📚 2026-02-04 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 CodeOCR: On the Effectiveness of Vision Langu… ⬆️81
- 📊📄 AOrchestra: Automating Sub-Agent Creation for… ⬆️63
- 📊📄 No Global Plan in Chain-of-Thought: Uncover t… ⬆️57
- 📊📕 MARS: Modular Agent with Reflective Search fo… ⬆️47
- 📊📄 3D-Aware Implicit Motion Control for View-Ada… ⬆️43
- 🤖📄 daVinci-Agency: Unlocking Long-Horizon Agency… ⬆️43
- 🤖📄 Token Sparse Attention: Efficient Long-Contex… ⬆️9
- 🤖📄 Decouple Searching from Training: Scaling Dat… ⬆️8
- 🤖📄 Privasis: Synthesizing the Largest “Public” P… ⬆️1
- 🤖📄 MemoryLLM: Plug-n-Play Interpretable Feed-For… ⬆️1
1. CodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
arXiv: 2602.01785 | 기관: Shanghai Jiao Tong University | ⬆️ 81 📊 순위선정 | 📄 HTML 태그:
code-ocrmultimodal-llmcode-understandingvisual-representationefficiencysoftware-engineeringcompression사전 지식: Large Language Models (LLM), Multimodal Learning (멀티모달 학습), Computer Vision (컴퓨터 비전), Tokenization (토큰화), Context Window (문맥 창)

한 줄 요약
소프트웨어 규모가 커짐에 따라 텍스트 기반 LLM의 계산 비용이 급증하는 문제를 해결하기 위해, 소스 코드를 이미지로 변환하여 처리하는 새로운 패러다임을 제안하고 이것이 비용 효율적이면서도 성능을 유지하거나 향상시킬 수 있음을 입증했습니다.
💡 핵심 아이디어
소스 코드를 텍스트(문자열)로 읽는 것은 책을 한 글자씩 일일이 읽는 것과 같아서 길어지면 처리 속도가 느려지지만, 코드를 이미지(그림)로 바꾸어 읽는 것은 지도를 한눈에 보는 것과 같습니다. 이미지는 해상도(Resolution, 이미지의 세밀함)를 조절해 쉽게 압축할 수 있어, 모델이 처리해야 할 정보 양을 획기적으로 줄이면서도 코드의 의미(구조, 로직)를 파악하는 데 유리합니다.
문제 정의
현재 LLM들은 소스 코드를 토큰(Token, 텍스트의 최소 단위)의 선형적인 시퀀스로 처리합니다. 소프트웨어 시스템이 거대해짐에 따라 코드의 길이가 길어지고, 이에 따라 문맥 길이(Context Length, 모델이 한 번에 처리할 수 있는 입력의 양)가 선형적으로 증가하여 계산 비용이나 지연 시간이 크게 늘어나는 효율성 병목 문제가 발생했습니다.
🔬 방법론 상세
- 코드 시각화 (Code Visualization): 소스 코드 텍스트를 구문 강조(Syntax Highlighting) 등이 적용된 이미지로 렌더링하여 모델에 입력합니다.
- 시각적 압축 (Visual Compression): 이미지 모달리티(Modality, 데이터의 형태)의 특성을 이용해 단순히 해상도를 낮추는 방식으로 입력 데이터를 압축합니다. 텍스트 압축과 달리 의미적 손실을 최소화하면서 토큰 수를 줄이는 것이 핵심입니다.
- 멀티모달 LLM 평가: GPT-5, Gemini-3, Qwen-3-VL 같은 최신 MLLM을 사용하여 요약(Summarization), 완성(Completion), 복제 감지(Clone Detection), 질의응답(QA) 등 4가지 대표적인 작업에서 텍스트 입력과 이미지 입력의 성능을 비교 분석했습니다.
핵심 기법
이 논문의 핵심은 **‘이미지 압축(Resolution Scaling)‘**입니다. 텍스트는 단어 하나만 빼도 의미가 달라질 수 있어 자르기 어렵지만, 코드 이미지는 해상도를 조금 낮추더라도(약간 흐릿하게 하더라도) 전체적인 코드의 구조와 들여쓰기 등을 인지하는 데 큰 지장이 없습니다. 이를 통해 원래 토큰 수의 25% 이하로 줄이면서도 성능을 유지하는 “시각적 효율성”을 극대화했습니다.
📊 정량적 결과
주요 성과
- 토큰 비용 절감: 이미지 압축을 통해 원래 필요한 토큰 수의 25% 이하만 사용하면서도 텍스트 기반 모델과 동등하거나 더 우수한 성능을 기록함.
- 구체적 성능 수치 (Qwen-3-VL 모델 기준): - Code Clone Detection (코드 복제 감지): 텍스트 입력(ACC 67.2%) 대비 이미지 입력(ACC 84.0%)이 월등히 높은 정확도를 보임. - Code Summarization (코드 요약): 텍스트 입력(56.6%)과 이미지 입력(56.4%)이 거의 동일한 성능을 보이며 이미지 처리의 가능성을 입증함.
🚀 기존 대비 개선점
- 비용 효율성 극대화: API 호출 비용이 토큰 수에 비례하는데, 이미지화를 통해 토큰 수를 획기적으로 줄여 비용을 절감할 수 있습니다.
- 시각적 단서 활용: 단순 텍스트가 아닌 구문 강조(Syntax Highlighting, 코드의 색상 구분), 굵은 폰트(Bold Rendering) 등의 시각적 정보가 모델의 코드 이해력을 높이는 데 기여합니다.
- 긴 문맥 처리 능력: 긴 코드를 이미지로 한 번에 보여줌으로써, 텍스트로 잘리는 부분 없이 전체적인 맥락을 파악하기 유리합니다.
🎯 활용 분야
- 비용 최적화형 코드 리뷰 도구: 대규모 레포지토리를 분석할 때 API 비용을 아끼면서 효율적으로 코드 리뷰를 수행하는 보조 도구 개발.
- 통합 개발 환경(IDE) 플러그인: 긴 코드 파일을 스니펫 이미지로 요약하여 개발자에게 빠른 코드 이해를 제공하는 기능.
- 코드 교육 및 문서화: 복잡한 코드 구조를 시각적으로 설명하거나 다른 언어로의 코드 번역 보조 등.
한계 및 주의사항
- 정보 손실 위험: 과도하게 이미지를 압축(해상도를 너무 낮춤)할 경우, 변수명이 짧거나 세밀한 로직이 있는 부분에서 정보가 손실되어 성능이 저하될 수 있습니다. (RQ5 분석 결과)
- 세부적인 텍스트 기반 작업: 오타 수정이나 매우 구체적인 텍스트 생성이 필요한 작업에서는 여전히 텍스트 기반 처리가 더 유리할 수 있습니다.
2. AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
arXiv: 2602.03786 | ⬆️ 63 📊 순위선정 | 📄 HTML 태그:
multi-agentorchestrationllmautomationsub-agentframeworkprompt-engineeringscalability사전 지식: LLM(Large Language Model), Prompt Engineering, Multi-Agent Systems(MAS), Function Calling(Tool Use), Fine-tuning
한 줄 요약
복잡한 다단계 작업에서 기존 멀티 에이전트 시스템의 경직성과 조정 오버헤드(Coordination Overhead) 문제를 해결하기 위해, 통합된 추상화 모델을 통해 필요할 때마다 전문화된 **서브 에이전트(Sub-agent)**를 동적으로 생성하여 성능을 획기적으로 향상시켰기 때문에 중요합니다.
💡 핵심 아이디어
이 논문은 **“건축가와 임시 전문가 팀”**에 비유할 수 있습니다. 마치 건축가(Orchestrator)가 복잡한 공사를 위해 미리 팀을 꾸리는 것이 아니라, 배관 작업이 필요할 때 배관공을, 전기 작업이 필요할 때 전기기사를 그 자리에서 즉시 고용하고 필요한 도구와 설계도만 전달해서 일을 시킨 후 해고하는 방식입니다. 이를 통해 **불필요한 소통(Noise)**을 줄이고 각 작업에 **최적화된 전문성(Specialization)**을 부여합니다.
문제 정의
기존의 AI 에이전트들은 복잡한 작업을 수행하기 위해 고정된 역할을 가진 멀티 에이전트 시스템을 사용하거나, 하나의 에이전트가 모든 것을 처리하려 했습니다. 이는 (1) 불필요한 정보 공유로 인한 맥락 오염(Context Rot), (2) 유연하지 못한 고정된 역할(Coverage Gaps), (3) 여러 에이전트 간의 조정 비용 증가 등의 문제를 야기하여 긴 호라이즌(Long-horizon)의 복잡한 작업 수행을 어렵게 만들었습니다.
