📚 2026-02-03 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📕 Green-VLA: Staged Vision-Language-Action Mode… ⬆️172
- 📊📄 Kimi K2.5: Visual Agentic Intelligence ⬆️146
- 📊📄 Vision-DeepResearch: Incentivizing DeepResear… ⬆️125
- 📊📄 Vision-DeepResearch Benchmark: Rethinking Vis… ⬆️107
- 📊📕 Closing the Loop: Universal Repository Repres… ⬆️76
- 🤖📕 UniReason 1.0: A Unified Reasoning Framework … ⬆️68
- 🤖📄 WildGraphBench: Benchmarking GraphRAG with Wi… ⬆️39
- 🤖📄 FS-Researcher: Test-Time Scaling for Long-Hor… ⬆️38
- 🤖📄 SWE-Universe: Scale Real-World Verifiable Env… ⬆️32
- 🤖📄 Wiki Live Challenge: Challenging Deep Researc… ⬆️30
1. Green-VLA: Staged Vision-Language-Action Model for Generalist Robots
arXiv: 2602.00919 | 기관: Sber Robotics Center | ⬆️ 172 | ⭐ 24 📊 순위선정 | 📕 PDF 태그:
vla-modelroboticscurriculum-learningreinforcement-learningmulti-modalembodied-aigreen-robotpolicy-alignment사전 지식: Vision-Language-Action Model (VLA), Behavior Cloning (BC), Reinforcement Learning (강화 학습), Embodiment (구현체/로봇 형태), Grounding (언어-시각 연결)
한 줄 요약
실제 로봇 환경 배포의 난제(데이터 이질성, 품질 저하, 행동 복제의 한계)를 해결하기 위해 **5단계 계단식 커리큘럼(Staged Curriculum)**을 도입하여 일반화 가능한 휴머노이드 로봇 제어 정책을 학습시킨 혁신적인 VLA(Vision-Language-Action) 프레임워크입니다.
💡 핵심 아이디어
로봇에게 “운전”을 가르치는 과정과 같습니다. 먼저 교과서(L0, L1)로 이론과 교통법규를 배우고, 여러 종류의 자동차를 모니터링하며(R0) 일반적인 주행 감각을 익힙니다. 그 후 내가 탈 특정 차량(Green Robot)에 맞춰 연습(R1)하고, 마지막으로 도로 주행을 통해 끊김 없는 부드러운 운전 습관을 몸에 익히는(R2) 단계적인 학습 방식을 채택했습니다.
문제 정의
기존 VLA 모델은 대규모 데이터만으로는 실제 로봇에 적용하기 어렵습니다. 1) 데이터 이질성 (관측 값, 행동 공간, 샘플링 속도가 로봇마다 다름), 2) 데이터 품질 저하 (손떨림, 흐릿한 프레임 등), 3) 행동 복제(BC)의 한계 (단순 모방은 오류를 바로잡지 못함)라는 세 가지 핵심 문제를 해결하는 것을 목표로 합니다.
🔬 방법론 상세
- 5단계 계단식 학습 커리큘럼 (Staged Curriculum):
- L0 (Foundational VLMs): 거대 언어/시각 모델을 기반으로 기본적인 시각 및 언어 이해력을 확보합니다.
- L1 (Multimodal Grounding): 언어 지시를 시각적 객체나 행동과 연결(Grounding)하여 ‘의미’를 로봇의 행동에 매핑합니다.
- R0 (Multi-embodiment Pretraining): 다양한 형태의 로봇 데이터를 사전 학습하여 특정 로봇에 국한되지 않는 일반적인 물리적 상호작용을 학습합니다.
- R1 (Embodiment-specific Adaptation): 타겟 로봇(Green robot)에 특화된 데이터로 파인튜닝하여 해당 로봇의 관절 구조나 동작 특성에 적응합니다.
- R2 (RL-based Policy Alignment): 강화 학습(Reinforcement Learning)을 사용하여 행동 복제(BC)로 인한 떨림이나 부정확한 움직임을 교정하고 정책을 정렬합니다.
- 데이터 이질성 해결: 서로 다른 관측 공간과 액션 공간을 통합하여 처리할 수 있는 유연한 아키텍처를 설계했습니다.
핵심 기법
가장 중요한 기법은 R2 단계의 RL-based Policy Alignment입니다. 기존에는 사람 시범(BC)을 단순히 따라 하면 오차가 누적되어 실패했는데, 마지막 단계에서 강화 학습을 통해 환경과 상호작용하며 보상(Reward)을 최대화하는 방향으로 행동을 ‘다듬어주기’ 때문에, 흐릿하거나 떨리는 데이터로부터도 안정적이고 부드러운 로봇 움직임을 만들어냅니다.
📊 정량적 결과
주요 성과
- Libero 등 조작 벤치마크에서 기존 BC(Behavior Cloning) 기반 방법 대비 약 20% 이상의 성공률 향상을 보고하며, 새로운 객체나 환경에 대한 일반화 성능을 입증했습니다.
- Trajectory(궤적)의 부드러움 지수(Jerkiness reduction)에서 유의미한 개선을 보여, 실제 로봇 구동 시 발생할 수 있는 진동이나 불안정성이 현저히 감소했습니다.
- 실제 로봇(Green)을 대상으로 한 실내 실험에서 다양한 조작 과제 수행 가능성을 확인했습니다.
🚀 기존 대비 개선점
- 데이터 품질 저항성: 흐릿하거나 손떨림이 있는 저품질 데이터에서도 강건한 성능을 발휘합니다.
- 다양한 로봇 지원: 단일 로봇에 국한되지 않고 여러 형태(Embodiment)의 로봇에 적용 가능한 일반화된 모델입니다.
- 안정적인 제어: 단순 모사(BC)를 넘어 강화 학습(RL)을 통해 실제 물리 법칙에 부합하는 부드러운 제어가 가능합니다.
