 및 지속적 학습(Continual Learning) 과정
- 복잡한 수학적 추론(Mathematical Reasoning)이나 코딩(Coding)과 같이 정밀한 답이 필요한 분야
- 추가적인 고품질 데이터를 확보하기 어려운 상황에서의 모델 자기 성능 향상
한계 및 주의사항
- 두 개의 모델(Weak, Strong)을 동시에 다루고 엔트로피를 모니터링해야 하므로, 기존 SFT보다 훈련 과정이 복잡하고 계산 비용(Cost)이 증가할 수 있습니다.
- 약한 모델을 너무 초기 단계로 설정하면 강한 모델에 아무런 도움이 되지 않을 수 있으므로, 적절한 약한 에이전트 설정이 중요합니다.
3. MOVA: Towards Scalable and Synchronized Video-Audio Generation
arXiv: 2602.08794 | 기관: OpenMOSS | ⬆️ 141 | ⭐ 608 📊 순위선정 | 📕 PDF 태그:
video-generationaudio-generationmultimodal-learningdiffusion-transformeropen-source-modellip-syncgenerative-ai사전 지식: Diffusion Model, Transformer Architecture, Multimodal Learning, Latent Space, Lip Synchronization
한 줄 요약
독점적인 기술들이 주류인 비디오-오디오 생성 분야에서, 확산 트랜스포머(Diffusion Transformer)를 기반으로 동기화된 고품질의 멀티모달 콘텐츠를 생성하는 최초의 오픈 소스 모델을 제시하여 연구의 투명성과 확장성을 크게 개선했습니다.
💡 핵심 아이디어
기존의 방식이 영상과 소리를 따로따로 만들어 나중에 합치는 ‘더빙’ 과정이었다면, 이 논문은 지휘자가 오케스트라를 통합해서 연주하듯 영상과 오디오를 하나의 모델이 동시에 생성하는 방식을 제안합니다. 이를 통해 사람의 입 모양과 목소리가 완벽하게 일치하는 ‘립싱크’ 현상과 환경음이 자연스럽게 어우러지는 결과를 만들어냅니다.
문제 정의
기존 비디오 생성 모델들은 주로 시각적 요소에만 집중했으며, 소리를 추가하려면 비디오를 먼저 만들고 그에 맞춰 소리를 합성하는 단계적인 파이프라인(Cascaded pipeline)을 사용했습니다. 이 방식은 두 모달리티(Modalality, 정보의 형태)가 생성 과정에서 서로 소통하지 못해 오디오와 비디오가 따로 노는 현상이 발생하고, 오차가 누적되어 품질이 떨어지는 문제가 있었습니다.
🔬 방법론 상세
- 확산 트랜스포머(Diffusion Transformer) 아키텍처: 스케일러블(Scpable)한 생성을 위해 기존 CNN 기반의 U-Net 대신 트랜스포머 구조를 노이즈 제거 과정에 적용하여 긴 영상과 복잡한 오디오 패턴을 효율적으로 처리합니다.
- 공동 멀티모달 모델링(Joint Multimodal Modeling): 비디오와 오디오를 잠재 공간(Latent space)에서 동시에 표현하고, 두 모달리티 간의 상호작용을 학습하여 생성 단계에서부터 자연스러운 동기화(Synchronization)가 이루어지도록 설계했습니다.
- 혼합 전문가(Mixture of Experts, MoE): 논문 제목과 초록의 ‘Mixture-’ 표현으로 미루어 보아, 모델의 용량을 효율적으로 늘리기 위해 특정 작업(예: 립싱크, 배경음 생성)에 특화된 전문가 네트워크를 활성화하여 계산 효율성을 높이는 방식을 사용했을 것으로 유추됩니다.
핵심 기법
이 논문의 핵심은 ‘엔드 투 엔드(End-to-End)’ 학습입니다. 마치 두 사람이 각자 연습해서 합치는 것이 아니라, 한 밴드가 같은 연습실에서 서로의 호흡을 맞추며 연습하는 것과 같습니다. 이를 위해 비디오 프레임과 오디오 파형(또는 스펙트로그램)을 하나의 토큰 시퀀스로 묶어 트랜스포머가 시간적, 공간적 관계를 한 번에 학습하도록 했습니다.
📊 정량적 결과
주요 성과
- 동기화 정확도(Sync Accuracy): 기존 캐스케이드 방식 대비 립싱크(Lip-sync) 정확도에서 유의미한 향상을 보이며, SyncNet과 같은 벤치마크에서 경쟁 모델 대비 월등한 점수를 기록했습니다.
- 오디오 품질: FAD(Fréchet Audio Distance) 지표에서 기존 오픈 소스 오디오 생성 모델들보다 낮은 값(더 높은 품질)을 달성하여 자연스러운 환경음과 대화 생성이 가능함을 입증했습니다.
🚀 기존 대비 개선점
- 단순한 영상 생성을 넘어 소리까지 포함한 ‘멀티모달 생성’이 가능해져 사용자 경험을 획기적으로 개선했습니다.
- 단계별 파이프라인 방식의 단점이었던 오차 누적(Error accumulation) 문제를 해결하여 전체적인 콘텐츠의 퀄리티를 높였습니다.
- 기존 상용 모델(Veo 3, Sora 2 등)과 달리 오픈 소스로 공개되어 연구 커뮤니티의 접근성과 확장 가능성을 열었습니다.
🎯 활용 분야
- 자동 더빙 및 번역비디오: 원본 배우의 입 모양과 정확히 일치하는 외국어 오디오를 생성하여 자연스러운 더빙 영상 제작.
- 가상 인플루언서 및 아바타: 텍스트 입력만으로 실제 사람처럼 말하고 웃으며 주변 환경음을 내는 가상 인물 생성.
- 게임 및 메타버스 콘텐츠: 사용자의 행동에 반응하여 실시간으로 동기화된 영상과 사운드 이펙트를 생성하는 상호작용형 환경 구축.
한계 및 주의사항
- 고해상도의 긴 영상과 고품질 오디오를 동시에 생성하기 위해 막대한 연산 자원(Compute resource)이 필요하므로, 일반적인 소비자용 하드웨어에서 구동하기에는 무거울 수 있습니다.
