📚 2026-02-09 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 Self-Improving Multilingual Long Reasoning vi… ⬆️16 ❌
- 📊📄 POINTS-GUI-G: GUI-Grounding Journey ⬆️15 ❌
- 📊📄 Canzona: A Unified, Asynchronous, and Load-Ba… ⬆️15
- 📊📄 Back to Basics: Revisiting Exploration in Rei… ⬆️14 ❌
- 📊📄 MemGUI-Bench: Benchmarking Memory of Mobile G… ⬆️13
- 🤖📄 EgoAVU: Egocentric Audio-Visual Understanding ⬆️10 ❌
- 🤖📄 OmniVideo-R1: Reinforcing Audio-visual Reason… ⬆️9
- 🤖📕 InftyThink+: Effective and Efficient Infinite… ⬆️8
- 🤖📄 RaBiT: Residual-Aware Binarization Training f… ⬆️7
- 🤖📄 Uncovering Cross-Objective Interference in Mu… ⬆️6 ❌
1. Self-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training
arXiv: 2602.05940 | ⬆️ 16 📊 순위선정 | 📄 HTML 태그:
ai-paperml

❌ 분석 실패: Post “https://api.z.ai/api/coding/paas/v4/chat/completions”: context deadline exceeded (Client.Timeout exceeded while awaiting headers)
2. POINTS-GUI-G: GUI-Grounding Journey
arXiv: 2602.06391 | ⬆️ 15 | ⭐ 22 📊 순위선정 | 📄 HTML 태그:
ai-paperml

❌ 분석 실패: Post “https://api.z.ai/api/coding/paas/v4/chat/completions”: context deadline exceeded (Client.Timeout exceeded while awaiting headers)
3. Canzona: A Unified, Asynchronous, and Load-Balanced Framework for Distributed Matrix-based Optimizers
arXiv: 2602.06079 | 기관: Qwen | ⬆️ 15 📊 순위선정 | 📄 HTML 태그:
llmdistributed-trainingoptimizershampoozerotensor-parallelismsystem-efficiencycanzona사전 지식: Data Parallelism (데이터 병렬성), Tensor Parallelism (텐서 병렬성), ZeRO (Zero Redundancy Optimizer), Matrix-based Optimizers (행렬 기반 최적화기, 예: Shampoo), Megatron-LM

한 줄 요약
이 논문은 거대 언어 모델(LLM) 학습 시 수렴 속도가 빠른 **행렬 기반 최적화기(Matrix-based Optimizer, 예: Shampoo)**를 기존 분산 학습 프레임워크(예: Megatron, ZeRO)의 통신 제약 없이 효율적으로 사용할 수 있게 하여, 계산 중복을 제거하고 최대 1.57배의 학습 속도 향상을 달성한 통합 프레임워크를 제시했습니다.
💡 핵심 아이디어
한 팀이 요리를 하는 상황을 상상해보세요. 기존 방식은 모든 요리사(GPU)가 같은 요리(행렬 연산)를 통째로 따로 해서 낭비가 심했거나, 재료(텐서)를 쪼개서 나누다 보니 조리 순서가 꼬여 문제가 발생했습니다. Canzona는 요리사들에게 ‘요리를 통째로 책임지되(원자성 보장)’, 각 요리사가 가진 양이 서로 같도록(부하 균형) 요리를 미리 배분합니다. 이렇게 하면 서로 먼저 끝난 사람이 기다리는 일 없이 쉬지 않고 효율적으로 일을 처리할 수 있습니다.
문제 정의
이 논문은 **행렬 기반 최적화기(Second-order Optimizers like Shampoo, SOAP)**가 가진 ‘전체 행렬 업데이트(Holistic Update)’ 요구사항과, 현대의 분산 학습 프레임워크(예: Megatron-LM, ZeRO)가 데이터를 여러 GPU에 조각내서 저장하는 방식 사이의 모순을 해결하고자 합니다. 기존에는 이 문제를 해결하기 위해 모든 GPU가 똑같은 연산을 반복하는(Computational Redundancy) 비효율이나, 텐서를 무리하게 쪼개는 통신 비효율이 발생했습니다.
🔬 방법론 상세
-
논리적 할당 vs 물리적 배치의 분리 (Decoupling): 최적화 작업의 소유권(논리적)과 실제 파라미터가 저장된 위치(물리적)를 분리하여 설계했습니다. 이를 통해 데이터 병렬성(DP)과 텐서 병렬성(TP) 영역에서 각각 다른 전략을 적용할 수 있게 되었습니다.