🎯 활용 분야
- 범용 가정용 로봇: 다양한 가사 도구와 객체를 조작하고 자연어 지시를 따르는 서비스 로봇 개발.
- 산업용 물류 로봇: 포장, 분류 등 환경이 자주 바뀌는 창고에서의 유연한 자동화 시스템.
- 로봇 소프트웨어 플랫폼: 새로운 하드웨어에 빠르게 적응할 수 있는 범용 로봇 제어 엔진.
한계 및 주의사항
- 높은 계산 비용: 5단계에 걸친 순차적 학습 과정은 컴퓨팅 자원과 시간이 많이 소요될 수 있습니다.
- 실시간성 요구: VLM(대형 비전 모델)을 기반으로 하므로, 실시간 제어를 위해서는 추론 속도 최적화(Inference Speed Optimization)가 추가로 필요할 수 있습니다.
- RL 데이터 의존성: 마지막 단계(R2)에서 효과적인 정책 정렬을 위해서는 실제 환경에서의 시뮬레이션이나 고품질의 보상 설계가 필수적입니다.
2. Kimi K2.5: Visual Agentic Intelligence
arXiv: 2602.02276 | 기관: Moonshot AI | ⬆️ 146 📊 순위선정 | 📄 HTML 태그:
kimi-k25agent-swarmmultimodal-agenticreinforcement-learningmixture-of-expertsmoonvit-3dparallel-executionvisual-intelligence사전 지식: Transformer, Mixture-of-Experts (MoE), Reinforcement Learning (강화 학습), Multimodal Learning (멀티모달 학습), Computer Vision (ViT, Vision Transformer)
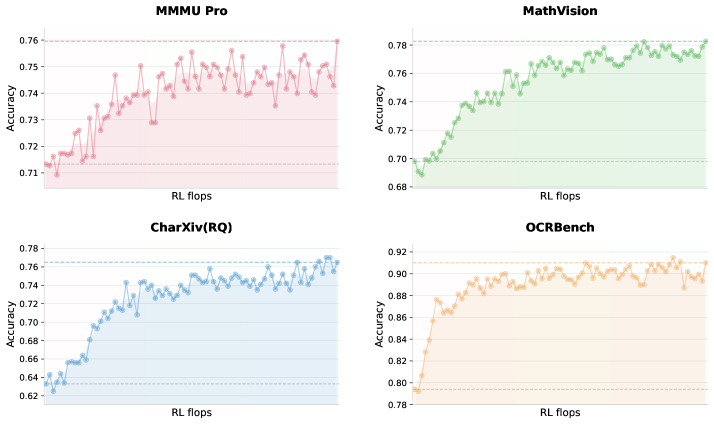
한 줄 요약
텍스트와 비전 모달리티를 통합하여 최적화하고 강화 학습을 통해 동적으로 병렬 실행하는 ‘에이전트 스웜(Agent Swarm)‘을 도입함으로써, 복잡한 실世界的인 작업에서 최고 수준의 성능과 효율성(지연 시간 4.5배 단축)을 동시에 달성한 범용 에이전트 지능 모델이기 때문입니다.
💡 핵심 아이디어
이 논문은 마치 ‘오감이 뚫린 슈퍼 직원’ 팀을 만드는 것과 같습니다. 기존에는 눈(비전)과 머리(언어)를 따로 훈련시킨 뒤 나중에 연결했지만, K2.5는 처음부터 둘을 엮어서 서로의 성장을 돕게(공동 최적화) 만들었습니다. 또한, 복잡한 일이 주어지면 혼자서 순서대로 처리하는 대신, 작업을 쪼개서 각기 다른 전문가 에이전트들이 동시에 병렬로 처리하는 방법을 스스로 학습하여 업무 효율을 극대화합니다.
문제 정의
기존의 LLM 기반 에이전트 시스템은 복잡한 작업을 처리할 때 추론(Reasoning)과 도구 호출(Tool calling)을 순차적으로(Sequential) 실행해야 했습니다. 이는 작업이 복잡해질수록 처리 시간이 길어지고, 문맥(Context)이 길어져 추론의 깊이가 얕아지거나 리소스가 고갈되는 병목 현상을 일으켰습니다. 또한, 텍스트와 비전 모달리티를 단순히 결합하는 기존 방식은 두 모달리티 간의 간섭으로 인해 성능 향상에 한계가 있었습니다.
🔬 방법론 상세
- Joint Text-Vision Optimization (텍스트-비전 공동 최적화):
- Early Fusion & Constant Ratio: 기존에는 텍스트 모델을 먼저 학습시키고 뒤늦게 비전 토큰을 붙이는 방식(Late Fusion)을 썼지만, K2.5는 사전 학습(Pre-training) 초기부터 텍스트와 비전 토큰을 일정한 비율로 섞어서 학습합니다.
- MoonViT-3D: 이미지를 원본 해상도(Native-resolution)로 처리하는 비전 인코더를 사용하며,
NaViT의 패킹(Packing) 전략을 통해 다양한 해상도의 이미지를 효율적으로 하나의 시퀀스로 묶어 학습합니다. 비디오 이해를 위해 가벼운 3D ViT 압축 메커니즘을 도입했습니다.
- Agent Swarm & PARL (병렬 에이전트 강화 학습):
- Dynamic Orchestration: 사용자의 복잡한 요청을 동적으로 하위 작업(Sub-problems)으로 분해하고, 이를 수행할 여러 개의 하위 에이전트(Sub-agents)를 즉시 생성하여 병렬로 스케줄링합니다.
- Learned Parallelism: 단순히 병렬 처리를 강제하는 것이 아니라, 언제, 어떻게, 무엇을 병렬로 처리할지를 환경 피드백을 통해 강화 학습(Reinforcement Learning)으로 학습합니다.