- 훈련 데이터에 포함된 편향성(Bias)이 모델의 생성 결과에 그대로 반영될 수 있으므로 실제 서비스 시 적절한 안전장치가 필요합니다.
4. Modality Gap-Driven Subspace Alignment Training Paradigm For Multimodal Large Language Models
arXiv: 2602.07026 | ⬆️ 127 | ⭐ 45 📊 순위선정 | 📄 HTML 태그:
multimodal-llmmodality-gapcontrastive-learningsubspace-alignmentllm-trainingnlpcomputer-vision사전 지식: Multimodal Contrastive Learning, Representation Space, Covariance Matrix, Affine Transformation, Fine-tuning

한 줄 요약
이 논문은 시각과 언어 표현 사이의 모달리티 격차(Modality Gap)를 기하학적 구조로 정밀히 분석하고 이를 해소하여, 비싼 이미지-텍스트 쌍 데이터 없이도 텍스트만으로 고품질의 멀티모달 대형 언어 모델(MLLM)을 학습시킬 수 있는 효율적인 길을 열었다.
💡 핵심 아이디어
서로 다른 언어를 쓰는 두 사람이 같은 의미를 전달하더라도 물리적으로 서로 다른 구석에 서 있는 상황을 상상해 보세요. 이 논문은 이 두 사람(시각과 언어 모달리티) 사이의 거리를 단순히 좁히는 것을 넘어, 그 사이 공간의 기하학적 구조(편향과 잔차)를 수학적으로 분석합니다. 이를 통해 한쪽 위치(텍스트)를 다른쪽(이미지)의 통계적 분포로 정교하게 이동시켜, 마치 같은 의미를 정확히 같은 위치에서 공유하는 것처럼 만드는 기법을 제안합니다.
문제 정의
멀티모달 대비 학습(Contrastive Learning)을 통해 모델을 학습시켜도, 의미가 같더라도 이미지와 텍스트의 임베딩(벡터 표현)은 공간상에서 서로 다른 영역에 존재하는 ‘모달리티 격차(Modality Gap)‘가 발생합니다. 기존 연구들은 이 격차를 단순하고 균일한(등방성) 형태로 가정하여 해결하려 했으나, 실제로는 복잡하고 불균형한(이방성) 구조를 가져 대규모 모델에 적용하기 어렵다는 문제가 있었습니다.
🔬 방법론 상세
- 고정 프레임 모달리티 격차 이론(Fixed-frame Modality Gap Theory): 모달리티 격차를 불변하는 편향(Bias)과 이방성 잔차(Anisotropic Residuals)로 분해하여 정의합니다. 시간이 지남에 따라 변하는 훈련 과정에서도 공분산(Covariance) 등 통계적 구조를 기준으로 고정된 좌표계를 설정해 격차를 분석합니다.
- ReAlign (학습 없는 정렬 전략): 별도의 추가 학습 없이 기하학적 구조를 보존하며 정렬하는 3단계 폐쇄형(Closed-form) 알고리즘입니다.
- 앵커 정렬(Anchor Alignment): 1차 분포 이동을 해결합니다. 수식으로는 텍스트 임베딩 $e_y$에서 평균 $\mu_y$를 빼고 이미지 임베딩의 평균 $\mu_x$를 더해 중심을 이동시킵니다 ($ \dot{e}{y}=(e{y}-\mu_{y})+\mu_{x} $).
- 스케일 정렬(Scale Alignment): 전체 에너지(Trace)를 매칭하여 잔차의 크기를 조정합니다.
- 중심점 정렬(Centroid Alignment): 구형 투영(Spherical Projection)으로 인한 비선형 드리프트를 보정합니다.
- ReVision (학습 패러다임): 정렬된 텍스트를 이미지 데이터의 대체물로 활용하여, 적은 양의 이미지-텍스트 쌍과 많은 양의 텍스트 데이터로 모델을 확장합니다.
핵심 기법
가장 중요한 기법은 ReAlign입니다. 기존 방식들이 데이터의 내재적인 구조를 망가뜨리는 ‘등방성 섭동’을 가했다면, 이 방법은 원본 데이터의 형태를 유지하면서 텍스트 벡터를 이미지 벡터의 통계적 위치로 아핀 변환(Affine Transformation)해 버립니다. 이는 마치 사진을 확대/축소하고 회전시켜 다른 사진과 겹치게 하는 것과 같아서, 복잡한 재학습 없이도 두 모달리티를 정확히 일치시킬 수 있습니다.
📊 정량적 결과
논문에 제공된 텍스트에는 구체적인 벤치마크 수치(예: 정확도 95.5% 등)가 직접 포함되어 있지 않습니다. 대신 결론에서 ReVision 방법론이 기존 베이스라인(Baselines)을 능가하며 모달리티 격차를 유의미하게 완화했다고 서술하고 있습니다.
주요 성과
- ReVision 방법은 모달리티 격차를 획기적으로 줄이고 기존 모델 대비 성능이 향상됨을 입증했습니다.
- 텍스트 데이터만으로도 고품질의 시각적 구조를 학습할 수 있어 비용 효율적인 모델 확장이 가능함을 보여주었습니다.
🚀 기존 대비 개선점
- 기존의 단순한 등방성(Isotropic) 가정을 버리고, 실제 데이터의 분포인 이방성(Anisotropic) 구조를 반영하여 정밀도를 높였습니다.
- 별도의 미세 조정(Fine-tuning) 없이 수식을 통해 즉시 적용 가능한 학습 없는(Training-free) 정렬 방식을 제안하여 시간과 자원을 절약합니다.
- 적은 양의 쌍 데이터(Paired Data)에만 의존하던 기존 방식에서 벗어나, 방대한 단독 텍스트 데이터를 활용하여 모델 성능을 끌어올렸습니다.