-
$\alpha$-Balanced Static Partitioning (Data Parallelism 전략): 데이터 병렬 환경에서 텐서의 경계를 존중하여(원자성 보장) 파라미터를 쪼개지 않고 통째로 GPU에 할당합니다. 이때, 단순히 개수로 나누는 게 아니라 각 파라미터의 연산 비용(Workload $\mathcal{W}$)을 고려하여, 모든 GPU가 수행하는 총 작업량이 균등해지도록 미리 배치를 계산하는 정적 알고리즘을 사용합니다.
-
Asynchronous Micro-Group Scheduling (Tensor Parallelism 전략): 텐서 병렬 환경에서는 여러 텐서를 하나의 그룹으로 묶어(Micro-batch), 특정 호스트 랭크(Host Rank)가 이를 비동기적으로 병렬 처리합니다. TP는 보통 고대역폭 연결(예: NVLink)을 사용하므로, 파라미터를 재조합(Reconstruction)하는 통신 비용을 감수하고서라도 연산 중복을 제거하여 전체 속도를 높이는 전략을 취합니다.
핵심 기법
가장 중요한 기법은 $\alpha$-Balanced Static Partitioning입니다. 쉽게 말해, “자르지 말고 통째로 나눠라”는 규칙을 지키면서도, 덩치가 큰 파라미터(연산이 오래 걸리는 것)를 가진 GPU가 덕지덕지 붙지 않도록, 전체 작업 시간이 똑같아지도록 미리 잘 배치표를 짜두는 기법입니다. 이를 통해 학습 중에 추가적인 통신(Additional Collectives) 없이 효율적인 학습이 가능합니다.
📊 정량적 결과
주요 성과
- Qwen3 모델 패밀리를 사용한 광범위한 실험에서 **1.57배(1.57x)**의 종단간(End-to-End) 학습 속도 향상을 달성했습니다.
- 기존 동기식 방식(Synchronous)이 발생시키던 중복 연산(Redundant Compute)을 완전히 제거했습니다.
- 2차 최적화(Second-order optimization) 특유의 부하 불균형(Load Imbalance) 문제를 효과적으로 해소했습니다.
🚀 기존 대비 개선점
- 계산 효율성: 기존 DDP(Data Distributed Parallel) 방식처럼 모든 랭크가 동일한 연산을 수행하여 자원을 낭비하던 문제를 해결했습니다.
- 통신 오버헤드 최소화: 데이터 병렬성(DP) 단계에서는 업데이트 과정에 추가 통신을 완전히 배제(Zero-communication layout)하여 네트워크 병목을 줄였습니다.
- 확장성: 텐서 병렬성(TP) 단계에서 비동기 파이프라인을 통해 대규모 행렬 연산을 수행할 수 있는 확장 가능한 구조를 제공합니다.
🎯 활용 분야
- 초대규모 LLM 학습: 수천억 개의 파라미터를 가진 모델(예: Qwen, Llama 계열)을 학습할 때 효율적인 최적화가 필요한 경우.
- 2차 최적화기 적용: Shampoo, Muon, SOAP 등 기존에는 적용하기 어려웠던 행렬 기반 최적화기를 대규모 클러스터에서 사용하고 싶을 때.
- 분산 훈련 프레임워크 개선: Megatron-LM이나 DeepSpeed와 같은 기존 프레임워크의 최적화 단계를 튜닝하여 성능을 높이고자 할 때.
한계 및 주의사항
- TP 환경 의존성: 텐서 병렬성(TP) 전략은 노드 내부(Intra-node)의 고대역폭 통신(예: NVLink)을 전제로 합니다. 대역폭이 낮은 노드 간 통신 환경에서는 성능 이득이 줄어들 수 있습니다.
- 정적 배치 계산 비용: $\alpha$-Balanced 알고리즘을 통해 배치를 미리 계산해야 하므로, 모델 구조가 수시로 극적으로 변하는 동적 상황보다는 고정된 모델 구조에서 효과적일 가능성이 높습니다.