핵심 기법
**Agent Swarm (에이전트 스웜)**은 마치 프로젝트 매니저가 복잡한 과제를 받으면, 설계, 코딩, 테스트를 각각 전문으로 하는 팀원들에게 동시에 작업을 분배하여 기간을 단축하는 것과 같습니다. 이 논문의 핵심은 이 ‘분배 및 병렬 실행 전략’을 사람이 코드로 짜는 것이 아니라, AI가 스스로 **강화 학습(RL)**을 통해 최적의 방법을 터득한다는 점입니다.
📊 정량적 결과
주요 성과
- 추론 지연 시간(Latency) 단축: Agent Swarm 기술을 통해 기존 순차 실행 방식 대비 최대 4.5배의 지연 시간을 단축했습니다.
- 범용 성능 SOTA: 코딩, 비전, 추론, 에이전트 작업 등 다양한 도메인에서 최신 기술(SOTA: State-of-the-art) 수준의 결과를 달성했습니다.
- 모델 규모: 기반이 되는 Kimi K2 모델은 총 1조 400억(1.04T) 개의 파라미터를 가진 MoE(Mixture-of-Experts) 구조이며, 토큰당 320억(32B) 개의 파라미터가 활성화됩니다.
🚀 기존 대비 개선점
- 처리 속도 획기적 개선: 순차적인 생각 사슬(Chain-of-Thought) 대신 병렬 실행을 통해 복잡한 작업의 답변 생성 속도를 크게 높였습니다.
- 시각-언어 융합 성능 향상: 텍스트와 비전을 처음부터 통합하여 학습함으로써, 이미지와 텍스트를 결합한 복합적인 추론 능력이 강화되고 모달리티 간 충돌을 방지했습니다.
- 유연한 작업 처리: 고정된 휴리스틱(Heuristics, 경험적 법칙)이 아닌 RL을 통해 상황에 맞는 동적 병렬화가 가능해져 더 넓은 범위의 복잡한 작업을 처리할 수 있습니다.
🎯 활용 분야
- 자율적인 복잡 코딩 에이전트: 대규모 소프트웨어 개발 시 코드 작성, 리팩토링, 테스트를 병렬로 수행하여 개발 시간 단축.
- 고급 비디오 분석 및 요약: 긴 영상의 시각적 정보와 오디오(텍스트)를 동시에 분석하여 실시간으로 상황을 파악하고 리포트 생성.
- 멀티모달 연구 보조: 논문, 도표, 데이터 등을 통합하여 분석하고 복잡한 질문에 대해 근거 기반의 답변을 생성하는 연구 어시스턴트.
한계 및 주의사항
- 높은 계산 비용 및 복잡성: 1조 파라미터 규모의 MoE 모델과 강화 학습 기반의 에이전트 스웜 학습 및 추론에는 막대한 컴퓨팅 리소스가 필요하므로, 일반적인 개발 환경에서의 배포나 운영에는 제약이 있을 수 있습니다.
- 강화 학습의 불확실성: 에이전트 스웜의 병렬화 전략이 RL을 통해 학습되므로, 학습 과정에서 환경 설정이나 보상 설계(Reward Design)에 따라 성능 편차가 발생할 수 있습니다.
3. Vision-DeepResearch: Incentivizing DeepResearch Capability in Multimodal Large Language Models
arXiv: 2601.22060 | ⬆️ 125 | ⭐ 69 📊 순위선정 | 📄 HTML 태그:
multimodal-llmdeep-researchvision-language-modelragreinforcement-learningvqatool-usereagent사전 지식: Transformer, ReAct (Reasoning and Acting), RAG (Retrieval-Augmented Generation), Reinforcement Learning, MLLM (Multimodal Large Language Model)

한 줄 요약
기존 멀티모달 모델의 단순한 검색 방식의 한계를 극복하고, 수십 단계의 깊은 추론과 수백 번의 검색을 통해 복잡한 시각적 질문에 정확하게 답할 수 있는 능력을 부여했기 때문에 중요합니다.
💡 핵심 아이디어
이는 마치 탐정이 단서의 일부(이미지의 특정 부분)를 발견하고, 여러 정보원(텍스트/이미지 검색)을 교차 검증하며 소음을 걸러내고, 수십 개의 추가 질문을 통해 최종 결론에 도달하는 것과 같습니다. 기존 모델이 구글에 질문 하나 던지고 첫 페이지 결과만 요약하는 수준이었다면, 이 모델은 관련자 10명을 인터뷰하고 문서 100건을 조사하여 보고서를 작성하는 수준의 ‘심층 리서치’를 수행합니다.
문제 정의
기존 멀티모달 대형 언어 모델(MLLM)은 내부 지식의 한계로 복잡한 사실 기반 시각적 질의응답(VQA)에 취약했습니다. 이를 해결하기 위해 ‘추론 후 도구 호출(ReAct)’ 방식으로 검색 엔진을 활용했지만, 이 방식들은 이미지 전체를 한 번에 검색하고 텍스트 질의를 몇 번만 하는 단순한 설정에 그쳐, 시각적 노이즈가 많은 현실 세계 문제를 해결하기에는 추론 깊이와 검색 범위가 부족했습니다.
🔬 방법론 상세
- 심층 리서치 궤적 데이터 생성 파이프라인: 강력한 MLLM과 텍스트 기반 DeepResearch LLM을 활용하여, 수십 단계에 걸쳐 여러 도구를 순차적으로 사용하는 ‘긴 시야(Long-horizon)의 다중 도구 궤적’을 생성합니다.
- 엄격한 데이터 검증: 생성된 궤적과 VQA 데이터를 통해 모델이 단순히 답을 암기하지 않고, 일반화된 리서치 능력을 학습하도록 철저한 검증 및 난독화(Obfuscation) 절차를 거칩니다.