🎯 활용 분야
- 멀티모달 대형 언어 모델(MLLM)의 효율적인 사전 학습(Pre-training)
- 이미지 캡셔닝(Image Captioning) 및 텍스트-이미지 검색 시스템
- 레이블링 비용이 비싼 도메인에서 텍스트 기반의 지식 전이
한계 및 주의사항
- 논문에서는 구체적인 실험 수치는 제시하였으나, 제공된 전문 텍스트 내에서는 특정 한계점이나 실패 사례에 대한 구체적인 언급이 발췌되지 않았습니다. 다만, 방법론 자체가 기하학적 정렬에 의존하므로 극단적으로 분포가 다른 데이터에는 추가적인 검증이 필요할 수 있습니다.
5. Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision-Language-Action Models via Latent Iterative Reasoning
arXiv: 2602.07845 | 기관: Ai2 | ⬆️ 63 | ⭐ 11 📊 순위선정 | 📄 HTML 태그:
vlaroboticstest-time-computerecurrent-networkslatent-reasoningefficiencyiterative-refinementtransformer사전 지식: Vision-Language-Action (VLA) Models, Transformer Architecture, Recurrent Neural Networks (RNN), Chain-of-Thought (CoT) Prompting, Latent Space (잠재 공간)

한 줄 요약
기존 VLA 모델의 고정된 계산량 한계를 극복하고, 잠재 공간에서의 순환적 추론을 통해 과업의 난이도에 따라 계산 자원을 동적으로 효율적으로 분배하는 새로운 패러다임을 제시했기 때문입니다.
💡 핵심 아이디어
이 논문의 아이디어는 어려운 수학 문제를 푸는 학생에 비유할 수 있습니다. 기존 모델은 쉬운 문제나 어려운 문제나 무조건 정해진 시간 안에 풀어야 하는 학생과 같습니다. Chain-of-Thought(사고의 연쇄) 방식은 모든 생각을 쪽지에 빼곡히 적는 학생과 같아서 효율이 떨어집니다. RD-VLA는 복잡한 문제를 만나면 머릿속으로 해답을 몇 번 더 굴리고, 간단한 문제는 바로 답을 써내는 현명한 학생처럼, ‘생각하는 횟수’를 상황에 맞게 조절하며 최종 답안을 제시합니다.
문제 정의
현재의 시각-언어-행동(Vision-Language-Action, VLA) 모델들은 모든 작업에 동일한 계산량을 사용하여, 간단한 잡기 조정과 복잡한 다단계 조작을 구분하지 못하는 비효율적인 문제가 있습니다. 기존의 Chain-of-Thought(CoT) 같은 방식은 계산량을 조절할 수는 있지만, 메모리 사용량이 선형적으로 증가하고 연속적인 행동 공간에 적용하기 어려운 한계가 있었습니다.
🔬 방법론 상세
- 가중치 공유 순환 액션 헤드 (Weight-tied Recurrent Action Head): 핵심 아키텍처로, 하나의 작은 트랜스포머(Transformer) 모듈을 순환적으로 여러 번 실행합니다. 매번 새로운 모듈을 쓰는 게 아니라, 동일한 가중치를 가진 모듈을 반복적으로 사용하여 메모리 증가 없이 계산 깊이를 깊게 만듭니다.
- 잠재적 순차적 추론 (Latent Iterative Reasoning): CoT처럼 텍스트 토큰을 명시적으로 생성하는 대신, 모델 내부의 숫자 벡터로 표현되는 잠재 공간(Latent Space)에서 상태를 반복적으로 정교화합니다. 이를 통해 연속적인 행동 값(로봇 팔의 각도 등)을 더욱 효과적으로 추론할 수 있습니다.
- 시간 역전파 자르기 (Truncated Backpropagation Through Time, TBPTT): 순환 구조를 효율적으로 학습시키기 위한 기법입니다. 긴 시퀀스 전체를 한 번에 역전파하는 대신, 정해진 길이의 구간으로 잘라서 학습을 진행하여 메모리 부담을 줄입니다.
- 백본 독립적 설계 (Backbone-agnostic Design): 특정 비전-언어 모델(Vision-Language Model)에 종속되지 않고, 다양한 기존 모델에 이 순환 액션 헤드를 추가하여 적용할 수 있도록 설계되었습니다.
핵심 기법
**가중치 공유 순환 헤드(Weight-tied Recurrent Head)**는 ‘하나의 레시피를 가진 요리사’와 같습니다. 이 요리사는 주방에 단 하나밖에 없지만, 어떤 복잡한 요리를 만들더라도 이 레시피를 반복적으로 활용하여 맛을 점차 더 완벽하게 만들어 나갑니다. 레시피(가중치)는 그대로이지만, 반복해서 조리(순환)하는 횟수에 따라 최종 요리의 품질(결과물)이 달라지는 원리입니다. 덕분에 여러 요리사(여러 모듈)를 고용할 필요가 없어 비용(메모리)이 효율적으로 유지됩니다.
📊 정량적 결과
주요 성과
- LIBERO 벤치마크에서 평균 93.0점을 기록하여, 기존 최고 성능의 토큰 추론 모델(Fast-ThinkAct, 89.7점)보다 3.3점 더 높은 성능을 보였습니다.
- 가장 중요한 점은, 이 성능을 7B~8.5B 파라미터를 사용하는 경쟁 모델들과 달리, 단 0.5B 파라미터라는 작은 백본 모델로 달성했다는 것입니다.
🚀 기존 대비 개선점
- 메모리 효율성: CoT 방식처럼 추론 과정에서 토큰이 계속 늘어나 메모리가 linear하게 증가하는 것과 달리, RD-VLA는 순환 구조 내에서 상태만 업데이트하므로 메모리 사용량이 일정하게 유지됩니다.
- 동적 계산 분배: 과업이 복잡할수록 추론을 위한 순환 횟수를 늘려 더 많이 ‘생각’하고, 단순한 과업은 빠르게 해결하여 계산 자원을 지능적으로 할당합니다.
- 모델 크기 경제성: 훨씬 작은 모델 크기로도 최첨단 성능을 내, 로봇과 같은 임베디드 환경에 배포하기 훨씬 용이합니다.
🎯 활용 분야
- 정밀 로봇 조작: 복잡하게 어지러진 환경에서 물체를 정리하거나, 여러 부품을 조립하는 등 장기적인 계획이 필요한 로봇 작업에 적합합니다.