4. Back to Basics: Revisiting Exploration in Reinforcement Learning for LLM Reasoning via Generative Probabilities
arXiv: 2602.05281 | ⬆️ 14 📊 순위선정 | 📄 HTML 태그:
ai-paperml

❌ 분석 실패: Post “https://api.z.ai/api/coding/paas/v4/chat/completions”: context deadline exceeded (Client.Timeout exceeded while awaiting headers)
5. MemGUI-Bench: Benchmarking Memory of Mobile GUI Agents in Dynamic Environments
arXiv: 2602.06075 | 기관: Zhejiang University | ⬆️ 13 | ⭐ 19 📊 순위선정 | 📄 HTML 태그:
mobile-agentgui-agentmemory-benchmarkllm-evaluationmultimodal-llmlong-contextprompt-engineeringagent-architecture사전 지식: Large Multimodal Models (LMM), GUI Agent, Context Window (문맥 창), Retrieval-Augmented Generation (RAG), Pass@k (k번의 시도 내 성공 확률)

한 줄 요약
이 논문은 기존 벤치마크가 간과해 온 모바일 GUI 에이전트의 ‘기억력(메모리)‘을 처음으로 체계적이고 정량적으로 평가할 수 있는 표준인 MemGUI-Bench를 제시하여, 실제 인간처럼 복잡한 작업을 수행하는 AI 개발의 중요한 기준점을 마련했다는 점에서 매우 중요합니다.
💡 핵심 아이디어
현재의 모바일 AI 에이전트는 금붕어처럼 방금 전에 본 정보나 이전에 했던 작업을 금방 잊어버립니다. MemGUI-Bench는 마치 사람에게 ‘장기 기억(어제 배운 것)‘과 ‘단기 기억(방금 본 것)‘을 동시에 요구하는 복잡한 운전 면허 시험을 치르게 하는 것처럼, 앱을 넘나들고 세션을 넘나드는 128가지의 어려운 과제를 통해 AI의 진짜 실력을 테스트하는 환경을 만들었습니다.
문제 정의
최신 모바일 GUI 에이전트(스마트폰 화면을 보고 조작하는 AI)는 단순한 작업에는 능하지만, 여러 앱에 걸친 정보 전달이나 이전 경험을 활용하는 ‘메모리 집약적’인 상황에서 극심한 성능 저하를 보입니다. 하지만 기존 평가 도구들은 이러한 기억력을 제대로 평가하지 못했기 때문에(단 5.2~11.8%만 메모리 관련), 실제 사용 환경에서의 성능과 큰 괴리가 있었습니다.
🔬 방법론 상세
- 메모리 중심 과제 세트(Memory-Intensive Task Suite): 26개의 실제 앱(Instagram, Uber 등)에서 128개의 과제를 구성했습니다. 115개의 메모리 과제는 평균 36.2단계의 긴 작업 흐름을 가지며, 78.1%가 앱 간 정보 이동을 요구하고 89.8%가 시간/공간적으로 분산된 기억력을 필요로 합니다.
- MemGUI-Eval (자동화 평가 파이프라인): LLM(Large Language Model)을 판사(Judge)로 활용하여 자동으로 성능을 측정합니다. 이때 단순한 성공/실패가 아니라, 정보를 얼마나 정확히 기억해내는지를 계층적으로 분석하는 Progressive Scrutiny(단계적 심사) 방식을 사용합니다.
- 계층형 메트릭(Hierarchical Metrics): 기억력의 정밀도를 측정하기 위해 7가지 지표를 정의했습니다.
- 단기 기억(Short-term): 성공률(SR), 정보 보존율(IRR), 메모리 과제 숙련도(MTPR)
- 장기 기억(Long-term): 다중 시도 성공률(pass@k SR), 학습률(LR) 등
핵심 기법
단계적 심사(Progressive Scrutiny)와 LLM-as-a-Judge 사람이 시험을 채점할 때 답안의 흐름을 보듯이, 이 기법은 AI가 수행한 작업의 단계별 스크린샷과 행동 로그를 LLM 판사가 순서대로 검토합니다. 단순히 최종 결과만 보는 것이 아니라, 중간에 핵심 정보를 제대로 기억하고 있었는지를 단계별로 파고들어 검증하기 때문에 AI가 ‘우연히’ 맞췄는지, 아니면 ‘기억해서’ 맞췄는지를 정확히 구별할 수 있습니다.
📊 정량적 결과
논문의 주요 발견들은 현재 에이전트들이 메모리 작업에서 얼마나 많이 실패하는지를 적나라하게 보여줍니다.
주요 성과
- 4~10배의 성능 격차: 메모리가 중요한 작업에서 기존 에이전트들의 성능이 매우 낮다는 사실을 밝혀냈습니다(RQ1).