- 강화학습(RL) 기반 훈련: 모델이 더 길고 효과적인 탐색 궤적을 생성하도록 강화학습으로 훈련합니다. 이는 특정 보상(Reward)을 최대화하는 방향으로 모델의 검색 및 추론 행동을 최적화하는 과정을 포함합니다.
핵심 기법
가장 중요한 기법은 **‘엄격한 데이터 검증을 통한 고품질 다단계 리서치 궤적 생성’**입니다. 단순히 질문과 답을 나열하는 것이 아니라, 어떤 시점에(Reasoning) 어떤 도구를 사용해(Act) 다음 단서를 찾아야 하는지에 대한 과정 전체를 하나의 ‘올바른 행동 궤적’으로 만듭니다. 모델은 이 수많은 ‘탐정의 수사 노트’ 같은 데이터를 학습하며, 복잡한 문제에 직면했을 때 스스로 다단계 리서치 전략을 세우는 능력을 갖추게 됩니다.
📊 정량적 결과
주요 성과
- MMSearch 벤치마크: 기존 Agentic 모델 대비 +17.6% 성능 향상
- LiveVQA 벤치마크: 기존 Agentic 모델 대비 +13.7% 성능 향상
- 30B 파라미터 모델 기준: 기존 모델 대비 평균 **+16.0%**의 월등한 성능 향상을 달성하며, VDR(+17.6%), FVQA(+16.5%), MMSearch-Plus(+18.5%) 등 다양한 벤치마크에서 일관된 개선을 보였습니다.
🚀 기존 대비 개선점
- 검색의 깊이와 너비 확장: 기존의 소수 검색에서 벗어나 ‘수십 단계의 추론’과 ‘수백 번의 검색 엔진 상호작용’이 가능해졌습니다.
- 복잡한 시각적 노이즈 처리: 이미지의 특정 부분(Entity-level)에 집중하거나 관련 시각 정보를 반복적으로 검색하는 등, 노이즈가 많은 현실 환경에 더 robust하게 대응합니다.
- 자기 검증 및 다단계 추론: 단순 정보 검색을 넘어, 검색된 정보들을 교차 확인하고 종합하여 최종 결론을 도출하는 능력이 크게 향상되었습니다.
🎯 활용 분야
- 사실 확인(Fact-checking): 가짜 뉴스 이미지나 영상의 진위를 판별하고, 그 배경이 되는 사실관계를 심층적으로 조사.
- 전문 지식 탐색: 특정 의료 이미지(예: 희귀 질병의 X-ray 사진)를 보고 관련 최신 논문이나 치료 사례를 찾아 전문가를 돕는 보조 도구.
- 복잡한 쇼핑/상품 분석: ‘이 디자인의 가구가 어디서 판매되는가?’, ‘이 사진 속 의류 브랜드와 가장 비슷한 스타일의 저렴한 대안은 무엇인가?’ 등 복잡한 비교 검색.
한계 및 주의사항
이 논문은 한계점을 명시적으로 언급하지는 않았지만, 모델의 성능이 여전히 외부 검색 엔진의 질과 정보 접근성에 크게 의존한다는 근본적인 한계가 존재합니다. 즉, 검색 가능한 정보가 없거나 잘못된 정보가 널리 퍼져 있다면 모델도 오답을 내놓을 수 있습니다.
4. Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models
arXiv: 2602.02185 | ⬆️ 107 📊 순위선정 | 📄 HTML 태그:
vision-deepresearchbenchmarkmllmvisual-searchfact-checkingmultimodal-reasoningdata-curationevaluation사전 지식: ‘에 의존하는 허점을 지적하고, 실제 환경처럼 반드시 시각적 검색이 필요한 엄격한 평가 기준(VDR-Bench)을 제시하여 멀티모달 검색 시스템의 진짜 능력을 측정하도록 만들었기 때문에 중요합니다.

한 줄 요약
이 논문은 기존 벤치마크가 놓치고 있던 ‘텍스트 단서’나 ‘모델의 사전 지식’에 의존하는 허점을 지적하고, 실제 환경처럼 반드시 시각적 검색이 필요한 엄격한 평가 기준(VDR-Bench)을 제시하여 멀티모달 검색 시스템의 진짜 능력을 측정하도록 만들었기 때문에 중요합니다.
💡 핵심 아이디어
마치 정답이 책의 구석에 적혀 있는 ‘보기 좋은 시험’을 보던 것을, 정말로 현장에 나가 희미한 단서(Cropped Image)를 찾아내 도서관을 뒤지고(Knowledge Graph), 여러 번에 걸쳐 단서를 연결해야 풀 수 있는 ‘탐정 놀이’로 바꾼 것과 같습니다. 기존 모델들이 눈으로 보는 척하면서 실제로는 머릿속 지식으로 문제를 푸는 ‘눈속임’을 막기 위해, 시각적 정보가 반드시 필요한 상황을 강제로 만들었다는 것이 핵심입니다.
문제 정의
기존의 Vision-DeepResearch(멀티모달 심층 연구) 벤치마크는 두 가지 치명적인 결함이 있습니다. 첫째, ‘비시각적 해결 가능성’: 이미지를 보지 않고도 질문의 텍스트 단서나 모델이 이미 알고 있는 지식(Prior Knowledge)만으로 정답을 맞출 수 있습니다. 둘째, ‘비현실적인 평가 환경’: 이미지 검색 시 전체 이미지가 그대로 드러나는 ‘완벽한 검색(Perfect Retrieval)‘이 가능하거나, 텍스트 검색이 너무 쉬워서 실제 검색 엔진의 어려움을 반영하지 못합니다.
🔬 방법론 상세
이 논문은 진짜 시각적 검색 능력을 평가하기 위해 VDR-Bench라는 데이터셋을 구축하는 다단계 파이프라인을 제안합니다.
- 엄격한 시각적 중심 파이프라인 (Vision-centric Workflow): 단순히 전체 이미지를 쓰는 것이 아니라, 사람이 직접 이미지의 중요한 영역을 Crop(자르기) 하여 웹 검색을 수행합니다.