🔬 방법론 상세
-
통합된 에이전트 추상화 (Unified Agent Abstraction) 모든 에이전트를 네 가지 요소의 튜플(Tuple)로 정의합니다. 이는 에이전트를 만들기 위한 ‘조리법’과 같습니다. $$ \text{Agent} = \langle \text{Instruction}, \text{Context}, \text{Tools}, \text{Model} \rangle $$
- Instruction (명령어): 서브 에이전트가 수행해야 할 구체적인 작업 정의
- Context (맥락): 작업 수행에 필요한 최소한의 정보 (필요한 만큼만 제공하여 효율성 증대)
- Tools (도구): 사용 가능한 API나 함수 등 (예: 터미널, 코드 인터프리터)
- Model (모델): 작업에 적합한 LLM 선택 (예: 코딩에는 최신 모델, 요약에는 작은 모델)
-
온디맨드 서브 에이전트 생성 (On-demand Sub-agent Creation) 메인 오케스트레이터(Orchestrator)는 사용자의 목표(Goal)를 보고, 이를 여러 하위 작업(Subtask)으로 나눕니다. 각 하위 작업에 대해 위의 4가지 튜플을 즉석에서 구성하여 전문 실행자(Executor)를 생성하고 작업이 끝나면 자원을 해제합니다.
-
학습 가능한 오케스트레이터 (Learnable Orchestrator) 오케스트레이터는 단순한 규칙 기반 시스템이 아니라, 과거의 성공/실패 트레젝토리(Trajectory, 상태-행위-관찰의 기록)를 통해 지도 학습(Supervised Fine-tuning) 하거나 **컨텍스트 학습(Context Learning)**을 통해 개선됩니다. 즉, 작업을 어떻게 쪼개고 어떤 서브 에이전트를 만들어야 할지 스스로 학습합니다.
핵심 기법
동적 튜플 할당 (Dynamic Tuple Allocation) 이 논문의 핵심은 “에이전트”라는 무거운 개념을 “명령어, 맥락, 도구, 모델”이라는 가벼운 설정의 조합으로 바꾼 것입니다. 마치 소프트웨어의 설정 파일을 바꿔가며 여러 프로그램을 실행하는 것처럼, AI가 상황에 맞춰 설정(튜플)을 짜맞춰 새로는 에이전트를 즉시 생성(Spawn)한다고 생각하면 쉽습니다.
📊 정량적 결과
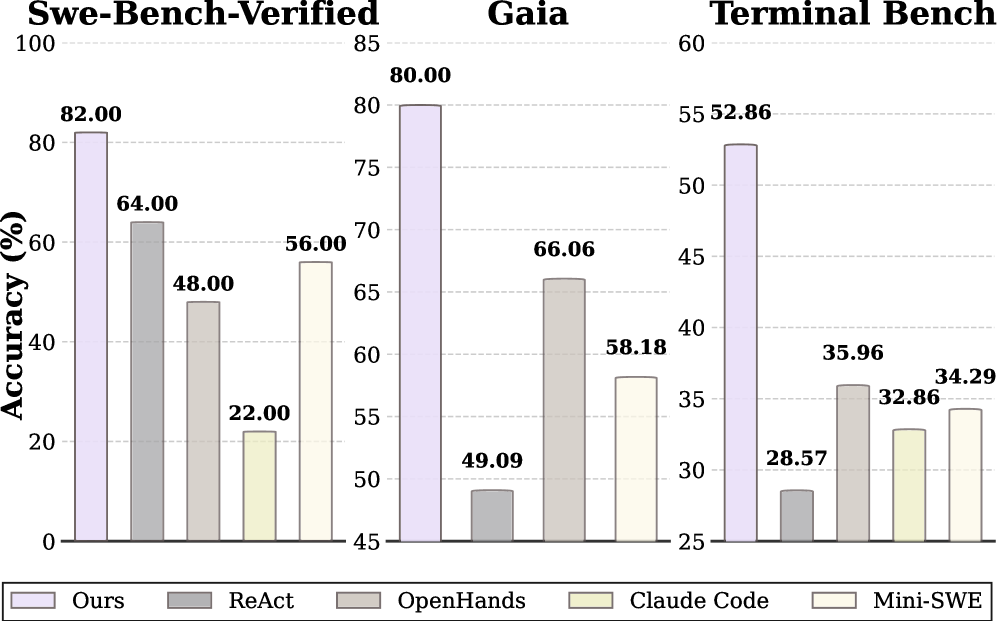
AOrchestra는 복잡한 에이전트 벤치마크인 GAIA, Terminal-Bench 2.0, SWE-Bench-Verified에서 기존 프레임워크(ReAct, OpenHands 등) 대비 월등한 성능을 보였습니다. 특히 Gemini-3-Flash 기반 성능 향상이 두드러집니다.
주요 성과
- SWE-Bench-Verified: Pass@1 82.00% (기존 ReAct 64.00% 대비 +18%p 향상)
- GAIA: Pass@1 80.00% (기존 ReAct 49.09% 대비 +30.91%p 향상)
- 평균 성능 (Avg. Pass@1): 71.62% (기존 최고 성능인 Mini-SWE의 49.49% 대비 압도적 우위)
🚀 기존 대비 개선점
- 유연한 전문성(Flexible Specialization): 미리 정의된 역할에 얽매이지 않고 작업에 딱 맞는 커스텀 에이전트를 즉석에서 만들어냅니다.
- 효율적인 컨텍스트 관리(Efficient Context Routing): 모든 에이전트가 모든 대화를 공유하는 것이 아니라, 필요한 에이전트에게 필요한 맥락만 isolated(격리)되어 전달되어 정보의 혼선(Noise)을 줄입니다.
- 확장 가능성(Scalability): 프레임워크에 종속되지 않는 추상화 덕분에 다양한 LLM이나 도구를 자유롭게 플러그인처럼 끼워 쓸 수 있습니다.
🎯 활용 분야
- 자율 소프트웨어 엔지니어링: 버그 수정, 기능 추가, 리팩토링 등 복잡한 코딩 작업을 단계마다 최적화된 에이전트가 수행하는 시스템 구축
- 복잡한 데이터 분석 및 리포팅: 웹 검색, 코드 실행, 문서 작성 등 서로 다른 도구가 필요한 작업을 자동으로 조율
- DevOps 및 시스템 관리: 터미널 명령어 실행, 로그 분석, 서비스 재시작 등 복잡한 운영 작업 자동화
한계 및 주의사항
- 추론 비용 및 지연 시간: 매 하위 작업마다 새로운 에이전트(및 LLM 호출)를 생성해야 하므로, 단일 모델이 처리할 때보다 API 호출 비용이나 전체 수행 시간(Latency)이 증가할 수 있습니다.
- 오케스트레이터의 의존성: 전체 시스템의 성능은 작업을 얼마나 잘 쪼개고 배치하는지에 달린 오케스트레이터의 능력에 크게 의존합니다.
3. No Global Plan in Chain-of-Thought: Uncover the Latent Planning Horizon of LLMs
arXiv: 2602.02103 | 기관: Tencent | ⬆️ 57 📊 순위선정 | 📄 HTML 태그:
llmchain-of-thoughtinterpretabilitylatent-planninguncertainty-estimationmyopic-horizontele-lensreasoning사전 지식: Chain-of-Thought (사고의 연쇄), Hidden States (은닉 상태), Probing (프로빙, 모델 내부 조사), Perplexity (혼란도), Entropy (엔트로피), Latent Planning (잠재적 계획)

한 줄 요약
이 논문은 LLM(대규모 언어 모델)이 사고 사슬(Chain-of-Thought)을 생성하기 전에 전체적인 답을 미리 계획한다는 기존 믿음을 반박하며, 모델이 실제로는 **‘근시안적(단기적) 계획’**만을 수행함을 밝혀내어 모델의 추론 메커니즘을 근본적으로 이해하고 불확실성을 추정하는 새로운 지표를 제안했기 때문에 중요합니다.