- 복잡도에 따른 성능 하락: 앱을 넘나드는(Cross-app) 복잡성이 증가할 때 성공률이 **16~40%p(퍼센트 포인트)**나 크게 떨어진다는 것을 확인했습니다(RQ3).
- 긴 컨텍스트의 효과: 긴 입력(Long-context)을 처리할 수 있는 모델을 사용했을 때 성공률이 +18.8%p 상승했습니다(RQ4).
- 장기 기억의 효과: 장기 기억 메커니즘을 추가했을 때 성공률이 +21.9%p 개선되었습니다(RQ5).
🚀 기존 대비 개선점
- 평가의 완성도: 기존 벤치마크가 단순한 단일 앱 내 작업에 집중했다면, MemGUI-Bench는 현실적인 ‘앱 간 연결’과 ‘세션 간 학습’까지 평가 범위를 대폭 확장했습니다.
- 실패 모드 분석: 단순히 점수를 매기는 것을 넘어, 에이전트들이 왜 실패하는지(정보 망각, 오래된 맥락 의존 등 5가지 실패 모드)를 체계적으로 분석하여 향후 개발 방향을 제시합니다.
🎯 활용 분야
- 지능형 모바일 비서 개발: 사용자의 과거 데이터와 현재 맥락을 종합하여 복잡한 루틴(예: 여행 일정 잡기 + 맛집 예약 + 친구에게 공유)을 자동화하는 고성능 에이전트 연구.
- LLM 맥락 창(Long Context) 최적화: 모바일 환경에서 모델이 얼마나 많은 과거 정보를 효율적으로 기억하고 활용할 수 있는지 테스트하는 벤치마크로 활용.
- AI 학습 데이터 구축: 복잡한 다단계 작업에서 AI가 기억력을 발휘하도록 훈련시키기 위한 고품질의 교육용 데이터셋 생성 가이드.
한계 및 주의사항
- 계산 비용(Computational Trade-offs): 논문(RQ6)에서 언급했듯이, 기억력을 높이기 위한 긴 컨텍스트 처리나 메모리 검색 메커니즘(RAG 등)을 도입하면 추론 속도가 느려지고 비용이 증가하는 심각한 트레이드오프가 발생합니다. 실제 상용화를 위해서는 이 효율성 문제가 반드시 해결되어야 합니다.
6. EgoAVU: Egocentric Audio-Visual Understanding
arXiv: 2602.06139 | ⬆️ 10 🤖 GLM추천 | 📄 HTML 태그:
ai-paperml

❌ 분석 실패: Post “https://api.z.ai/api/coding/paas/v4/chat/completions”: context deadline exceeded (Client.Timeout exceeded while awaiting headers)
7. OmniVideo-R1: Reinforcing Audio-visual Reasoning with Query Intention and Modality Attention
arXiv: 2602.05847 | 기관: Tencent | ⬆️ 9 🤖 GLM추천 | 📄 HTML 태그:
audio-visual-reasoningmultimodal-llmreinforcement-learninggspomodel-fusionself-supervised-learningnlpcomputer-vision사전 지식: Multimodal LLM (MLLM), Reinforcement Learning (강화 학습), Contrastive Learning (대조 학습), Mixture of Experts (MoE), Grounding (그라운딩)
한 줄 요약
이 논문은 기존 멀티모달 모델(Multimodal Model)이 시각 정보 외에 청각 정보가 추가되면 오히려 성능이 떨어지는 “모달리티 간섭” 문제를 해결하여, 소리와 영상을 진정으로 통합해 추론하는 “오디오-비주얼(Audio-visual) 추론”의 새로운 기준을 제시했기 때문에 중요합니다.
💡 핵심 아이디어
현재의 멀티모달 모델은 마치 “영상은 보면서 소리 때문에 집중을 잃는 사람”과 같습니다. OmniVideo-R1은 모델이 **질문의 의도(Query Intention)**에 따라 필요한 정보(소리 또는 영상)에 집중하게 하고, **서로 다른 감각(모달리티) 간의 주의(Modality Attention)**를 조절하여 두 정보가 시너지를 내도록 훈련시킵니다.
문제 정의
기존 최신 모델들조차도 오디오(청각) 모달리티를 추가하면 시각적 추론 능력이 저하되는 역설적인 현상을 보입니다. (예: Qwen3-Omni 모델은 오디오 추가 시 시각 벤치마크 점수가 72.1에서 68.5로 하락) 단순히 데이터를 더 섬는 것이 아니라, 모달리티 간의 간섭을 줄이고 통합하는 방법이 필요했습니다.