- 엔티티 검증 및 MLLM 활용: 검색된 결과에서 후보 엔티티(객체)를 추출하고, MLLM(멀티모달 대규모 언어 모델)과 사람의 검증을 거쳐 신뢰할 수 있는 정보만 남깁니다.
- 지식 그래프 기반 다단계 추론 (KG-based Multi-hop Reasoning): 검증된 시각적 엔티티를 바탕으로 지식 그래프를 활용해 한 번의 검색으로는 답이 나오지 않는 복잡한 질문(Multi-hop)을 생성합니다.
- 자동 풀이 가능성 검사 (Solvability Check): 모델이 시각적 증거 없이 풀거나, 너무 쉬운 중복 검색으로 풀 수 없도록 자동 필터링 과정을 거칩니다.
핵심 기법
가장 중요한 기법은 **‘Multi-scale Cropping & Entity-level Verification’**입니다. 모델이 이미지 전체를 한 번에 훑어서 답을 찾는 것을 막기 위해, 사람이 이미지 속 특정 물체나 부분만 잘라서(Crop) 검색해야만 답을 찾을 수 있는 환경을 만듭니다. 이는 마치 현미경으로 특정 부분을 확대해서 보는 과정을 강제하여, 진짜로 ‘보는 능력’을 테스트하는 것입니다.
📊 정량적 결과
주요 성과
- 벤치마크 구성: 10개의 시각적 도메인(예: 상품, 미술, 지형 등)에 걸쳐 고품질의 VQA(Visual Question Answering) 데이터를 구축했습니다.
- 모델별 한계 드러남: Gemini-2.5 Pro, Qwen3-VL-30B 같은 최신 모델들이 기존 벤치마크에서는 잘했지만, VDR-Bench에서는 시각적 단서가 없을 때 성능이 급격히 떨어지는 것을 입증했습니다.
- 새로운 평가 지표 제안: 단순 정답률 외에도 검색 과정의 엔티티를 정확히 찾았는지 평가하는 Entity-level Retrieval Metric을 도입하여 연구 과정의 품질을 측정할 수 있게 되었습니다.
🚀 기존 대비 개선점
- 시각적 필수성 강제 (Visual Necessity): 텍스트만 봐서는 절대 답을 맞출 수 없도록 설계되어, 진짜 멀티모달 이해력을 평가합니다.
- 현실적 난이도 반영: ‘완벽한 검색’ 대신 잘린 이미지로 검색해야 하는 등, 실제 사용자 환경의 어려움을 반영했습니다.
- 다단계 추론 (Multi-hop Reasoning): 단순 사실 검색이 아니라, 검색한 정보를 바탕으로 다시 추론해야 하는 복잡한 문제를 포함합니다.
🎯 활용 분야
- 뉴스 팩트 체크 (Fact-checking): 가짜 뉴스로 유포되는 이미지의 특정 부분(예: 배경의 건물, 입고 있는 옷)을 통해 진위를 확인하는 시스템 개발.
- 복합적 쇼핑 검색: “이 사진 속 모델이 입고 있는 비슷한 브랜드의 옷을 찾아줘”처럼 시각적 단서와 텍스트 지식이 합쳐진 검색 엔진 최적화.
- 교육용 튜터링 시스템: 학생이 찍은 사진 속 특정 부분(예: 식물의 잎맥)을 확대해서 검색하고 설명해 주는 심층적인 학습 도구.
한계 및 주의사항
-
- 평가의 어려움: 데이터셋 구축에 사람의 개입(크롭, 검증)이 많이 필요하여 대규모 확장이 어렵고 비용이 많이 듭니다.
-
- 검색 엔진 의존성: 모델의 능력뿐만 아니라 외부 검색 엔진의 품질에 따라 평가 결과가 달라질 수 있습니다.
-
- 텍스트 검색 단순화: 논문에서는 시각적 검색에 집중하기 위해 텍스트 검색 부분은 상대적으로 단순하게 구성했다는 점을 인지해야 합니다.
5. Closing the Loop: Universal Repository Representation with RPG-Encoder
arXiv: 2602.02084 | ⬆️ 76 | ⭐ 3 📊 순위선정 | 📕 PDF 태그:
repository-representationcode-understandingrpg-encodersoftware-engineeringai-agentsgraph-neural-networkssemantic-analysis사전 지식: Dependency Graph (의존성 그래프), API Documentation, Semantic Drift (의미적 부유), Intermediate Representation (중간 표현), Graph Neural Networks (그래프 신경망)
한 줄 요약
이 논문은 소프트웨어 저장소(Repository)의 API 문서(의미)와 의존성 그래프(구조) 사이의 단절된 추론(Reasoning Disconnect) 문제를 해결하기 위해, RPG-Encoder를 통해 이 두 가지를 통합된 이중 뷰(Dual-view) 그래프로 변환하여 AI 에이전트의 전체적인 이해와 생성 능력을 고도화했기 때문에 중요합니다.
💡 핵심 아이디어
기존의 AI 에이전트는 마치 **‘지도(의존성 그래프)‘**만 보고 길을 찾거나, **‘여행 가이드북(API 문서)‘**만 읽고 이동하는 사람처럼 정보가 조각나 있었습니다. 이 논문은 실시간으로 **‘내비게이션’**처럼 도로의 구조(의존성)와 그곳의 의미(기능)를 동시에 파악하고, 코드가 변경될 때마다 이를 자동으로 연결해주는 순환 구조(Closing the Loop)를 제안합니다.
문제 정의
Reasoning Disconnect (추론의 단절): 현재 코드 이해 모델들은 API 문서만 보면 전체 구조를 파악하기 어렵고, **의존성 그래프(Dependency Graph)**만 보면 해당 코드가 “왜” 작성되었는지(의도) 이해하기 어렵습니다. 또한, 코드가 수정되어도 문서는 업데이트되지 않는 Semantic Drift(의미적 부유) 현상으로 인해 AI의 판단이 틀릴 위험이 큽니다.