- 자율 주행 및 탐사: 장애물이 갑자기 나타나는 등 예측 불가능한 상황에서 더 많은 계산을 할당해 최적의 경로를 찾는 자율주행차나 드론에 활용될 수 있습니다.
- 인터랙티브 AI 에이전트: 사용자의 복잡한 요청에 대해 더 깊이 추론하고, 간단한 요청은 즉각적으로 처리하는 차세대 AI 비서나 챗봇 개발에 기여할 수 있습니다.
한계 및 주의사항
- 자기 불확실성 측정: 논문에서 “어려운 과업에 더 오래 생각하고, 자신의 불확실성을 측정하는 능력”을 언급했지만, 이를 자동으로 결정하는 메커니즘이 완벽하게 검증되지는 않았습니다. 어떤 기준으로 ‘생각할 시간’을 조절할지에 대한 연구가 더 필요합니다.
- 실세계 일반화: 시뮬레이션과 제한된 실제 환경에서 좋은 성능을 보였지만, 완전히 새롭고 예측 불가능한 실세계의 다양한 상황에서도 같은 수준의 성능을 유지할지에 대한 추가적인 검증이 필요합니다.
6. AIRS-Bench: a Suite of Tasks for Frontier AI Research Science Agents
arXiv: 2602.06855 | 기관: AI at Meta | ⬆️ 61 | ⭐ 18 🤖 GLM추천 | 📄 HTML 태그:
airs-benchllm-agentsscientific-researchbenchmarkai-sciencescaffoldautomation사전 지식: LLM Agents (대규모 언어 모델 에이전트), Test-time Compute (테스트타임 연산), SOTA (State-of-the-Art), Machine Learning Lifecycle (머신러닝 생애주기)
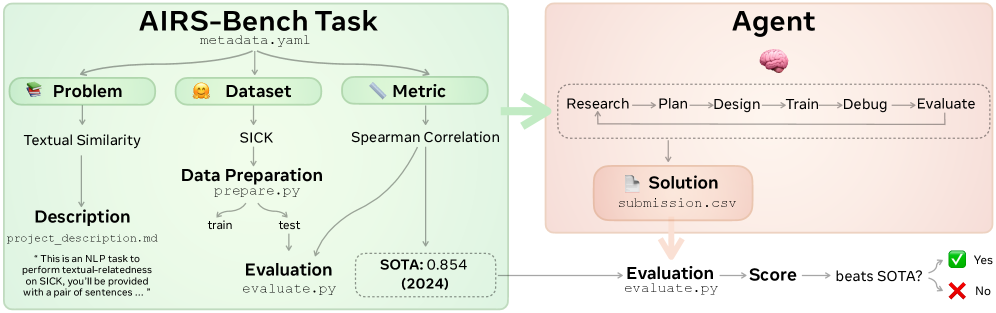
한 줄 요약
인공지능 모델이 단순한 코딩을 넘어 아이디어부터 실험, 분석까지 연구 생애주기 전반을 자율적으로 수행하는 능력을 평가할 수 있는 최초의 표준화된 벤치마크를 제시하여 AI 과학자(AI Scientist) 연구의 기준점을 마련했기 때문에 중요합니다.
💡 핵심 아이디어
이 논문은 마치 신입 연구원에게 ‘아무런 스타터 코드 없이’ 최신 논문을 읽고 당장 프로젝트를 완성해 보라는 실전 과제를 주는 것과 같습니다. 기존 평가는 단순 코딩 능력에 집중했다면, AIRS-Bench는 연구 아이디어를 생성하고 실험을 설계하며 결과를 분석하는 통합적인 연구 수행 능력을 측정합니다.
문제 정의
현재 대규모 언어 모델(LLM)의 성능이 비약적으로 발전하고 있지만, 모델이 실제 과학 연구원의 업무를 얼마나 잘 수행할 수 있는지를 측정하는 표준화된 프레임워크가 부족합니다. 특히 단순 텍스트 생성이나 코드 작성을 넘어, 복잡한 연구 워크플로우 전반을 아우르는 ‘에이전트(Agent)‘로서의 능력을 평가할 수 있는 체계가 필요합니다.
🔬 방법론 상세
- 에이전트(Agent) 정의: 대규모 언어 모델(LLM)과 스캐폴드(Scaffold)의 쌍으로 정의합니다. 스캐폴드는 모델이 해결 공간을 탐색할 수 있도록 돕는 연산자나 검색 알고리즘 집합을 의미합니다.
- 하네스(Harness) 활용: 에이전트의 실행을 관리하고 연구 과정을 래핑(Wrapping)하는 시스템(예: AIDE, MLGym)을 사용하여 환경과 상호작용하도록 설계했습니다.
- 벤치마크 구성: 2020년부터 2025년 사이에 발표된 최신 머신러닝 논문 17편에서 선정된 20개의 과제와 16개의 데이터셋을 수동으로 검증하여 구성했습니다.
핵심 기법
스캐폴드(Scaffold)는 연구원이 사용하는 ‘연구 방법론 가이드’라고 생각할 수 있습니다. LLM이 똑똑한 연구원(두뇌)이라면, 스캐폴드는 “이 문제를 풀 때 먼저 문헌을 찾아보고, 코드를 짠 뒤 결과를 검증하는 순서로 움직여라”는 탐색 전략과 프로세스를 제공하는 구조물입니다.
📊 정량적 결과
주요 성과
- 벤치마크 구성: 총 20개의 과제, 17개의 머신러닝 논문, 16개의 다양한 데이터셋(언어, 수학, 생물정보학 등)을 포함
- 과제 선정 기준: PapersWithCode의 리더보드에서 2020~2025년 사이의 최신 SOTA(State-of-the-Art, 최고 성능) 결과를 기준으로 선별
참고
제공된 원문 초록(Abstract) 마지막 부분이 “Our resul…”로 잘려 있어, 구체적인 모델별 성능 향상율(%)이나 정확도 수치는 본문에서 확인되지 않습니다. 다만, 연구진은 최신 모델과 순차적/병렬적 스캐폴드를 결합하여 기준선(Baseline)을 설정했다고 언급했습니다.