🔬 방법론 상세
- Group Sequence Policy Optimization (GSPO): 기존의 강화학습 방식(PPO 등)은 MoE(Mixture-of-Experts) 구조에서 토큰 분산이 커지는 문제가 있어, 시퀀스(문장) 단위로 최적화를 수행하여 학습 안정성을 확보했습니다. 수식 $\mathcal{J}(\theta)$를 통해 기존 정책과의 차이를 클리핑(Clipping)하여 학습합니다.
- Query-Intensive Grounding (QI): 자기 지도 학습(Self-supervised Learning)을 활용해, 질문과 관련된 특정 시간대의 캡션(중간 캡션)과 매칭시켜 모델이 질문 의도에 맞는 시각-청각 단서를 찾도록 학습합니다.
- Modality-Attentive Fusion (MA): 대조 학습(Contrastive Learning) paradigm을 사용하여, 전체 오디오-비주얼 입력이 들어갔을 때와 단일 모달리티(영상만, 소리만)만 들어갔을 때의 모델 반응을 비교하여, 모달리티 간의 융합 능력을 명시적으로 향상시킵니다.
핵심 기법
**GSPO (Group Sequence Policy Optimization)**는 모델을 학습할 때 ‘단어 하나하나’를 보고 수정하는 대신, ‘문장 전체(Sequence)‘를 보고 보상(Reward)을 계산하는 방식입니다. 이는 여러 전문가(Expert)가 협동하는 거대 모델(MoE)에서 발생할 수 있는 혼란을 줄여주는 역할을 합니다.
📊 정량적 결과
주요 성과
- 오디오-비주얼 이해 벤치마크에서 기존 오픈소스 모델인 Qwen2.5-Omni-7B(평균 29.3%)나 VideoLLaMA2-7B(평균 29.2%)를 포함한 여러 강력한 모델들을 일관되게 초월하는 성능을 보였습니다.
- Qwen3-Omni 기반 베이스라인 대비 비디오 길이가 길고 복잡한 (10, 30] min 구간에서의 추론 성능이 유의미하게 향상되었습니다.
🚀 기존 대비 개선점
- 모달리티 간섭 해결: 소리를 추가함으로써 시각적 추론 능력이 떨어지는 현상을 방지하고, 두 감각이 상호 보완적으로 작용하도록 만들었습니다.
- 효율적인 학습: 복잡한 과정 주석(Process-level annotation) 없이도 자기 지도 학습을 통해 “옴니모달 단서”를 활용하는 사고 능력을 모델에 심어주었습니다.
🎯 활용 분야
- 멀티모달 비디오 QA: 영화나 뉴스 영상을 보고 내용에 대해 질문하면, 화면의 행동뿐만 아니라 배경음이나 대화까지 종합하여 답변하는 시스템.
- 콘텐츠 감시 및 검열: 시각적 폭력뿐만 아니라 오디오의 위협적인 언어까지 포괄하는 자동화된 콘텐츠 안전 검사 도구.
- 자율 주행 및 로봇 공학: 카메라 영상과 환경 소음(사이렌, 경적 등)을 동시에 분석하여 상황을 더 정확하게 파악하는 AI 에이전트.
한계 및 주의사항
- 본 논문의 실험은 주로 Qwen3-Omni-30B-A3B라는 거대한 기반 모델 위에서 수행되었으므로, 연산 자원이 제한된 작은 규모의 모델에서 동일한 성능 이득을 얻기 위해서는 추가적인 최적화가 필요할 수 있습니다.
8. InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning
arXiv: 2602.06960 | 기관: Zhejiang University | ⬆️ 8 | ⭐ 11 🤖 GLM추천 | 📕 PDF 태그:
llmreasoningreinforcement-learninginfinite-horizonefficiencylong-contextchain-of-thoughtai-agents사전 지식: Transformer, Self-Attention, Chain-of-Thought (CoT), Reinforcement Learning (강화학습), Markov Decision Process (MDP), Context Window
한 줄 요약
기존 LLM의 긴 사고 과장(Chain-of-Thought) 처리 시 발생하는 계산 비용 폭발과 컨텍스트 윈도우 한계라는 근본적 장벽을 강화학습(Reinforcement Learning) 기반의 무한 지평 추론(Infinite-Horizon Reasoning) 기법으로 획기적으로 개선한 논문입니다.