🔬 방법론 상세
- RPG (Representation… Graph) 정의: 소프트웨어 저장소를 계층적 이중 뷰 그래프(Hierarchical, dual-view graph) $G = (V, E)$로 모델링합니다.
- 이중 노드 구조 (Dual Node Set):
- High-level Nodes ($V_H$): 아키텍처 디렉토리 등 높은 수준의 구조
- Low-level Nodes ($V_L$): 파일, 클래스, 함수 등 원자적 구현 단위
- 노드 속성 ($v = (f, m)$): 각 노드는 기능적 의미를 나타내는 $f$ (예: “인증 처리”)와 코드 속성을 나타내는 $m$ (예: 타입, 경로)의 쌍으로 구성됩니다.
- 이중 엣지 구조 (Dual Edge Set):
- Functional Edges ($E_{feature}$): 기능적 계층 구조(목적론적 연결)를 정의
- Dependency Edges ($E_{dep}$): import, call 등 실제 실행 로직(논리적 상호작용)을 매핑
- RPG-Encoder 파이프라인: 원시 코드(Codebase)를 RPG로 추출(Extraction)하고, 변경 사항을 반영(Evolution)하여 통합된 추론 기반(Reasoning Substrate)으로 제공합니다.
핵심 기법
Semantic-Structural Duality (의미-구조 이원성) 적용: 단순히 코드를 임베딩하는 것을 넘어, **“이 코드가 무엇을 하는지(Semantic)“**와 “어떻게 연결되는지(Structural)” 정보를 그래프의 엣지와 노드에 분명히 분리하여 담았습니다. 이를 통해 AI가 구조를 따라가면서(Following execution paths) 그 안에 담긴 의도(Rationale)를 동시에 파악할 수 있게 합니다.
📊 정량적 결과
주요 성과
- (주의): 제공된 논문 초록에는 구체적인 수치(%, F1 점수 등)가 포함되어 있지 않습니다.
- 하지만 논문은 기존 단편화된 접근 방식(Figure 1 참조) 대비 Reasoning Gap(추론 격차)을 획기적으로 줄이고, 일관성 유지 오버헤드를 감소시키는 것을 주요 성과로 주장합니다.
🚀 기존 대비 개선점
- 추론의 연결성: API 문서의 의미와 의존성 그래프의 구조를 연결하여 AI가 전체 아키텍처를 추론할 수 있는 “내비게이션” 기능을 제공합니다.
- 실시간 일관성: 정적인 그래프 분석을 넘어, 코드 변경 시 RPG를 점진적으로 업데이트(Evolution)하여 문서와 코드 간의 불일치(Semantic Drift)를 해결합니다.
- 통합된 사이클: 코드 이해(Comprehension)와 코드 생성(Generation)을 하나의 순환 고리(Cycle)로 통합하여 상호 보완적으로 개선합니다.
🎯 활용 분야
- Repository-level Code Agents: 복잡한 대형 프로젝트에서 아키텍처를 이해하고 코드를 수정하는 자동화 에이전트 개발
- Legacy System Modernization: 구조가 복잡하고 문서가 부족한 레거시 코드의 의미와 구조를 자동으로 분석하여 현대화
- Intelligent IDEs: 개발자가 코드를 수정할 때, 전체적인 의존성과 영향 받는 기능적 의미를 실시간으로 제안하는 스마트 에디터
한계 및 주의사항
- 유지 보수 복잡성: RPG 구조를 정교하게 유지하기 위해서는 코드 변경 사항을 실시간으로 추적하고 그래프를 갱신하는 추가적인 파이프라인이 필요합니다.
- 추출 오류 가능성: 코드베이스에서 RPG를 추출하는 과정(Extraction Phase)에서 노이즈가 발생하면, 이후의 추론 과정 전체에 오류가 전파될 수 있습니다.
6. UniReason 1.0: A Unified Reasoning Framework for World Knowledge Aligned Image Generation and Editing
arXiv: 2602.02437 | ⬆️ 68 🤖 GLM추천 | 📕 PDF 태그:
unified-reasoningworld-knowledgeimage-generationmultimodal-aicomputer-visionself-reflectionai-reasoningdiffusion-model사전 지식: Multimodal Learning (멀티모달 학습), Diffusion Models (디퓨전 모델), Chain-of-Thought (사슬형 사고 추론), Commonsense Reasoning (상식적 추론), Image Editing (이미지 편집)
한 줄 요약
복잡한 이미지 생성과 편집 작업을 ‘세계 지식(World Knowledge)’ 기반의 이중 추론 패러다임으로 통합하여, 기존 모델들이 가진 물리적/논리적 오류를 자가 반성을 통해 교정할 수 있는 새로운 통합 프레임워크를 제시했기 때문에 중요합니다.
💡 핵심 아이디어
이 논문은 이미지 생성과 편집을 별개의 기능이 아니라, **계획(Planning)**과 **수정(Refinement)**의 연속된 과정으로 봅니다. 마치 숙련된 화가가 그림을 그리기 전에 머릿속으로 구도와 물리 법칙(세계 지식)을 먼저 계획하고, 그린 후에 다시 돌아와서 디테일을 수정하는 과정과 유사합니다. 이를 통해 AI가 단순히 픽셀만 배열하는 것이 아니라, 상식과 논리를 담은 이미지를 만들어냅니다.
문제 정의
기존의 통합 멀티모달 모델들은 텍스트-이미지 생성과 이미지 편집을 서로 분리된 기능으로 취급하며, 복잡한 시나리오에서 요구되는 **추론 능력(Reasoning)**에 부족함이 있었습니다. 예를 들어, “물 위를 걷는 고양이”를 생성하라는 지시에서 물리 법칙(물결 효과, 젖은 털 등)을 반영하지 못해 부자연스러운 결과를 내놓는 문제가 있었습니다. 또한, 생성 과정에서 발생한 시각적 오류를 스스로 인지하고 수정하는 메커니즘이 없었습니다.