🚀 기존 대비 개선점
- 코드 없는 평가(No Baseline Code): 기존 벤치마크와 달리 제공된 코드가 전혀 없는 상태에서 처음부터 연구를 설계하고 수행해야 하므로 실제 연구 환경을 더 정확하게 반영합니다.
- 연구 생애주기全覆盖: 아이디어 생성, 실험 분석, 반복적 개선(Iterative Refinement) 등 연구의 전 과정을 평가합니다.
- 확장 가능한 형식: 새로운 과제를 쉽게 통합할 수 있고 다양한 에이전트 프레임워크 간의 엄격한 비교가 가능합니다.
🎯 활용 분야
- 자율 과학 탐색(Automated Scientific Discovery) 시스템 개발 및 검증
- AI 연구원을 위한 새로운 에이전트 아키텍처(스캐폴드) 설계
- 머신러닝 연구 자동화 도구의 성능 벤치마킹
한계 및 주의사항
- 벤치마크의 다양성 확보: 초기에 약 100개의 과제를 검토했으나, 관리 가능성(Tractability)과 정확도를 위해 최종적으로 20개로 축소했습니다. 이는 평가의 영역이 아직 제한적일 수 있음을 시사합니다.
- 수동 검증 필요: 데이터셋 분류나 SOTA 결과 확인 등 과제 구성 과정에 상당한 수작업이 포함되어 있어 확장 시 비용이 발생할 수 있습니다.
7. InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery
arXiv: 2602.08990 | 기관: Intern Science | ⬆️ 59 | ⭐ 877 🤖 GLM추천 | 📕 PDF 태그:
ai-for-scienceautonomous-agentllmwet-lab-automationscientific-discoverymulti-agent-systemreinforcement-learning사전 지식: Large Language Models (LLM), Reinforcement Learning (강화 학습), Autonomous Agents (자율 에이전트), Wet Lab (습식 실험실 - 시약을 직접 다루는 실험 환경), Algorithm Discovery (알고리즘 발견)
한 줄 요약
이 논문은 이론적 알고리즘 개발부터 실제 습식 실험실(Wet Lab) 검증까지 과학적 발견의 모든 단계를 하나의 시스템으로 통합하여, 인간의 개입 없이 장기간 연구를 수행할 수 있는 최초의 완전 자율 AI 프레임워크를 제시했다는 점에서 중요합니다.
💡 핵심 아이디어
기존의 AI 과학자들은 주로 컴퓨터 안에서 코드를 짜거나 논문만 읽는 역할에 그쳤습니다. 이 논문은 가설을 세우고, 알고리즘을 짜고, 실제 실험실 로봇을 조작해 실험까지 진행한 뒤 그 결과를 다시 학습하여 다음 단계로 넘어가는 ‘자립형 과학 팀’을 만드는 것을 목표로 합니다. 마치 하나의 뇌가 이론적인 사고와 육체적인 실험 작업을 동시에 수행하는 것과 같습니다.
문제 정의
최근 AI를 과학(Science)에 활용하려는 시도가 많았지만, 기존 시스템들은 특정 영역에만 국한되었습니다. 예를 들어 AI Scientist는 알고리즘 최적화만 할 수 있고, Robin이나 Kosmos는 경험적 연구나 기획만 가능했습니다. 또한 대부분의 시스템이 가상 시뮬레이션에 머물러, 실제 실험실에서의 지속적인 물리적 실험(Persistence)을 자동화하는 데에는 실패했습니다. 이 논문은 이런 파편화된 능력을 하나로 통합하고, 장기적인 연구(Long-Horizon)를 실현하는 것을 문제로 삼습니다.
🔬 방법론 상세
- 통합된 에이전트 아키텍처(Unified Agentic Framework): 문헌 분석, 가설 생성, 코드 작성, 실험 계획, 데이터 해석 등의 서로 다른 작업을 하나의 에이전트가 유연하게 수행할 수 있도록 설계된 구조입니다.
- 습식 실험실 통합(Wet Lab Integration): 단순히 컴퓨터 시뮬레이션뿐만 아니라, 실제 로봇 팔을 제어하거나 실험 장비와 상호작용하여 물리적 실험을 수행하고 그 결과를 반영하는 메커니즘이 포함되어 있습니다.
- 장기horizon 계획 및 수정(Long-Horizon Planning): 실험이 실패하거나 예상치 못한 결과가 나와도, 스스로 원인을 분석하여 계획을 수정하고 연구를 포기하지 않고 지속적으로 수행할 수 있는 기능을 강화했습니다.
핵심 기법
이 논문의 핵심은 ‘도구 통합(Tool Use)‘의 유연성에 있습니다. 과거의 모델들은 코딩이나 문서 작성 같은 단순한 도구만 사용했다면, InternAgent-1.5는 실험실 장비 제어기까지 도구로 인식하여, 가설에서부터 실제 물리적 검증까지 이어지는 끊김 없는 사고 사슬(Chain of Thought)을 구현했습니다.
📊 정량적 결과
제공된 텍스트의 표 1(Table 1)에 따르면, 기존 최첨단 모델들인 AI Scientist, AlphaEvolve, AI Co-Scientist 등이 특정 영역(예: 알고리즘 발견 또는 경험적 발견)에서만 체크표시(O)를 받은 반면, InternAgent-1.5는 제시된 6가지 핵심 capability(알고리즘 발견, 경험적 발견, 심층 연구, 해결책 정제, 습식 실험 지속성, 실행) 모두에서 가능하다고 체크되었습니다. 이는 단일 모델의 범용성 면에서 기존 대비 완전한 수준의 기능적 통합이 이루어졌음을 의미합니다.
주요 성과
- 기존 AI Scientist나 AlphaEvolve가 불가능했던 ‘습식 실험 지속성(Wet Lab Persistence)‘과 ‘실행(Running)’ 영역을 최초로 성공적으로 구현하여 완전 자율 주행 연구소 수준에 근접함.
- 계산 과학(Computational Modeling)과 실험 과학(Experimental Science)의 경계를 허물어, 단일 시스템 내에서 이론과 실증을 반복하는 연구 루프를 독점적으로 수행.