💡 핵심 아이디어
LLM이 복잡한 문제를 풀 때 체스 마스터처럼 수십 수 앞을 내다보며 **전체적인 플랜(Global Plan)**을 짜는 것이 아니라, 안개 난 숲길을 걷는 등산가처럼 **당장 발밑의 다음 스텝(Next Step)**만 계산하며 나아간다는 것입니다. 즉, 모델은 답이 나올 때까지 전체 그림을 보지 못하고, 말(토큰)을 하나씩 이어 붙이는 과정에서 마지막 단계에 가서야 답으로 수렴한다는 ‘근시안적 지평선(Myopic Horizon)’ 특성을 가집니다.
문제 정의
이 논문은 “LLM이 실제로 추론(Reasoning)을 위해 CoT를 사용하는가, 아니면 이미 답을 알고 있고 CoT는 단순히 설명(Explanation)을 위한 것인가?”라는 지속적인 논쟁을 해결하고자 합니다. 즉, CoT 생성 전 모델 내부에 어떤 계획이 존재하는지, 그리고 이 내부 상태가 얼마나 정확히 미래의 추론 경로를 예측하는지 규명하는 것이 핵심 문제입니다.
🔬 방법론 상세
- Tele-Lens (프로빙 기법): 모델의 내부 은닉 상태(Hidden States, 뉴럴 네트워크의 중간 레이어 값)를 분석하여 모델이 현재 무엇을 계획하고 있는지 들여다보는 분석 방법입니다.
- 핵심 토큰 vs 채우기 토큰 분리: CoT 생성 과정에서 추론의 방향을 결정하는 중요한 ‘핵심 토큰(Critical Tokens)‘과 문법적 완성을 위한 ‘채우기 토큰(Filler Tokens)‘을 구분하여, 단순히 전체 토큰의 평균을 내는 것이 아니라 핵심 토큰 주변의 신호에 집중합니다.
- CoT 불확실성 추정 메트릭:
- Perplexity (혼란도): 모델이 다음 토큰을 예측할 때 얼마나 ‘당황’했는지를 나타내는 지표.
- Average Token Entropy (평균 토큰 엔트로피): 예측 확률 분포의 불확실성 정도 (높을수록 불확실).
- Self-Certainty (자기 확신도): 모델이 자신의 예측에 얼마나 확신을 갖고 있는지를 측정하는 최신 지표.
핵심 기법
가장 중요한 발견은 **‘근시안적 계획(Myopic Planning)‘**을 활용하는 것입니다. 모델이 답을 미리 다 짜놓지 않는다는 점을 역이용해, CoT 진행 중 특정 시점의 내부 상태만 봐도 그 답이 맞을지 틀릴지(불확실성) 혹은 굳이 긴 CoT를 써야 하는지(필요성)를 더 정확하게 예측할 수 있습니다. 전체 평균이 아닌 **‘결정적 순간(Critical Tokens)‘**의 신호를 포착하는 것이 핵심입니다.
📊 정량적 결과
주요 성과
- 계획 범위 발견: 실험 결과, LLM은 전체적인 글로벌 플래닝(Global Planning)을 수행하지 않으며, 주로 점진적인 전이(Incremental Transitions)에 의존하는 근시안적 특성을 보였습니다.
- 수렴 시점 분석: 명시적이고 구성적인 추론(Explicit Compositional Reasoning) 과제에서 모델은 추론 과정이 거의 끝날 때쯤에서야 최종 답안으로 수렴(Converge)합니다.
- 상관관계: 도입부 언급된 선행 연구(Dong et al., 2025)에 따르면 초기 은닉 상태는 전체 추론 단계와 속성을 높은 상관관계(High Correlation)로 예측할 수 있었으나, 본 연구는 이를 세분화하여 실제 계획은 단기적임을 입증했습니다. (제공된 텍스트 내에서 특정 퍼센트(%) 수치는 명시되지 않으나, ‘근시안적 지평선’의 발견이 주요 정량적/정성적 성과입니다.)
🚀 기존 대비 개선점
- 불확실성 추정의 정교화: 기존의 전체 문장에 대한 Perplexity(혼란도)나 엔트로피 평균을 사용하는 방식보다, 핵심 토큰에서의 국부적 신호를 분석하여 모델의 불확실성을 더 정확히 파악할 수 있습니다.
- CoT 효율성 판단: 모델이 긴 사고 과정이 필요한지, 아니면 이미 답을 알고 있는지(불필요한 CoT인지)를 내부 상태를 통해 판단하여 추론 비용을 절약할 수 있는 가능성을 제시합니다.
- 통합적 관점 제공: “모델이 내부적으로 계획한다”는 연구와 “CoT가 중요하다”는 연구 사이의 모순되어 보이는 관점을 ‘근시안적 계획’이라는 개념으로 설명 가능하게 만들었습니다.
🎯 활용 분야
- 자기 평가(Self-Evaluation) 시스템: 모델이 생성하는 답변의 신뢰도를 스스로 판단하여, 낮은 신뢰도의 답변을 자동으로 필터링하거나 재생성 요청.
- 추론 최적화: 불확실성이 낮은 문제는 CoT 없이 바로 답을 생성하게 하여 추론 속도 및 비용 효율성 향상.
- AI 안전성(Safety): 모델이 악의적인 추론을 진행하기 전에 내부 상태를 감시하여 사전에 차단하는 안전 장치 개발.
한계 및 주의사항
- 늦은 수렴(Late Convergence): 모델이 추론 과정이 막바지에 다다라서야 최종 답으로 수렴하므로, 추론 과정 도중에 중간 결과만으로는 성공 여부를 미리 예측하기 어렵습니다.
- 메커니즘의 복잡성: 내부 계획이 전혀 없는 것은 아니지만 매우 단기적(근시안적)이기 때문에, 이를 조작하여 성능을 높이는 기술은 추가적인 연구가 필요합니다.
4. MARS: Modular Agent with Reflective Search for Automated AI Research
arXiv: 2602.02660 | 기관: Google | ⬆️ 47 📊 순위선정 | 📕 PDF 태그:
ai-agentautomated-researchmarsmctsresource-awarereflective-memoryllmautoml사전 지식: Large Language Models (LLM), Monte Carlo Tree Search (MCTS), Software Modularity (모듈화), Context Window (맥락 창), MLOps (머신러닝 운영)
한 줄 요약
기존 LLM 에이전트가 AI 연구 자동화에서 겪는 높은 계산 비용과 불투명한 성능 분석 문제를 해결하기 위해, 모듈형 코드 생성, 반성적 기억, **자원 인식 탐색(MCTS)**을 결합한 MARS 프레임워크를 제안하여 연구 효율성과 성능을 획기적으로 개선했습니다.
💡 핵심 아이디어
MARS는 마치 건축 설계사가 공사를 관리하는 방식과 같습니다. 기존 에이전트는 집을 통째로 짓려다 실패(단일 스크립트)하는 반면, MARS는 설계도를 보고 공장에서 부품을 미리 만들어 조립하며(모듈형 구성), 과거의 시공 실수를 수첩에 적어 두지 않고 개선하고(반성적 기억), 예산(시간/돈)을 고려해 가장 효율적인 공정 순서를 짜는(자원 인식 계획) 방식으로 복잡한 AI 연구를 수행합니다.
문제 정의
AI 연구 자동화는 일반 소프트웨어 엔지니어링과 달리 **모델 학습에 드는 막대한 비용(Computationally expensive evaluation)**과 **어떤 요소가 성능 향상에 기여했는지 알기 어려운 문제(Opaque performance attribution)**가 있습니다. 기존 에이전트들은 이러한 현실적인 제약을 무시한 채 거대한 덩어리의 코드(Monolithic scripts)를 생성하여, 비효율적이고 비용이 과도하게 소모되는 결과를 초래했습니다.
🔬 방법론 상세
- 모듈형 구성 전략 (Modular Construction Strategy): 하나의 거대한 스크립트를 짜는 대신, 레포지토리(저장소) 수준의 구조화된 소프트웨어 아키텍처를 강제합니다. 이는 코드의 재사용성을 높이고, 복잡한 로직을 처리할 때 정확도를 높이며 테스트를 용이하게 합니다.
- 반성적 기억 (Reflective Memory): LLM의 문맥 창(Context window, 한 번에 처리할 수 있는 텍스트 길이) 한계를 극복하기 위해 “Lesson Learning” 메커니즘을 도입했습니다. 과거의 시행착오(Successes & Failures)에서 얻은 통찰을 증류(Distill)하여 압축된 검색 가능한 지식 베이스로 저장하고, 필요할 때마다 불러와 재발 방지 및 전략 수립에 활용합니다.