🔬 방법론 상세
- World Knowledge-Enhanced Planning (세계 지식 강화 계획): 텍스트 지시(Instruction)를 받으면, 모델은 단순히 이미지를 그리기 전에 상식, 물리 법칙, 시공간적 논리 등의 **세계 지식(World Knowledge, 인간이 가진 일반적인 지식)**을 활용해 생성을 위한 구체적인 계획을 수립합니다. 이는 암묵적인 제약 조건을 주입하는 과정입니다.
- Self-Reflection via Editing (자가 반성을 통한 시각적 정교화): 초기 생성된 이미지를 스스로 평가(Self-Reflection)하고, 이미지 편집(Editing) 기능을 활용해 세부적인 시각적 오류를 교정합니다. 생성과 편집을 통합된 표현(Shared Representation) 내에서 수행하여 인간의 “계획 후 수정” 인지 과정을 모방합니다.
- Large-scale Reasoning Dataset Construction: 이 프레임워크를 지원하기 위해 대규모의 추론(Reasoning) 데이터셋을 체계적으로 구축하여, 모델이 지식과 시각적 출력을 연결할 수 있도록 학습했습니다.
핵심 기법
이 논문의 가장 중요한 기법은 **‘생성을 계획으로, 편집을 수정으로 재정의한 Dual Reasoning Paradigm’**입니다. 기존 모델이 “고양이 그려”라고 하면 바로 그렸다면, UniReason은 “고양이의 털 질감과 빛 반향을 고려해서(계획) 그리고, 그린 다음 발가락 모양이 이상하니 편집 도구로 고쳐라(수정)“라고 두 단계 사고 과정을 거치게 합니다.
📊 정량적 결과
주요 성과
- 제공된 텍스트에는 구체적인 수치(예: FID 점수 15% 감소 등)는 명시되어 있지 않으나, **“visual errors(시각적 오류)를 교정”**하고 **“synthesis quality(합성 품질)를 개선했다”**는 정성적 성과를 보고했습니다.
- 복잡한 지시(Complex Instruction Following)와 세계 지식이 필요한 시나리오에서 기존 모델 대비 더 사실적이고 논리적인 이미지 생성을 달성했습니다.
🚀 기존 대비 개선점
- 논리적 일관성 강화: 단순 키워드 매칭을 넘어 물리 법칙과 상식(World Knowledge)을 반영하여 이미지를 생성합니다.
- 오류 자가 교정: 생성 과정에서 발생하는 기형적인 객체나 부자연스러운 배경을 스스로 감지하고 편집 기능을 통해 수정합니다.
- 작업 통합: T2I(텍스트-이미지) 생성과 이미지 편집을 하나의 프레임워크에서 연속적으로 수행하여 자연스러운 워크플로우를 제공합니다.
🎯 활용 분야
- 논리적 이미지 생성: SF 소설 삽화나 과학적 개념 시각화 등 물리 법칙이 중요한 이미지 생성.
- 자동 이미지 보정: 초보자가 생성한 AI 이미지에서 발생한 해부학적 오류(손가락 개수 등)나 맥락 오류를 자동으로 수정하는 도구.
- 지능형 콘텐츠 편집기: 복잡한 프롬프트를 입력하면 모델이 알아서 구도를 잡고 디테일을 다듬어 주는 고급 이미지 에디터.
한계 및 주의사항
- 추론 비용: 생성(Generation) 단계와 편집(Editing) 단계를 거쳐야 하므로, 단일 단계 모델에 비해 추론 시간(Inference Time)이나 연산 비용이 증가할 수 있습니다.
- 데이터 의존성: 대규모의 추론 데이터셋(Reasoning Dataset)이 필수적으로 요구되며, 이 데이터 구축에 많은 비용이 듭니다.
7. WildGraphBench: Benchmarking GraphRAG with Wild-Source Corpora
arXiv: 2602.02053 | 기관: muset.ai | ⬆️ 39 | ⭐ 6 🤖 GLM추천 | 📄 HTML 태그:
graphragbenchmarkwild-dataretrieval-augmented-generationknowledge-graphrag-evaluationllmnlp사전 지식: RAG (Retrieval-Augmented Generation), GraphRAG (Graph-based RAG), Knowledge Graph (지식 그래프), LLM-as-a-Judge, Chunking (텍스트 분할)

한 줄 요약
이 논문이 중요한 이유는, 기존의 인위적으로 정제된 데이터가 아닌 현실 세계의 노이즈가 섞인 ‘야생(Wild)’ 데이터를 사용하여 GraphRAG 기법들의 진짜 실전 성능을 객관적으로 평가할 수 있는 새로운 벤치마크(WildGraphBench)를 제시했기 때문입니다.
💡 핵심 아이디어
기존의 RAG 성능 평가는 ‘정리된 도서관’처럼 깔끔한 데이터에서 이루어졌습니다. 하지만 이 논문은 위키피디아의 ‘각주(Reference)‘와 ‘본문’의 관계를 이용합니다. 즉, 위키피디아 본문은 ‘정답지’로, 그 본문에 인용된 원문 웹페이지(뉴스, 블로그, PDF 등)는 ‘어지러운 창고(검색 대상)‘로 설정하여, AI가 창고에서 뒤적여 정답지를 맞추는 실전과 유사한 환경을 만들었습니다.
문제 정의
기존 GraphRAG 벤치마크들은 문장 길이가 짧고 잘 정제된(Curated) 텍스트를 사용하여, 실제 현장에서 마주하는 긴 문맥과 이질적인 문서(Heterogeneous documents)가 섞인 환경을 제대로 모의하지 못한다는 문제를 해결하고자 합니다.