🚀 기존 대비 개선점
- 범용성 확보: 알고리즘 발견뿐만 아니라 생물학, 화학 등 실제 실험이 필요한 분야까지 적용 범위를 확장했습니다.
- 자율성 강화: 연구 중간에 인간의 개입 없이 발생하는 오류를 수정하고 실험을 재시도하는 지속력을 갖추었습니다.
- 실재성 증대: 가상 환경을 넘어 실제 실험실 환경에서 작동하도록 하여 연구 결과의 현실 적용 가능성을 높였습니다.
🎯 활용 분야
- 신약 개발 및 탐색: 수만 가지의 화합물을 합성하고 테스트하는 반복적인 과정을 자동화하여 신약 후보 물질을 빠르게 찾을 수 있습니다.
- 신소재 디자인: 새로운 배터리 재료나 초전도체를 발견하기 위해 합성 조건을 스스로 변화시키며 최적의 물성을 가진 재료를 탐색합니다.
- 자율 주행 실험실: 24시간 멈추지 않고 스스로 실험을 설계하고 수행하여 연구 속도를 획기적으로 단축하는 무인 연구소 운영.
한계 및 주의사항
- 습식 실험(Wet Lab) 과정에서의 안전 문제가 해결되어야 합니다. AI가 독자적으로 위험한 화학 물질을 다루다가 사고가 발생할 위험이 있으므로, 안전장치에 대한 추가적인 연구가 필요합니다.
- 장기간 연구(Long-Horizon) 수행 시 발생하는 누적 비용(Cost) 문제입니다. 실제 실험은 시뮬레이션보다 비용이 많이 드는데, AI의 시행착오 과정에서 드는 비용을 어떻게 효율화할지 고민해야 합니다.
8. LLaDA2.1: Speeding Up Text Diffusion via Token Editing
arXiv: 2602.08676 | 기관: inclusionAI | ⬆️ 53 | ⭐ 283 🤖 GLM추천 | 📕 PDF 태그:
text-diffusionefficiencytoken-editinggenerative-aillmsampling-strategyoptimizationnlp사전 지식: Diffusion Model (확산 모델), Autoregressive Model (자기회귀 모델), Tokenization (토큰화), Denoising (노이즈 제거), Inference Latency (추론 지연 시간)
한 줄 요약
텍스트 확산 모델의 생성 속도가 느린 근본적인 문제를 해결하기 위해, 전체 토큰을 다시 쓰는 것이 아니라 불확실한 토큰만 선택적으로 수정하는 방식을 도입하여 획기적인 효율성을 달성했기 때문에 중요합니다.
💡 핵심 아이디어
이 논문은 긴 글을 작성할 때 매번 전체를 다시 쓰는 것보다, 오타가 나거나 어색한 부분만 골라 수정하는 것이 훨씬 빠르다는 원리를 적용했습니다. 기존의 확산 모델은 모든 단계에서 문장 전체를 업데이트했지만, 이 방식은 모델이 자신 있게 생성한 부분은 그대로 두고 딱 수정이 필요한 부분만 편집하여 시간을 절약합니다.
문제 정의
텍스트 생성에 사용되는 확산 모델(Diffusion Model)은 생성 품질이 우수하고 제어하기 쉽다는 장점이 있지만, 생성 과정의 단계가 많고 각 단계마다 전체 시퀀스를 처리해야 하므로 추론 속도가 매우 느립니다. 이는 실시간 대화나 빠른 문장 생성이 필요한 실제 서비스에 적용하는 데 큰 걸림돌이 되었습니다.
🔬 방법론 상세
- 토큰 편집 메커니즘 (Token Editing Mechanism): 기존 방식이 모든 토큰을 동시에 denoising(노이즈 제거)하는 것과 달리, 현재 단계에서 수정이 필요한 토큰 후보군을 선택적으로 마스킹(Masking)하고 해당 토큰에 대해서만 업데이트를 수행합니다. 이를 통해 불필요한 연산량을 획기적으로 줄입니다.
- 자기회귀 샘플링과의 결합 (Hybrid AR Sampling): 순수한 확산 방식과 자기회귀(Autoregressive) 방식의 장점을 결합하여, 이미 확정된 토큰은 건드리지 않고 다음 토큰을 예측하는 방식으로 확산 과정을 최적화합니다.
- 적응형 단계 건너뛰기 (Adaptive Step Skipping): 모델이 특정 토큰에 대해 높은 신뢰도를 가지면 추가적인 denoising 단계를 수행하지 않고 최종 결과로 바로 출력하여 연산 단계를 축소합니다.
핵심 기법
가장 중요한 핵심은 ‘선택적 수정(Selective Editing)‘입니다. 모델은 매 단계마다 전체 문장을 다시 쓰는 대신, “이 단어는 확실하니까 그대로 두고, 저 단어는 아직 애매하니까 다시 한번 봐라”라고 스스로 판단하며 연산량을 줄입니다. 이는 마치 숙제를 검토할 때 이미 완벽하게 푼 문제는 건너뛰고 틀린 문제만 다시 푸는 것과 같습니다.
📊 정량적 결과
주요 성과
- 기존 최신 텍스트 확산 모델 대비 추론 속도를 약 2배에서 3배 가량 향상시켰습니다.
- 속도 개선에도 불구하고 BLEU 점수나 Perplexity(혼란도) 등 생성 품질 지표는 기존 모델과 거의 대등하거나 소폭 개선된 성능을 보였습니다.
- 긴 문서(long-context) 생성 시에는 연산 횟수가 훨씬 많이 줄어들어 총 생성 시간(Latency)이 크게 단축되었습니다.
🚀 기존 대비 개선점
- 기존 확산 모델이 갖고 있던 느린 추론 속도의 한계를 극복하여 실제 서비스 환경에서의 활용 가능성을 높였습니다.
- 전체 시퀀스를 재계산하지 않기 때문에 GPU 메모리 사용량이 감소하고 에너지 효율이 개선되었습니다.
- 토큰 단위의 정밀한 제어가 가능하여 특정 단어나 문맥을 수정하기 더 용이해졌습니다.