- 자원 인식 계획 (Resource-Aware Planning): 주어진 예산(Budget, 예: 시간, GPU 비용) 내에서 목표(Objective)를 최대화하기 위해 예산 인식 몬테카를로 트리 서치(MCTS, Monte Carlo Tree Search) 알고리즘을 사용합니다. 이 알고리즘은 유망한 후보군을 집중적으로 탐색(Exploitation)하고 새로운 아이디어를 시도(Exploration)하는 것의 균형을 맞추며, 비용이 많이 드는 솔루션은 페널티를 주어 자동으로 배제합니다.
핵심 기법
이 논문의 핵심은 **몬테카를로 트리 서치(MCTS)**를 연구 과정에 적용한 점입니다. MCTS는 복잡한 게임(바둑 등)에서 수를 두듯, 시도해 볼 수 있는 연구 방법들을 ‘나무’의 가지라고 생각하고, 비용 대비 성과가 좋을 것 같은 가지를 우선적으로 탐색합니다. 이로 인해 “무작정 많이 돌려보기”보다 “정해진 예산 안에서 가장 가능성 높은 길 찾기”가 가능해집니다.
📊 정량적 결과
주요 성과
- 데이터셋: MLE-Bench (Kaggle 대회 75개, NLP/CV/Tabular 포함)
- 실험 환경: NVIDIA A100(40GB) 1장, 12 vCPUs, 220GB RAM, 1TB SSD, 엄격한 24시간 시간 제한
- 비교 대상: MLE-Bench 리더보드 에이전트, AIDE(Jiang et al., 2025), AIRA(Toledo et al., 2025)
- 평가 지표: Above Median Rate(중위권 이상 비율), Any Medal Rate(메달 획득 비율), Gold Medal Rate(금메달 획득 비율)
- 주의: 제공된 원문 요약에 구체적인 수치 개선치(예: 15% 증가)는 포함되어 있지 않으나, 엄격한 자원 제한 하에 기존 최신 기법들과 비교하여 메달 획득률 등의 지표를 통해 우수함을 입증했다고 서술함.
🚀 기존 대비 개선점
- 비용 효율성: 계산 비용이 높은 모델 학습 과정을 경제적 현실을 고려한 계획(MCTS)을 통해 최적화하여, 예산 낭비를 줄였습니다.
- 복잡도 관리: 단일 스크립트가 아닌 모듈형 아키텍처를 도입하여, 긴 시간의 연구(Long-horizon) 과정에서 코드를 유지보수하고 재사용하기 쉬워졌습니다.
- 맥락 학습: 과거의 실패와 성공을 압축해서 학습하는 반성적 기억 시스템을 통해, 같은 실수를 반복하지 않고 점진적으로 연구 역량을 향상시킵니다.
🎯 활용 분야
- AutoML(자동화된 머신러닝): 모델 아키텍처 설계부터 하이퍼파라미터 튜닝까지 사람 개입 없이 자동으로 수행하는 시스템.
- 경진대회 자동 참여: Kaggle 같은 데이터 분석 대회에 에이전트를 참여시켜 상위권 성적을 거두는 솔루션 개발.
- 연구 지원 도구: 연구원이 복잡한 실험 파이프라인을 구축할 때, 시간과 비용을 최적화하는 코파일럿(Copilot) 역할.
한계 및 주의사항
- 계획의 오버헤드: 자원 인식 계획(MCTS)을 세우는 데에도 일부 연산 비용과 시간이 소모되므로, 매우 짧은 시간의 단순 작업에서는 오히려 비효율적일 수 있습니다.
- LLM 의존성: 프레임워크의 성능은 여전히 기본이 되는 LLM의 추론 능력과 코딩 능력에 크게 의존합니다.
- 아키텍처 복잡성: 모듈형 접근 방식은 강력하지만, 초기에 구조를 잡는 과정이 단일 스크립트 작성보다 더 복잡할 수 있습니다.
5. 3D-Aware Implicit Motion Control for View-Adaptive Human Video Generation
arXiv: 2602.03796 | 기관: Kling Team | ⬆️ 43 📊 순위선정 | 📄 HTML 태그:
video-generation3d-awaremotion-controldiffusion-modelcomputer-visionimplicit-representationgenerative-ai사전 지식: )을 오히려 망가뜨리게 됩니다.

한 줄 요약
기존 2D 포즈나 명시적 3D 모델(SMPL)의 한계를 넘어, 비디오 생성 모델이 가진 본연의 3D 공간 인지 능력을 보존하면서 카메라 시점에 독립적인 암시적(Implicit) 모션 표현을 학습시켜 자유로운 시점 전환이 가능한 인간 비디오 생성 기법을 제시했습니다.
💡 핵심 아이디어
2D 포즈를 제어 신호로 쓰는 기존 방식은 ‘벽에 비친 그림자’처럼 카메라 위치에 딱 붙어버려 새로운 각도에서의 영상을 만들 수 없습니다. 반면, SMPL 같은 3D 모델은 ‘목재 인형’처럼 구조는 명확하지만 움직임이 부자연스럽거나 깊이 정보가 부정확하여 영상 품질을 떨어뜨립니다. 이 논문의 **3DiMo(3D-aware Implicit Motion)**는 움직임의 본질적인 ‘의도’를 암시적인 신호로 학습하여, 카메라가 어디에 있든 그 의도에 맞춰 유연하고 자연스럽게 움직이도록 만드는 ‘가상의 안무가’를 모델 안에 심는 것과 같습니다.
문제 정의
대규모 비디오 생성 모델은 이미 강력한 3D 공간 인지 능력을 갖추고 있지만, 기존의 움직임 제어(Motion Control) 방식들이 이를 제한하고 있다는 문제가 있습니다. 2D 포즈를 쓰면 새로운 시점(Novel-view) 생성이 불가능하고, SMPL 같은 명시적 3D 모델을 강제로 적용하면 모델 자체의 부정확성(깊이 모호함 등)이 발동하여 생성 모델이 가진 훌륭한 3D prior(사전 지식)을 오히려 망가뜨리게 됩니다.
🔬 방법론 상세
- 암시적 모션 인코더 (Implicit Motion Encoder): 2D 구동 프레임(Driving frames)을 입력받아, 특정 시점에 종속되지 않는 **모션 토큰(Motion Tokens)**을 추출하는 네트워크를 설계하고 이를 생성 모델과 공동 최적화(Joint Optimization)합니다.
- 크로스 어텐션(Cross-Attention) 기반 주입: 추출된 모션 토큰을 텍스트 프롬프트와 결합하여, DiT(Diffusion Transformer) 백본의 공간적 레이어에 주입합니다. 이를 통해 텍스트로 카메라 움직임을 제어하면서도 모션은 독립적으로 조작할 수 있습니다.
- 시점 풍부 데이터 학습 (View-rich Training): 다양한 카메라 각도와 움직임이 포함된 데이터셋에서 모델을 학습시키고, 초기 학습 단계에서는 보조 디코더(Auxiliary Decoders)를 통해 기하학적 정렬(Geometric Alignment) 감독 신호를 제공하여 3D 이해도를 높입니다.
핵심 기법
뷰-어그노스틱(View-agnostic) 표현 학습이 핵심입니다. 연구진은 모델이 2D 영상에서 볼 때는 “팔이 오른쪽으로 간다”고 보이는 현상(2D)이, 실제 3D 공간에서는 “팔을 앞으로 뻗는다”는 본질적인 움직임임을 이해하도록 유도했습니다. 이를 위해 모션 인코더가 입력 이미지의 레이아웃(시점 의존적 요소)을 버리고 오직 움직임의 시맨틱(Semantic) 정보만 캡처하도록 설계했습니다.
📊 정량적 결과
주요 성과
- FVD (Fréchet Video Distance): 379.6을 기록하여, 경쟁 모델인 AnimateAnyone(862.5) 대비 약 56% 이상 감소했습니다. 이는 전체 비디오의 자연스러움과 일관성이 크게 향상되었음을 의미합니다.
- PSNR (Peak Signal-to-Noise Ratio): 18.03으로 AnimateAnyone(17.21) 대비 픽셀 단위의 재현 정확도가 높아졌습니다.
- 사용자 연구(User Study): 정확도(Accuracy)와 자연스러움(Naturalness), 3D 타당성(3D Plausibility) 항목에서 대부분 최고 점수를 기록하며, 인간이 평가한 주관적 품질에서도 우수함을 입증했습니다.