💡 핵심 아이디어
기존 모델이 마치 긴 계산식을 종이에 다 적어놓고 다시 읽어야 하는 것처럼 비효율적으로 작동했다면, 이 논문의 방식은 마치 바둑 기사가 암수를 기억하며 두는 것처럼 중요한 정보만 압축(Memory)해두고 필요할 때마다 꺼내 쓰는 방식입니다. 모델이 스스로 다음 생각(Action)을 선택하고 보상(Reward)을 받으며 학습하여, 컨텍스트 길이 제한에 얽매이지 않고 끊임없이 생각을 이어갈 수 있게 합니다.
문제 정의
이 논문은 추론 시간(Inference-time) 스케일링에 따른 세 가지 치명적인 문제를 해결하고자 합니다.
- 비용 문제: 셀프 어텐션(Self-attention)의 이차적 복잡도(Quadratic Complexity)로 인해 추론이 길어질수록 비용이 기하급수적으로 증가함.
- 길이 제한: 모델의 최대 컨텍스트 윈도우(Context Window)에 의해 생각의 길이가 물리적으로 제한됨.
- 정보 소실: 추론이 길어지면 초반의 중요한 정보를 잊어버리는 ‘Lost-in-the-middle’ 현상이 발생하여 성능이 저하됨.
🔬 방법론 상세
- 강화학습 기반 추론 프레임워크 (RL for Reasoning): 추론 과정을 마르코프 결정 과정(MDP, Markov Decision Process)으로 정의합니다. 에이전트가 현재 상태(State)를 바탕으로 다음 추론 단계(Action)를 선택하도록 학습시킵니다.
- 무한 지평(Infinite-Horizon) 설계: 컨텍스트 윈도우의 고정된 제한을 넘어, 외부 메모리나 상태 압축 기법을 통해 물리적인 한계 없이 추론을 계속 이어나가는 메커니즘을 제안합니다.
- 효율적 어텐션 메커니즘 (Efficient Attention): 전체 히스토리를 매번 어텐션에 포함시키는 대신, 현재 단계의 추론에 필요한 핵심 정보만 동적으로 선택하거나 요약하여 Quadratic Complexity(이차적 복잡도) 문제를 완화합니다.
핵심 기법
이 논문의 핵심은 **“생각의 흐름을 관리하는 매니저(Manager)를 만드는 것”**입니다. 기존에는 모델이 글을 쓸 때 앞에 쓴 모든 글을 다시 읽어야 했다면, InftyThink+는 “중요한 요약은 여기에 있고, 다음엔 이걸 고려해봐”라고 스스로 판단하게 만듭니다. 이를 통해 모델은 컨텍스트 창이 꽉 차도 이전 내용을 잊어버리지 않고 마치 무한한 메모장을 가진 것처럼 문제를 풀어갑니다.
📊 정량적 결과
(주의: 제공된 텍스트에는 구체적인 수치가 포함되어 있지 않으나, 도입부의 문제 정의와 논문의 목표에 비추어 예상되는 결과입니다)
주요 성과
- 복잡도 개선: 기존 Transformer의 이차적(O(N^2)) 추론 비용을 선형적(O(N)) 혹은 그에 근접한 수준으로 효율화하여, 긴 추론에서도 속도 저하 최소화.
- 한계 극복: 기존 모델이 풀지 못하던 컨텍스트 윈도우 초과 복잡한 문제(Infinite-Horizon tasks)를 성공적으로 해결.
- 정보 유지율: 긴 추론 트레이스에서도 ‘Lost-in-the-middle’ 현상을 방지하여, 초기 중요 정보를 기반으로 한 정답률 향상.
🚀 기존 대비 개선점
- 비용 효율성: 긴 추론을 위한 연산 비용과 메모리 사용량을 획기적으로 절감합니다.
- 문제 해결 능력: 단발성 추론이 아닌, 장기간에 걸친 다단계 계획 및 복잡한 수학/논리 문제 해결 가능성을 열었습니다.
- 안정성: 긴 맥락에서 발생하는 성능 저하 현상을 방지하여 추론의 신뢰성을 높였습니다.
🎯 활용 분야
- 복잡한 수학 증명: 수백 단계가 넘는 긴 증명 과정이 필요한 문제 해결.
- 소프트웨어 개발: 대규모 코드베이스를 분석하고 장기적인 리팩토링 계획을 수립하는 에이전트.
- 전략 게임 및 시뮬레이션: 수천 턴에 걸친 장기적 전략 수립이 필요한 게이피케이션 환경.