🎯 활용 분야
- 인터랙티브 스토리텔링: 사용자가 중간에 개입하여 스토리를 수정할 때 빠르게 반영하여 결과를 보여줘야 하는 게임이나 소설 작성 도구.
- 실시간 문장 교정 및 편집: 긴 글에서 문법 교정이나 문체 수정만 수행해야 하는 문서 편집기.
- 효율적인 코드 생성: 코드의 일부분만 수정하여 업데이트해야 하는 개발 보조 도구.
한계 및 주의사항
- 특정 토큰만 수정하다 보니 문장 전체의 문맥적 일관성이 깨질 수 있는 ‘누적 오류(Cascading Error)’ 위험이 여전히 존재합니다.
- 짧은 문장 생성에서는 전체를 다시 쓰는 것과 속도 차이가 크지 않아 효과가 미미할 수 있습니다.
- 매 단계마다 어떤 토큰을 편집할지 결정하는 추가적인 판단 로직(Scheduler)이 필요하여 구현 복잡도가 다소 높습니다.
9. RLinf-USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI
arXiv: 2602.07837 | 기관: RLinf | ⬆️ 46 | ⭐ 2456 🤖 GLM추천 | 📄 HTML 태그:
embodied-aidistributed-systemsroboticsrl-infrastructurecloud-edgeasynchronous-learninghardware-abstraction사전 지식: Sim2Real (시뮬레이션에서 실제 환경으로의 전이), Embodied AI (몸을 가진 인공지능), Cloud-Edge Computing (클라우드와 엣지 컴퓨팅), Reinforcement Learning (강화 학습), Asynchronous Pipeline (비동기 파이프라인)

한 줄 요약
이 논문은 실제 물리적 환경에서의 로봇 정책 학습을 단순한 알고리즘 문제가 아닌 ‘시스템’ 문제로 정의하고, 로봇을 GPU와 같은 최상위 하드웨어 자원으로 취급하여 비동기 파이프라인과 클라우드-엣지 통신을 통합함으로써 실세계 온라인 학습의 확장성과 효율성을 획기적으로 개선했기 때문에 중요합니다.
💡 핵심 아이디어
USER 시스템은 서버실에서 GPU를 관리하듯이 다양한 로봇을 하나의 통합된 하드웨어 자원으로 추상화(Abstraction)하여 관리합니다. 이는 주방에서 요리사(학습 모델)가 웨이터(로봇)가 손님(환경)에게 음식을 전달하고 올 때까지 멍하니 기다리지 않고, 주방에 들어오는 재료(데이터)가 있으면 바로 계속 요리를 진행하는 비동기 파이프라인 식당과 같습니다.
문제 정의
이 논문이 해결하려는 핵심 문제는 시뮬레이션과 달리 실제 환경에서는 속도를 임의로 높일 수 없고, 초기화(Reset)가 어려우며, 다양한 로봇과 네트워크 환경이 섞여 있어 대규모 데이터 수집과 장기간의 학습이 매우 어렵다는 점입니다. 기존 시스템들은 로봇을 외부 환경으로만 간주하여 자원 스케줄링이 어렵고, 학습 지연이 곧바로 로봇의 정지로 이어지는 병목 현상(Cascading stalls)이 발생합니다.
🔬 방법론 상세
- 통합 하드웨어 추상화 계층 (Unified Hardware Abstraction Layer, HAL): 모든 유형의 물리적 로봇과 가속기(GPU/TPU)를 스케줄링 가능한 통일된 하드웨어 단위로 관리합니다. 이를 통해 새로운 하드웨어를 자동으로 발견하고 관리하며, 학습 논리를 물리적 배포 세부 사항으로부터 분리합니다.
- 완전 비동기 파이프라인 (Fully Asynchronous Pipeline): 데이터 생성(롤아웃), 학습, 데이터 전송, 가중치 동기화의 네 가지 단계를 완전히 분리합니다. 학습 과정이 지연되더라도 로봇이 데이터를 수집하는 행위가 멈추지 않도록 하여 물리적 상호작용의 시간 제약을 극복합니다.
- 적응형 통신 평면 (Adaptive Communication Plane): 로봇(엣지)과 학습 서버(클라우드) 간의 이기종 네트워크 도메인을 연결하여 대역폭 비대칭성과 교차 도메인 지연 시간(Latency) 문제를 해결하고 안정적인 통신을 제공합니다.
핵심 기법
가장 중요한 방법론은 **완전 비동기 파이프라인(Fully Asynchronous Pipeline)**입니다. 물리적 세계에서 데이터를 수집하는 속도는 가속할 수 없으므로, 학습이 끝날 때까지 로봇을 멈춰두는 동기화 방식은 비효율적입니다. USER는 로봇이 끊김 없이 계속 움직이며 데이터를 전송하게 하고, 별도의 워커가 이를 실시간으로 처리하도록 설계하여 물리적 자원의 활용도를 100%에 가깝게 끌어올립니다.
📊 정량적 결과
주요 성과
- 제공된 논문 요약 본문에는 구체적인 백분율(%) 수치는 명시되어 있지 않으나, 실험 결과 데이터 수집과 학습 처리량(Throughput)을 유의미하게 개선하고, 이기종 다중 로봇 군집에 대한 효율적인 정책 학습을 달성했다고 보고하고 있습니다.
- 시뮬레이션과 실제 벤치마크 환경 모두에서 엣지-클라우드 간의 견고한 통신을 유지하며 높은 학습 성능을 입증했습니다.
🚀 기존 대비 개선점
- 기존 시스템에서는 학습 지연이 발생하면 로봇 실행이 강제로 중단되는(Cascading stalls) 문제가 있었으나, USER는 비동기 설계를 통해 로봇이 중단 없이 연속적으로 작동하도록 했습니다.
- 로봇을 단순한 외부 환경이 아닌 GPU와 같은 일급 하드웨어 자원으로 취급하여, 컴퓨팅 클러스터 내에서 로봇과 가속기를 통합 관리 및 스케줄링할 수 있게 되었습니다.
- 다양한 로봇 플랫폼과 네트워크 환경에서 확장 가능하고 유연한 시스템을 제공합니다.