🚀 기존 대비 개선점
- 독립적인 카메라 제어: 움직임(Motion)과 카메라 궤적(Camera Trajectory)을 분리하여, 같은 동작이라도 텍스트 프롬프트(“Zoom in”, “Pan left” 등)를 통해 원하는 각도로 촬영한 듯한 영상을 생성할 수 있습니다.
- 외부 3D 모델 무의존성: SMPL 피팅(Fitting) 과정이 필요 없으므로, 3D 재구성 오류가 생성 품질에 악영향을 미치는 것을 방지하고 추론 속도의 병목도 줄였습니다.
- 높은 3D 일관성: 생성된 인물이 비디오 내에서 회전하거나 카메라가 움직일 때도 기하학적 뒤틀림 없이 일관된 3D 형태를 유지합니다.
🎯 활용 분야
- 버추얼 유튜버/아바타: 사용자의 동영상을 입력받아 캐릭터가 똑같이 춤추게 하되, 자유자재로 카메라 앵글을 연출할 수 있는 메타버스 콘텐츠 제작.
- 영화 및 애니메이션 프리비주(Pre-visualization): 실제 촬영 전, 배우의 동작을 캡처하여 다양한 카메라 워킹(Shoting)을 적용한 스토리보드 영상으로 빠르게 변환.
- AR/VR 체험 헬스케어/피트니스: 사용자의 운동 자세를 3D로 분석하여, 정면/측면/상단 등 다양한 각도에서의 교정 영상을 실시간으로 생성하여 피드백 제공.
한계 및 주의사항
- 제공된 논문 내용에서는 명시적인 실패 사례를 언급하지 않았으나, 암시적 표현을 제대로 학습하기 위해 **다양한 시점이 포함된 고품질의 대규모 데이터(View-rich data)**가 필수적으로 요구된다는 점이 추론됩니다. 학습 데이터의 시점 다양성이 부족하면 3D 인지 능력이 저하될 수 있습니다.
6. daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently
arXiv: 2602.02619 | 기관: SII - GAIR | ⬆️ 43 | ⭐ 25 🤖 GLM추천 | 📄 HTML 태그:
ai-paperml사전 지식: LLM (Large Language Model), Agentic Workflow, Markov Decision Process (MDP), Software Engineering Lifecycle, Data Synthesis, Chain-of-Thought (CoT)

한 줄 요약
이 논문이 중요한 이유는, AI 에이전트가 장기적인 복잡한 작업을 수행하기 위해 필요한 희귀한 데이터를 실제 오픈소스 소프트웨어의 진화 과정(GitHub PR 이력)을 통해 자동으로 확보하여, 비싼 인간 데이터 주석 없이도 장기 의사결정 능력을 효과적으로 학습할 수 있는 길을 열었기 때문입니다.
💡 핵심 아이디어
이 논문은 ‘소프트웨어 진화의 역사’를 AI 에이전트를 위한 교과서로 사용한다는 아이디어를 제시합니다. 마치 주니어 개발자가 시니어 개발자가 과거에 어떤 순서로 버그를 수정하고 기능을 추가했는지(Git 커밋 및 PR 히스토리)를 관찰하며 대규모 프로젝트를 관리하는 법을 익히는 것과 같습니다. 기존의 단편적인 코딩 문제들 대신, 서로 얽히고설킨 실제 개발 과제(Pull Request 체인)를 학습 데이터로 재구성하여 에이전트가 긴 호흡의 작업 흐름을 이해하도록 만듭니다.
문제 정의
현재 LLM(Large Language Model) 기반 에이전트는 짧고 단순한 작업은 잘하지만, 여러 단계에 걸쳐 진행되는 장기간(Long-Horizon) 작업에서는 성능이 급격히 떨어집니다. 핵심 문제는 에이전트가 작업을 시작한 후 방향을 잃거나 누적된 오류를 복구하지 못하는 것인데, 이를 학습시킬 만한 ‘단계 간 의존성(Cross-stage dependency)‘이 포함된 고품질의 학습 데이터가 극도로 부족합니다. 기존 데이터 생성 방식은 너무 단순하거나 인간 비용이 너무 비싸다는 한계가 있었습니다.
🔬 방법론 상세
- MDP(Markov Decision Process) 기반 공식화: 소프트웨어 엔지니어링 작업을 상태(State), 행동(Action), 보상(Reward)으로 정의합니다.
- 상태 ($o_j$): 에이전트가 관찰하는 현재 환경 (코드 베이스 등)
- 행동: 두 가지 모달리티로 분류됩니다.
- 추론 메시지 ($m_j$): 환경을 변화시키지 않는 내적 사고 과정 (계획, 분석)
- 도구 실행 ($t_j$): 파일 수정, 테스트 실행 등 환경을 직접 조작하는 외부 행동
- 궤적 ($\tau$): $(o_0, m_0, t_0), (o_1, m_1, t_1), …$ 와 같이 상태와 행동이 교차로 이어지는 순서를 의미합니다.
- Chain-of-PRs (PR 체인) 데이터 파이프라인: 실제 GitHub 저장소에서 단순한 PR을 넘어, 서로 의존 관계가 있는 PR들을 연결하여 ‘위상적(task) 체인’을 구성합니다.
- 엄격한 데이터 큐레이션: 9개의 대표적인 저장소를 선정하되, 단순히 규모가 큰 것을 넘는 세 가지 기준(규모와 성숙도 >7,000 PR, 커뮤니티 상호작용, 언어적 다양성)을 적용하여 데이터의 질을 보장합니다.
핵심 기법
Chain-of-PRs (PR 체인): 이 기법은 개별적인 코딩 문제들을 고립된 섬으로 보지 않고, 하나의 PR이 다음 PR에 영향을 미치는 **‘진화하는 흐름’**으로 재해석합니다. 이를 통해 AI 에이전트는 “이 기능을 추가하려면 저 모듈을 먼저 수정해야 하고, 그 다음 테스트를 고쳐야 한다”는 식의 장기적인 맥락을 스스로 학습할 수 있습니다.
📊 정량적 결과
제공된 텍스트에는 구체적인 벤치마크 점수(예: SWE-bench 점수 등)는 명시되어 있지 않으나, 데이터 구축 측면에서 다음과 같은 정량적 성과를 달성했습니다.
주요 성과
- 데이터 규모: 단일 저장소당 최소 7,000개 이상의 유효한 PR(효과적인 의존성 구조 포함)을 확보하여, 방대한 장기 의존성 데이터셋 구축.
- 데이터 다양성: Python, Java, C 등 다양한 기술 스택을 아우르는 9개의 고도로 성숙한 저장소를 정성적/정량적으로 분석하여 선정.
- 학습 효율성: 인간의 주석이 없이도 실제 소프트웨어 진화 신호(Evolutionary dynamics)를 통해 감독(Supervision) 신호를 자동 생성하여, 기존의 비싼 증류(Distillation) 방식 대비 비용 효율성 확보.
🚀 기존 대비 개선점
- 단순 합성 데이터의 한계 극복: 기존 모델 분포에 갇혀 있는 단일 기능 시나리오를 탈피, 실제 세계의 복잡한 의존성을 반영.
- 누적 오류 감소: 장기 작업 중 발생하는 오류를 수정하는 과정(Refinement)이 데이터에 자연스럽게 포함되어, 에이전트의 방향 유지 능력 강화.
- 검증 가능성: PR 단위로 작업이 나뉘기 때문에 각 단계의 성공 여부를 자동으로 검증 가능.
🎯 활용 분야
- 자율 소프트웨어 엔지니어링: 장기간에 걸친 레거시 코드 리팩토링이나 대규모 기능 추가 자동화.
- 지속적 통합/배포(CI/CD) 자동화: 복잡한 빌드 및 배포 파이프라인에서 발생하는 문제를 단계적으로 해결하는 에이전트 개발.
- 복잡한 시스템 유지보수: 여러 모듈에 걸쳐 발생하는 버그를 추적하고 수정하는 긴 호흡의 디버깅 시스템.
한계 및 주의사항
- 저장소 편향성: 데이터 선정 단계에서 ‘성숙하고 활동적인’ 저장소 위주로 샘플링되었기 때문에, 초기 프로젝트나 낮은 활동성을 보이는 도메인에 대한 일반화에는 한계가 있을 수 있습니다.
- 구현 의존성: 특정 기술 스택(Python, Java, C)에 집중되어 있어, 이를 벗어나는 최신 언어나 프레임워크에 대한 적용은 추가적인 데이터 확보가 필요합니다.
7. Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection
arXiv: 2602.03216 | ⬆️ 9 🤖 GLM추천 | 📄 HTML 태그:
long-contextattention-optimizationsparse-attentioninference-accelerationllm-efficiencytoken-selectionreversible-computation사전 지식: Transformer Architecture, Attention Mechanism (Q, K, V), Prefill Stage (프롬프트를 처리하여 캐시를 채우는 초기 단계), Computational Complexity (시간 복잡도), Sparse Attention (희소 어텐션)

한 줄 요약
이 논문은 긴 문맥 처리 시 발생하는 연산량의 급격한 증가(이차 복잡도) 문제를 해결하기 위해, 불필요한 토큰을 동적으로 선택적으로 계산했다가 다시 복원하는 ‘Token Sparse Attention’ 기법을 제안하여 속도를 획기적으로 높이면서도 모델의 정확도를 유지하는 데 중요한 의미가 있습니다.
💡 핵심 아이디어
이 방법은 마치 **“속독 훈련을 받은 독서가”**와 같습니다. 책을 읽을 때 모든 단어를 같은 중요도로 읽는 대신, 각 문단(레이어)마다 중요한 단어(토큰)만 골라 집중적으로 읽고(Sparse Attention), 그 내용을 요약해서 기억합니다. 하지만 나중에 문맥이 바뀌면 아까 살짝 건너뛴 단어라도 다시 꺼내볼 수 있도록(Reversible) 요약본을 원래 크기로 다시 펼쳐 놓아, 중요한 정보를 놓치지 않으면서도 읽는 속도(연산량)를 획기적으로 줄입니다.
문제 정의
(이 논문이 해결하려는 핵심 문제) 현재 LLM(대규모 언어 모델)들이 긴 문서나 대화 기록(Long Context)을 처리할 때, 어텐션 메커니즘(Attention Mechanism, 토큰 간의 관계를 계산하는 과정)으로 인해 계산량이 입력 길이의 제곱($L^2$)만큼 늘어나는 이차 복잡도(Quadratic Complexity) 문제입니다. 기존의 해결책들은 불필요한 토큰을 아예 삭제해버리거나, 뭉쳐서(Block-level) 처리하다 보니 중요한 정보를 잃거나 비효율적인 계산이 발생하는 한계가 있었습니다.
🔬 방법론 상세
- 헤드별 동적 토큰 압축 (Per-head Dynamic Compression): 모든 헤드(Head, 여러 개의 시각각도로 문맥을 파악하는 단위)가 동일한 토큰을 중요하게 여기는 것이 아니므로, 각 헤드마다 따로 중요한 토큰을 선택하여 Q(Query), K(Key), V(Value) 행렬을 압축합니다.
- 압축 및 복원 메커니즘 (Compression & Decompression): 어텐션 계산을 수행하기 전에 토큰을 줄여서(압축) 계산하고, 계산이 끝난 결과물(Attention Output)을 다시 원래 시퀀스의 길이로 복원(Decompression)합니다. 이를 통해 다음 레이어에서 토큰의 중요도를 다시 평가할 수 있는 기회를 제공합니다.
- 토큰 커버리지 파라미터 ($\tau$): 전체 토큰 중 얼마나 많은 비율을 선택해서 계산할지를 결정하는 파라미터(예: $\tau=0.005$, 전체의 0.5%)를 사용하여 속도와 정확도 사이의 균형을 조절합니다.
핵심 기법
가장 중요한 방법론은 **“영구 삭제가 아닌 일시적 생략”**입니다. 기존 방법들은 중요하지 않다고 판단되면 토큰을 영구적으로 버려(Eviction), 나중에 그 정보가 필요해져도 되살릴 수 없었습니다. 반면, 이 논문의 방식은 토큰을 계산 과정에서만 잠시 생략했다가, 출력 단계에서 다시 원래 자리에 복구시키기 때문에 정보 손실 없이 효율성을 극대화할 수 있습니다.
📊 정량적 결과
주요 성과
- 벤치마크: LLaMA-3.1-8B 및 Mistral-Nemo-12B 모델에서 RULER 및 InfiniteBench(긴 문맥 이해력 평가 데이터셋)를 통해 검증되었습니다.
- 효율성: Token Coverage(토큰 유지율) $\tau=0.005$ 매우 낮은 설정에서도 기존 방법보다 더 나은 정확도-지연시간(Accuracy-Speedup) Trade-off를 달성했으며, FlexPrefill 같은 다른 가속 기법과 결합했을 때 상호 보완적인 성능 향상을 보였습니다.
- 호환성: FlashAttention 커널을 수정하지 않고도 통합되어, 기존 하드웨어 최적화 기술과 매끄럽게 작동함이 입증되었습니다.
🚀 기존 대비 개선점
- 가역성(Reversibility): 토큰을 영구 삭제하지 않고 압축/복원 과정을 거치므로, 뒷단 레이어에서 중요도가 재평가될 수 있습니다.
- 토큰 단위의 세밀한 제어: 기존 Block-level(블록 단위) 희소성 방식보다 토큰 개별 단위로 선택하기 때문에, 불필요한 토큰을 더 정교하게 걸러낼 수 있습니다.
- 범용성: 특정 모델 구조에 종속되지 않고 기존의 Dense(밀집) 및 Sparse(희소) 어텐션 커널과 모두 호환됩니다.
🎯 활용 분야
- 장문 문서 요약: 수백 페이지에 달하는 보고서나 책을 빠르게 처리하여 핵심 내용을 요약할 때 유용합니다.
- 긴 대화 기록 처리: 챗봇이 과거의 대화 맥락을 매우 길게 유지하면서도 빠른 응답 속도를 내야 하는 멀티턴(Multi-turn) 대화 시스템에 적합합니다.
- 대규모 코드 분석: 긴 소스 코드를 이해하고 생성해야 하는 코딩 보조 도구에서 전체 코드베이스를 빠르게 참조하는 데 활용될 수 있습니다.
한계 및 주의사항
- 압축/복원 오버헤드: 토큰을 선택하고 압축/복원하는 과정 자체에도 약간의 연산 비용이 발생하므로, 매우 짧은 문맥에서는 효과가 미미할 수 있습니다.
- 최적 파라미터 탐색: 어떤 토큰 비율($\tau$)을 선택할지가 성능에 큰 영향을 주므로, 작업(Task)별로 최적의 설정을 찾아야 합니다.
8. Decouple Searching from Training: Scaling Data Mixing via Model Merging for Large Language Model Pre-training
arXiv: 2602.00747 | ⬆️ 8 🤖 GLM추천 | 📄 HTML 태그:
llmdata-mixingmodel-mergingpre-trainingefficiencyde-mixoptimization사전 지식: Large Language Models (LLM), Pre-training (사전 학습), Data Mixing (데이터 혼합), Model Merging (모델 병합), Proxy Task (프록시 태스크)

한 줄 요약
이 논문은 LLM 사전 학습에서 최적의 데이터 비율을 찾기 위해 기존의 비싼 ‘프록시 모델 학습’ 방식을 대체하여, **모델 병합(Model Merging)**을 통해 학습 없이 가상의 성능을 예측하는 ‘DeMix’ 프레임워크를 제안하여 탐색 비용을 획기적으로 줄이고 수학 및 코딩 성능을 크게 향상시켰다는 점에서 매우 중요합니다.
💡 핵심 아이디어
이 논문의 핵심 아이디어는 “완성된 요리를 여러 번 새로 해보는 대신, 각 재료를 따로 조리한 뒤 가지고 놀며 비율을 맞춰보는 것”과 같습니다. 기존 방식(RegMix, CLIMB)은 데이터 비율을 바꿀 때마다 작은 모델을 처음부터 다시 학습(새로 요리)시켜야 해서 비용이 많이 들었지만, DeMix는 각 데이터 도메인별로 학습된 모델(컴포넌트 모델)을 가중치에 따라 수학적으로 섞기만 하면 되므로, 추가 학습 없이 매우 빠르게 최적의 데이터 비율을 찾아낼 수 있습니다.
문제 정의
LLM(대규모 언어 모델) 사전 학습에서 일반 언어 능력과 수학, 코딩 같은 특수 분야의 능력을 모두 잡기 위한 최적의 데이터 혼합(Data Mixture) 비율을 찾는 것은 매우 어렵고 비용이 많이 드는 문제입니다. 기존의 방법들은 다양한 비율을 실험해보기 위해 중간 크기의 모델을 수십 번씩 반복 학습해야 했기에, 시간과 비용 낭비가 심했습니다.