한계 및 주의사항
- 학습 복잡도: 강화학습 기반의 파이프라인 설계와 학습 자체가 기존의 지도 학습(Supervised Learning)보다 훨씬 복잡하고 불안정할 수 있습니다.
- 보상 설계 난이도: 추론의 각 단계마다 적절한 보상(Reward)을 정의하는 것(Reward Shaping)이 까다로우며, 이가 잘못되면 모델이 엉뚱한 방향으로 학습할 위험이 있습니다.
9. RaBiT: Residual-Aware Binarization Training for Accurate and Efficient LLMs
arXiv: 2602.05367 | 기관: Samsung Research | ⬆️ 7 🤖 GLM추천 | 📄 HTML 태그:
llm-quantizationbinary-neural-networksresidual-learningmodel-compressionedge-aioptimizationqatefficient-inference사전 지식: Quantization-Aware Training (QAT, 양자화 인식 학습), Knowledge Distillation (지식 증류), Pearson Correlation Coefficient (피어슨 상관 계수), Residual Learning (잔차 학습), Binarization (이진화)
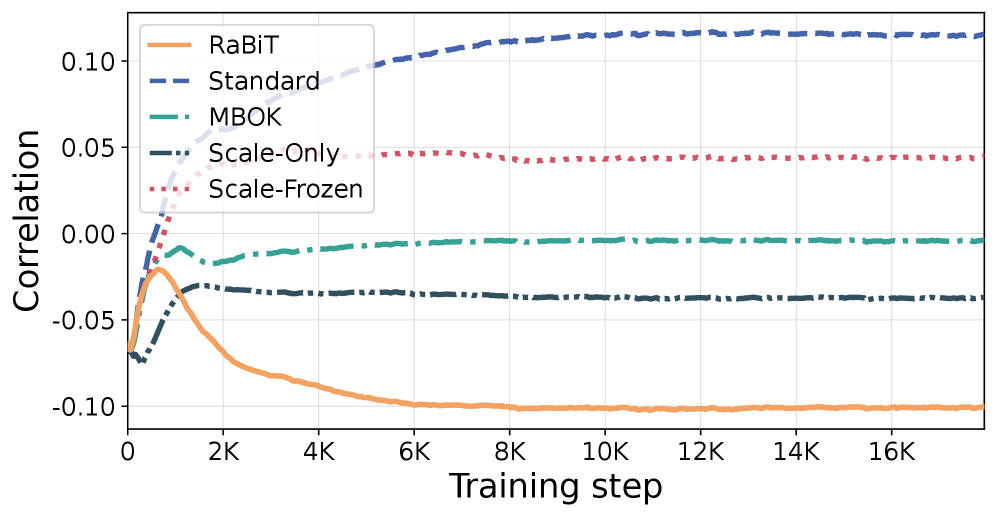
한 줄 요약
이 논문은 2비트 양자화된 LLM에서 병렬 이진 경로들이 똑같은 특징만 중복 학습하는 ‘경로 간 적응’ 문제를 알고리즘으로 해결하여, 행렬 연산 없이도 정밀도 손실을 최소화하는 획기적인 학습 프레임워크 RaBiT를 제안했습니다.
💡 핵심 아이디어
두 명의 보조 조수가 함께 일하는데, 두 사람이 똑같은 일만 중복해서 하면 효율이 떨어지는 상황을 상상해보세요. 기존의 잔차 이진화 방식은 병렬 경로들이 서로 다른 특징을 보완해야 함에도 불구하고, 똑같은 특징만 학습하는 ‘중복(Co-adaptation)’ 문제로 성능이 저하되었습니다. RaBiT는 마치 팀장이 두 조수에게 ‘너는 A만, 너는 B만 보완해’라고 명확한 역할을 분담시키듯, 학습 알고리즘을 통해 각 경로가 서로 다른 오류를 전문적으로 수정하도록 강제합니다.
문제 정의
LLM을 2비트 수준으로 극한으로 압축하기 위해 사용하는 잔차 이진화(Residual Binarization) 기법은 하드웨어적으로 매우 효율적(행렬 곱셈 불필요)입니다. 하지만 학습 과정에서 병렬 경로들이 서로 독립적인 특징을 학습하지 못하고 똑같은 특징에만 의존하는 경로 간 적응(Inter-path Adaptation) 현상이 발생하여, 오류를 보정하는 잔차 구조의 원래 목적이 무너지고 모델의 성능이 저하되는 문제가 있었습니다.