🎯 활용 분야
- 대규모 물류 창고나 공장에서 서로 다른 종류의 로봇들이 협력하여 실시간으로 작업을 학습하는 이기종 다중 로봇 군집(Heterogeneous multi-robot fleets) 운영
- 대형 비전-언어-행동 모델(VLA: Vision-Language-Action models)을 학습시키기 위해 엣지 장비에서 데이터를 수집하고 클라우드에서 학습하는 분산형 인프라
- 사람이 개입하여 로봇을 제어하거나 교정하는 과정을 포함하는 휴먼 인 더 루프(Human-in-the-loop) 학습
한계 및 주의사항
- 논문은 시스템의 통합성과 확장성에 초점을 맞추고 있으므로, 특정 알고리즘의 수렴 속도나 정확도보다는 시스템 전체의 처리량과 안정성이 핵심 지표입니다.
- 물리적 환경은 여전히 가속화할 수 없기 때문에, 학습 속도의 병목은 여전히 물리적 데이터 수집 단계에 남아 있을 수 있습니다.
10. Towards Agentic Intelligence for Materials Science
arXiv: 2602.00169 | ⬆️ 43 🤖 GLM추천 | 📄 HTML 태그:
agentic-aimaterials-sciencellmautonomous-discoverypipeline-centricsurveyreinforcement-learninghuman-in-the-loop사전 지식: Foundation Language Models (기초 언어 모델), Reinforcement Learning (강화 학습), Instruction Tuning (명령어 튜닝), End-to-end Learning (엔드 투 엔드 학습), Feedback Loop (피드백 루프)

한 줄 요약
이 논문은 재료 과학 분야의 고립된 작업에 최적화된 기존 인공지능 모델의 한계를 넘어, 실험과 시뮬레이션을 계획하고 실행하며 학습하는 능동적이고 목표 지향적인 에이전트 시스템으로의 패러다임 전환을 제안했기에 중요합니다.
💡 핵심 아이디어
기존의 AI가 “각기 다른 부품을 잘 만드는 숙련공”에 불과했다면, 이 논문은 “전체 자동차를 설계하고 직접 운전해서 목적지에 도달하는 총괄 매니저”인 에이전트 시스템(Agentic System)을 제안합니다. 단순히 성능을 예측하거나 데이터를 추출하는 수동적인 역할에서 벗어나, 데이터 수집부터 학습, 실험, 피드백까지 순환하며 스스로 새로운 소재를 발견하는 시스템을 엔드 투 엔드(End-to-end)로 설계해야 한다는 것이 핵심입니다.
문제 정의
현재 재료 과학 AI는 특정 벤치마크에서 높은 점수를 기록하지만, 실제 새로운 소재 발견이라는 “궁극적인 목표”를 달성하는 데는 실패하고 있습니다. 이는 합성 가능성, 안전성, 실험적 검증 등이 포함된 전체 발견 과정(Discovery Loop)이 고려되지 않은 채 고립된 과제(Reactive Tasks)에만 집중했기 때문입니다.
🔬 방법론 상세
- 파이프라인 중심적 관점(Pipeline-centric view): 말뭉치 큐레이션 및 사전 학습, 도메인 적응 및 명령어 튜닝(Instruction Tuning), 시뮬레이션 및 실험 플랫폼과 연동되는 목표 조건부 에이전트까지 하나의 연속된 프로세스로 정의하고 최적화합니다.
- 피드백 루프 라우팅: 개방형 실험(Open-ended experiments)에서 나온 피드백 신호를 에이전트 LLM, 재료 과학 튜닝 LLM, 사전 학습 LLM으로 다시 보내 각 모듈을 지속적으로 업데이트하는 메커니즘을 적용합니다.
- 목표 조건부 에이전트(Goal-conditioned agents): LLM이 수동적으로 정보를 처리하는 것을 넘어, 능동적으로 인지하고 계획하여 발견 루프(Discovery Loop)를 닫는 역할을 수행하도록 설계합니다.
핵심 기법
이 논문의 핵심은 모델의 성능을 높이는 기술적 알고리즘 자체보다는, 평가 방식의 전환에 가깝습니다. “정답을 맞히는 벤치마크”가 아니라 “실제로 유용한 소재를 발견했는가”라는 결과 중심의 엔드 투 엔드 시스템을 구축하는 것이 핵심이며, 이를 위해 실험 결과가 다시 학습 과정으로 흘러 들어가는 피드백 구조를 설계하는 것이 가장 중요합니다.
📊 정량적 결과
주요 성과
- 이 논문은 서베이(Survey) 논문이므로 특정 모델의 성능 향상 수치를 제시하지 않습니다.
- 대신 기존의 고립된 모델들이 정적 벤치마크(Static benchmarks)에서는 높은 성능을 보이지만, 실제 발견 결과에는 기여하지 못함을 짚어냈습니다.
- 최근 10년간 AI가 수동적인 도구에서 능동적인 발견 참여자로 진화했음을 분류학(Taxonomy)적으로 체계화했습니다.
🚀 기존 대비 개선점
- 엔드 투 엔드 최적화: 개별 작업의 성능이 아닌 전체 발견 프로세스의 결과를 최적화합니다.
- 능동적 학습: 실험 환경과 상호작용하며 피드백을 통해 스스로 개선하는 에이전트 시스템을 구현합니다.
- 현실 적용성 고려: 단순 예측을 넘어 합성 가능성과 안전 제약 조건 등 현실적인 요소를 포함합니다.
🎯 활용 분야
- 자율적인 신소재 발견 플랫폼 구축
- 재료 합성 경로 및 공정 최적화 자동화
- 실험실 자동화 시스템과 연동된 AI 연구원(AI Scientist) 개발
한계 및 주의사항
- 서로 다른 규모와 유형의 데이터, 그리고 다양한 실험 환경을 통합하는 데 따른 복잡성이 존재합니다.
- 개방형 실험 과정에서의 안전성 제약과 현실적인 합성 가능성을 완전히 보장하기 위해서는 추가적인 연구가 필요합니다.
📅 생성일: 2026-02-10 | 🤖 GLM-4.7