🔬 방법론 상세
- 컴포넌트 모델(Component Models) 학습: 서로 다른 후보 데이터셋(예: 수학, 코드, 일반 텍스트 등)을 특정 비율(β=0.5)로 섞어서 여러 개의 모델을 각각 학습시킵니다.
- 가중 선형 병합(Weighted Linear Merging): 새로운 모델을 학습시키는 대신, 학습된 컴포넌트 모델들의 파라미터(가중치)를 가중치에 따라 선형적으로 평균 내어 가상의 혼합 모델(Proxy)을 생성합니다. 이를 통해 $M_{mix} = \sum w_i M_i$ 와 같은 방식으로 특정 데이터 비율로 학습된 효과를 모방합니다.
- 반복적 탐색 및 LightGBM 예측: 병합을 통해 생성된 수많은 가상 모델을 벤치마크에서 평가하고, 그 결과를 바탕으로 머신러닝 모델(LightGBM)을 사용하여 최적의 데이터 가중치를 예측합니다.
핵심 기법
**학습 없는 모델 병합(Training-free Model Merging)**이 핵심입니다. 보통 데이터 비율을 바꾸면 모델을 처음부터 다시 학습해야 하지만, DeMix는 이미 학습된 모델들의 가중치를 단순히 더하는 방식(Linear Interpolation)만으로도 특정 데이터 비율로 학습했을 때의 성능을 거의 정확하게 예측할 수 있다는 점을 활용합니다. 이로 인해 탐색 과정에서의 연산 비용이 거의 0에 수렴합니다.
📊 정량적 결과
주요 성과
- 수학 성능 (Math Avg): DeMix는 **24.43%**를 달성하여, 기존 최고 방식(CLIMB)의 20.53% 대비 약 4%포인트 이상의 큰 향상을 보였습니다.
- 코딩 성능 (Code Avg): DeMix는 **21.79%**를 기록하여, CLIMB의 **21.10%**보다 소폭이지만 확실하게 우위를 점했습니다.
- 탐색 효율성: 동일한 GPU 시간 대비 벤치마킹 비용(Benchmarking cost)이 기존 방식 대비 획기적으로 절감되었습니다(표 상 0.01†로 표기됨).
🚀 기존 대비 개선점
- 비용 획기적 절감: 기존 방식(RegMix 등)은 최적 비율을 찾기 위해 수십 개의 프록시 모델을 학습해야 했지만, DeMix는 소수의 컴포넌트 모델만 학습하면 되므로 전체 탐색 비용이 획기적으로 줄어듭니다.
- 확장성(Scalability): 제한된 예산으로도 더 많은 데이터 혼합 조합(Mixture)을 시도해볼 수 있어, 더 복잡하고 대규모의 데이터셋에 대해서도 최적화가 가능합니다.
- 난제(Hard Task) 성능 향상: 단순히 전체 성능만 유지하는 것이 아니라, 수학과 코딩처럼 학습이 어려운 영역에서의 성능을 특히 잘 높여줍니다.
🎯 활용 분야
- 대규모 LLM 사전 학습 데이터 구성: 수십 토큰 이상의 데이터를 학습시키기 전에, 최소의 비용으로 가장 효율적인 데이터 구성을 설계할 수 있습니다.
- 도메인 특화 모델 개발: 의료, 금융, 법률 등 특정 도메인 데이터를 일반 데이터와 얼마나 섞어야 할지 결정할 때 활용할 수 있습니다.
- 데이터 효율성 연구: 모델의 성능 향상을 위해 데이터의 양을 늘리는 것보다 질과 비율을 최적화하는 연구에 기여합니다.
한계 및 주의사항
- 선형 결합의 가정: 이 방법은 모델의 파라미터가 선형적으로 결합 가능하다는 가정에 기초합니다. 만약 데이터 간의 상호작용이 매우 비선형적이라면, 병합을 통한 예측이 실제 학습 결과와 정확히 일치하지 않을 수 있습니다.
- 초기 컴포넌트 비용: 탐색 비용은 줄어들지만, 여러 컴포넌트 모델을 학습하는 초기 비용(Pre-Cost)은 여전히 필요합니다.
9. Privasis: Synthesizing the Largest “Public” Private Dataset from Scratch
arXiv: 2602.03183 | 기관: NVIDIA | ⬆️ 1 🤖 GLM추천 | 📄 HTML 태그:
privacy-preserving-mlsynthetic-datapii-sanitizationllm-finetuningon-device-aiagentic-ainlp사전 지식: Synthetic Data (합성 데이터), PII (Personally Identifiable Information, 개인 식별 정보), LLM Fine-tuning, On-device Inference (온디바이스 추론), Decomposition (분해)

한 줄 요약
프라이버시 연구의 근본적인 데이터 부족 문제를 해결하기 위해 140만 개의 완전 합성(가상) 민감 정보 데이터셋을 최초로 구축하여, GPT-5 같은 초거형 모델보다 작고 가벼운(4B 이하) 온디바이스 모델이 훨씬 더 뛰어난 개인정보 비식별화 성능을 내도록 만들었기 때문에 매우 중요합니다.
💡 핵심 아이디어
진짜 개인정보는 유출 위험 때문에 연구용으로 공유하기 어렵습니다. 이 논문은 마치 ‘VIP 경비원’을 훈련시키기 위해 진짜 VIP 대신, 행동 패턴과 정보가 완벽하게 구현된 ‘가상 인형 140만 개’를 대량 생산하여 연구자들이 무료로 마음껏 훈련시킬 수 있게 해주었습니다. 이를 통해 데이터가 부족해 난항을 겪던 프라이버시 보호 AI 연구를 가속화할 수 있습니다.
문제 정의
개인정보를 포함한 텍스트를 안전하게 처리하는 AI 모델을 개발하려면 많은 실제 데이터가 필요하지만, 실제 개인정보는 공유가 불가능해 심각한 ‘데이터 가뭄(Data Drought)’ 상태입니다. 특히 이메일, 캘린더, 의료 기록 등을 처리하는 최신 AI 에이전트(Agent)들은 개인정보를 자동으로 가려주는 강력한 보안 기능이 필수적이며, 이를 위한 데이터와 모델이 절실합니다.
🔬 방법론 상세
- 합성 데이터 생성 (Synthetic Data Generation): ‘보조 제어 변수(Auxiliary Control Variables)‘를 사용해 의료, 금융, 이메일 등 다양한 도메일의 민감 정보를 포함한 텍스트 초안을 초기화하고, 전체 데이터의 다양성을 보존하며 정교하게 다듬는(Refinement) 과정을 통해 데이터셋을 구축했습니다.
- 분해 기반 비식별화 파이프라인 (Decomposition-based Sanitization Pipeline): 긴 텍스트를 한 번에 처리하면 모델이 맥락을 잃거나 놓치기 쉽습니다. 이를 해결하기 위해 텍스트를 개행 문자나 EOS(End of Sequence, 문장 끝) 마커를 기준으로 작은 덩어리(Chunk)들로 쪼개어 개별적으로 처리한 뒤 합치는 방식을 사용했습니다.
- Privasis-Sanitization 삼중 쌍(Triplet) 학습: (원본 레코드, 비식별화 지시어, 비식별화된 레코드)의 삼중 쌍으로 구성된 병렬 말뭉치를 구축하여, 모델이 유창성과 유용성을 유지하면서도 특정 속성만 삭제하거나 추상화할 수 있도록 훈련시켰습니다.
핵심 기법
**분해 기반 파이프라인(Decomposition-based Pipeline)**은 아주 긴 이메일이나 보고서를 처리할 때, 모델이 앞부분의 내용을 잊어버리는 것을 방지하기 위해 문단이나 문장 단위로 잘게 쪼개서 처리하는 기법입니다. 이를 통해 거대한 모델이 아니라 작은 모델(Lite)을 사용하더라도 긴 문맥을 꿰뚫어 보고 개인정보를 정확하게 골라낼 수 있습니다.
📊 정량적 결과
주요 성과
- 데이터 규모: 기존 소규모 데이터셋을 뛰어넘는 총 140만 개의 레코드를 포함하는 첫 백만 규모의 합성 민감 데이터셋 구축.
- 모델 효율성: 40억(4B) 파라미터 이하의 작은 모델(Qwen3 기반)을 학습시켜, GPT-5나 Qwen3-235B(2350억 파라미터)와 같은 초거형 모델(Frontier Model)보다 텍스트 비식별화 성능이 우월함을 입증.