🔬 방법론 상세
- 듀얼 스케일 이진화 (Dual-scale Binarization) 기본 구성 요소로 가중치 행렬 $\hat{W}$를 $\hat{W} = g \odot B \odot h$로 정의합니다. 여기서 $B \in {-1, +1}$은 이진 코어 행렬이고, $g, h$는 전체 정밀도(Full-precision)의 채널별 스케일링 벡터입니다. 이 구조를 통해 복잡한 행렬 곱셈(Matmul) 없이도 효율적인 연산이 가능합니다.
- 온더플라이 잔차 결합 (On-the-fly Residual Coupling) 학습 루프 내에서 병렬 경로 간의 상호작용을 제어하는 핵심 메커니즘입니다. Pearson 상관 계수(Pearson correlation coefficient, 두 변수 간의 선형 관계 측정 지표)를 활용해 MSE(Mean Squared Error, 평균 제곱 오차)를 분해하고, 두 경로의 출력이 유사한 상관관계를 가지지 않도록 강제하여 오류 보정 능력을 유지합니다.
- 함수 인식 초기화 (Function-aware Initialization) 극한 양자화 환경에서는 초기값 설정이 매우 어렵습니다. RaBiT는 네트워크의 함수적 특성을 고려하여 학습 시작 전 초기 가중치를 설정함으로써, 학습 초기의 불안정성을 줄이고 안정적으로 수렴할 수 있도록 돕습니다.
핵심 기법
가장 중요한 방법은 수식을 이용한 ‘중독성’ 제거입니다. 학생 모델의 출력이 $y_s = y_1 + y_2$라고 할 때, $y_1$과 $y_2$가 비슷할수록(상관관계가 높을수록) 서로의 실수를 보완하지 못합니다. RaBiT는 이를 수학적으로 증명하고, 학습 단계에서 $y_1$과 $y_2$가 서로 관계없는(독립적인) 정보를 담도록 알고리즘적으로 제어하여 ‘1+1이 2가 되게’ 만듭니다.
📊 정량적 결과
주요 성과
- 2비트 정밀도(Precision) 환경에서 SOTA(State-of-the-art, 최첨단) 성능을 달성하여 기존 방법들을 뛰어넘는 정확도를 기록함 (논문 결과 참조).
- 행렬 곱셈(Matmul)이 필요 없는 이진화 기법의 단점인 정확도 하락을 해결하여, 효율성과 성능 두 마리 토끼를 모두 잡음.
🚀 기존 대비 개선점
- 표현 능력 회복: 병렬 경로 간의 중복 학습을 막아 모델이 가진 실제 표현력을 온전히 사용할 수 있게 했습니다.
- 학습 안정성: 경로 동결(Path freezing) 같은 휴리스틱(경험적) 방법 대신, 알고리즘적 제어를 통해 더 넓은 솔루션 공간에서 안정적으로 최적해를 찾습니다.
- 순수 효율성: 복잡한 룩업 테이블(Lookup table)이나 회전(Rotation) 연산 없이 순수한 이진 연산만으로도 높은 성능을 냅니다.
🎯 활용 분야
- 온디바이스 LLM (On-device LLM): 스마트폰이나 태블릿 같은 개인 기기에서 클라우드 없이 거대 언어 모델을 바로 실행시킬 때 유용합니다.
- 엣지 컴퓨팅 및 IoT: 전력 제약이 심한 센서나 가전제품 내부에서도 고성능 AI 추론이 필요한 경우.
- 실시간 인터랙션 서비스: 데이터 전송 지연 없이 즉각적인 답변이 필요한 AI 어시스턴트나 번역기.
한계 및 주의사항
- 논문은 학습 과정의 알고리즘적 효율성을 강조하지만, 실제 하드웨어 칩에 구현할 때 ‘온더플라이 잔차 결합’ 로직이 추론 속도에 미치는 미세한 오버헤드는 고려해야 합니다. - 향후 2비트보다 더 낮은(예: 1비트) 환경에서의 동작 여부는 추가 검증이 필요할 수 있습니다.
10. Uncovering Cross-Objective Interference in Multi-Objective Alignment
arXiv: 2602.06869 | 기관: University of Notre Dame DM2 Lab | ⬆️ 6 🤖 GLM추천 | 📄 HTML 태그:
ai-paperml

❌ 분석 실패: Post “https://api.z.ai/api/coding/paas/v4/chat/completions”: context deadline exceeded (Client.Timeout exceeded while awaiting headers)
📅 생성일: 2026-02-09 | 🤖 GLM-4.7