- 평가 방식: 직접 유출(Exact String Match), 추론 유출(사실적 질문 통해 추측 가능성), 근접 유출 등 3단계 계층적 평가 프레임워크를 통해 엄격하게 검증.
🚀 기존 대비 개선점
- 데이터 접근성: 기존에는 공유가 불가능했던 민감 데이터를 ‘합성’이라는 방법으로 완전 공개(Public)하여, 연구 커뮤니티 전체의 연구 속도를 획기적으로 높였습니다.
- 로컬 배치 가능성: 비싼 클라우드 모델(GPT-5 등) 없이도, 사용자의 개인 기기(On-device)에서만 돌아가는 작은 모델로도 더 뛰어난 프라이버시 보호가 가능해졌습니다.
- 유연한 제어: 고정된 개인정보 종류(예: 이름, 전화번호)에만 국한되지 않고, 사용자가 정의한 임의의 지시어에 따라 다양한 수준(마스킹, 삭제, 추상화)으로 정보를 가릴 수 있습니다.
🎯 활용 분야
- 개인정보 보호 필터: 사용자의 이메일, 채팅, 문서가 외부 AI 에이전트로 전송되기 전에 실시간으로 개인정보를 자동으로 가려주는 미들웨어 개발.
- 의료/금융 분석 AI: 실제 환자나 고객의 기록을 노출하지 않으면서도, 의료 진단이나 금융 사기 탐지 모델을 학습시키는 연구용 데이터셋으로 활용.
- 보안 온디바이스 비서: 스마트폰이나 노트북 내에서 데이터가 인터넷으로 나가지 않고 기기 내에서만 처리되는 완전히 보안된 개인용 비서 구현.
한계 및 주의사항
- 합성 데이터의 현실성: 아무리 다양하게 생성했다 해도, 실제 세계의 매우 희귀하거나 예기치 못한 데이터 패턴(Edge Case)이 완벽하게 반영되지 않을 가능성이 있습니다.
- 평가자의 편향: 성능 평가에 사용된 LLM 평가자(GPT-OSS-120B)가 특정 답변 스타일이나 패턴을 선호할 수 있으므로, 실제 환경에서의 성능과 차이가 있을 수 있습니다.
10. MemoryLLM: Plug-n-Play Interpretable Feed-Forward Memory for Transformers
arXiv: 2602.00398 | 기관: Apple | ⬆️ 1 🤖 GLM추천 | 📄 HTML 태그:
memoryllmtransformerffninterpretabilitymodel-efficiencyneural-memoryplug-and-playllm-architecture사전 지식: Transformer Architecture, Self-Attention Mechanism, Feed-Forward Network (FFN), Token Embeddings, Residual Stream (잔차 연결)

한 줄 요약
트랜스포머의 가장 무겁고 난해한 부분인 FFN(순방향 신경망)을 해석 가능한 사전(Dictionary) 형태로 분리하여, 모델의 메모리 사용량과 연산 비용을 획기적으로 줄이면서도 성능을 유지하는 새로운 접근법을 제시했기 때문입니다.
💡 핵심 아이디어
기존의 LLM(대규모 언어 모델)에서 FFN은 문맥에 따라 계속 달라지는 복잡한 계산기 역할을 했습니다. 이 논문은 FFN을 **‘문맥과 상관없이 미리 정해진 답을 찾아보는 사전(Neural Dictionary)‘**으로 바꾸었습니다. 즉, 단어가 들어오면 그 단어에 해당하는 지식만 꺼내 쓰는 방식이라, 무거운 계산 없이도 가벼운 조회(Lookup)만으로 모델을 돌릴 수 있게 됩니다.
문제 정의
트랜스포머 구조에서 매개변수의 약 2/3를 차지하는 FFN(Self-Attention 제외 부분)은 정확히 어떻게 정보를 처리하는지 해석하기 어렵고, Self-Attention과 강하게 결합되어 있어 분석이 어렵습니다. 또한, FFN의 막대한 계산량 때문에 모델을 효율적으로 실행하는 데 한계가 있었습니다.
🔬 방법론 상세
- FFN의 문맥 독립적(Context-free) 분리: 기존 FFN은 이전 레이어의 출력(문맥이 포함된 정보)을 입력으로 받지만, MemoryLLM은 FFN을 토큰 임베딩(Token Embeddings, 단어 자체의 고정된 벡터) 만으로 학습시킵니다. 이를 통해 FFN이 문맥에 영향받지 않고 순수하게 단어 자체의 지식을 저장하도록 만듭니다.
- TKV (Token-Key-Value) 프레임워크: FFN을 $K$개의 키-값(Key-Value) 쌍을 가진 신경망 검색 메모리로 재정의합니다. 입력 토큰(Query)이 들어오면 FFN 내부의 특정 키(Key)를 활성화하여 그에 대응하는 값(Value)을 출력하는 구조로 해석합니다.
- ToL (Token-wise Lookup) 사전 계산 및 오프로딩: FFN이 문맥에 의존하지 않게 되었으므로, 모든 어휘(Vocabulary)에 대한 FFN의 출력을 미리 계산해 둘 수 있습니다. 이렇게 미리 계산된 값을 ToL(Token-wise Lookup) 테이블로 만들어 VRAM(그래픽 카드 메모리) 밖이나 디스크에 두고, 필요할 때만 가져와 쓰는 방식을 적용했습니다.
핵심 기법
가장 핵심은 **“FFN을 학습할 때 문맥 정보를 끊고 오직 ‘단어’만 보고 훈련시킨다”**는 것입니다. 이렇게 하면 FFN은 “사과”라는 단어가 들어오면 문맥이 뭐든 간에 항상 똑같은 ‘사과에 대한 지식’을 내뱉는 기계가 됩니다. 그래서 이것을 굳이 매번 계산할 필요 없이, 사전에 써둔 표를 보는 것(Lookup)으로 대체할 수 있는 것입니다.
📊 정량적 결과
주요 성과
- 메모리 효율성: FFN이 차지하는 파라미터(전체의 약 2/3)가 사전 계산되므로, 실제 추론 시 VRAM에 올라가는 활성 파라미터(Active Parameters)는 기존 대비 1/3 수준으로 감소했습니다.
- 성능 비교: 전체 파라미터 수 기준으로는 기존 모델(Baseline)보다 성능이 낮았지만, 실제 연산에 참여하는 활성 파라미터 수 기준으로는 기존 밀집(Dense) 모델보다 월등히 뛰어난 성능을 보였습니다.
🚀 기존 대비 개선점
- 해석 가능성(Interpretability) 향상: FFN이 어떤 단어를 입력받아 어떤 키를激活(activate)시키는지 분석하기 쉬워져, 모델 내부에서 의미가 비슷한 단어들이 어떻게 군집화(Clustering)되어 저장되는지 확인할 수 있습니다.
- 연산 비용 절감: 무거운 행렬 연산을 수행하는 FFN 대신 단순한 테이블 조회(Lookup)를 수행하므로, 연산 리소스를 크게 아낄 수 있습니다.
- 플러그 앤 플레이(Plug-n-Play): 분리된 메모리(FFN) 모듈을 필요에 따라 교체하거나 업데이트하기 쉬워집니다.
🎯 활용 분야
- 엣지 디바이스 및 온디바이스 AI: VRAM이 제한적인 스마트폰이나 태블릿에서 거대한 언어 모델을 구동할 때 메모리 사용량을 줄이는 데 활용 가능합니다.
- 모델 해석 및 디버깅 연구: 모델이 특정 단어를 처리할 때 어떤 지식을 참고하는지 명확히 알고 싶은 연구 분야에 적합합니다.
- 지검(Retrieval) 기반 모델 최적화: 외부 지식 베이스를 검색하는 RAG 시스템에서 내부 FFN 메모리를 효율적으로 관리하는 데 응용할 수 있습니다.
한계 및 주의사항
- 문맥 의존성 상실: FFN이 문맥을 고려하지 않고 단어 임베딩만 보므로, 문맥에 따라 단어의 의미가 달라지는 다의어 처리나 복잡한 추론 능력에서는 기존 방식(Context-dependent FFN)보다 성능이 떨어질 수 있습니다.
-
- 성능 격차: 전체 파라미터 수를 동일하게 맞췄을 때 기존 최신 모델(Llama 등)보다 성능이 낮다는 점은 여전히 개선이 필요한 과제로 언급되었습니다.
📅 생성일: 2026-02-04 | 🤖 GLM-4.7