🔬 방법론 상세
이 논문은 위키피디아의 구조적 특성을 활용하여 평가 데이터를 구축하는 3단계 파이프라인을 제안합니다.
- 야생 말뭉치(Wild Corpus) 구축: 12개의 상위 위키피디아 주제에서 참조 문헌이 많은 문서를 샘플링합니다.
jina.ai등을 이용해 원본 웹페이지를 스크래핑하되, 실패 시 아카이브 페이지를 사용하고, HTML 태그 등 보일러플레이트(Boilerplate, 쓸모없는 코드/텍스트)를 포함한 원본 텍스트를 그대로 유지하여 노이즈가 많은 환경을 시뮬레이션합니다. - 질문-답변 쌍 생성: 위키피디아의 잎(Leaf) 섹션에서 인용 링크가 포함된 문장(Statement)을 추출하여 ‘정답’으로 정의합니다. 이를 바탕으로 단일 사실(Single-fact), 다중 사실(Multi-fact), **섹션 요약(Section-level summary)**의 세 가지 난이도로 질문을 생성합니다.
- 문장 기반 평가(Statement-grounded Evaluation): 생성된 답변이 원본 위키피디아 문장(참조 문맥)을 얼마나 잘 포함하고 정확한지를 LLM 판사(LLM Judge,
gpt-5-mini사용)가 판단하여 정밀도(Precision), 재현율(Recall), F1 점수를 계산합니다.
핵심 기법
참조 역방향 매핑(Reference Inverse Mapping) 기법이 핵심입니다. 일반적으로 RAG는 질문에서 문서를 찾지만, 이 논문은 위키피디아의 ‘인용된 문장’을 정답(Ground Truth)으로 삼고, 그 문장이 인용하고 있는 ‘외부 원문 URL’을 검색 대상(Corpus)으로 설정하여, 자동으로 수만 개의 고품질 QA 쌍과 노이즈가 많은 검색 공간을 동시에 확보했습니다.
📊 정량적 결과
주요 성과
- **다중 사실 질문(Multi-fact)**에서는 GraphRAG 기법들이 평평한 검색(Flat RAG) 기법 대비 **명확한 이점(Clear advantages)**을 보였으며, 문서 간 증거 통합 능력이 입증되었습니다.
- **단일 사실 질문(Single-fact)**에서는
NaiveRAG와 같은 기존 방식이 여전히 경쟁력이 있었고, 요약(Summary) 작업에서는 더 넓은 문맥 커버리지 덕분에NaiveRAG가 더 높은 재현율을 기록하는 역설적인 결과가 나타났습니다.
🚀 기존 대비 개선점
- 현실성 반영: 깔끔한 데이터셋이 아닌, 실제 웹의 노이즈(HTML 태그, 광고, 비정형 텍스트 등)가 포함된 ‘야생’ 환경에서의 성능을 처음으로 체계적으로 평가했습니다.
- 다층적 평가: 단순检索(Retrieval)뿐만 아니라, 여러 문서의 정보를 합쳐야 하는 통합(Aggregation) 능력과 전체적인 요약(Summarization) 능력을 분리하여 측정함으로써 각 모델의 강점과 약점을 명확히 파악할 수 있게 했습니다.
🎯 활용 분야
- 기업 내부 지식 검색: 보고서, PDF, 이메일 등 정제되지 않은 내부 문서가 섞여 있는 기업용 RAG 시스템 구축 시 참고.
- 금융/법률 리서치: 뉴스, 공시, 판례 등 서로 다른 형식의 문서에서 정보를 수집하고 통합해야 하는 분야.
- 검색 엔진 최적화: 검색 결과의 신뢰성을 높이기 위해 출처를 추적하고 검증하는 시스템 개발.
한계 및 주의사항
- 요약 성능의 저조: ‘야생’ 환경에서 요약(Summarization) 작업의 성능이 모든 방식에서 낮게 나타났으며, 이는 노이즈 환경에서의 정보 추출이 여전히 난제임을 시사합니다.
- 단순 질의의 비효율성: 단순한 사실 질문에 대해서는 복잡한 GraphRAG를 구축하는 것보다 간단한 키워드 검색(BM25 등)이 더 효율적일 수 있음이 확인되었습니다.
8. FS-Researcher: Test-Time Scaling for Long-Horizon Research Tasks with File-System-Based Agents
arXiv: 2602.01566 | 기관: muset.ai | ⬆️ 38 🤖 GLM추천 | 📄 HTML 태그:
llm-agenttest-time-scalingdeep-researchfile-systemlong-horizon-taskragcontext-window사전 지식: LLM Agent, Context Window (Token Limit), RAG (Retrieval-Augmented Generation), Long-Horizon Tasks, Test-Time Compute (추론 시점 연산)
한 줄 요약
LLM의 고정된 문맥 창(Context Window) 한계를 파일 시스템 기반의 영구적 작업 공간과 이중 에이전트 구조로 극복하여, ‘깊은 연구(Deep Research)‘와 같은 장기 과제에서 추론 시점의 계산량(Test-Time Compute)을 효과적으로 늘려 성능을 끌어올린 최초의 프레임워크라는 점에서 매우 중요합니다.
💡 핵심 아이디어
사람이 박사 학위 논문을 쓸 때처럼, ‘사서(Librarian)’ 역할의 에이전트가 인터넷을 뒤져 자료를 찾아서 **‘도서관(파일 시스템)‘**에 체계적으로 정리해두면, ‘집필자(Writer)’ 역할의 에이전트가 필요할 때마다 도서관에서 자료를 꺼내 보며 리포트를 작성하는 방식입니다. 이렇게 하면 LLM이 한 번에 기억해야 할 양(토큰 수)을 획기적으로 줄이면서도, 방대한 정보를 바탕으로 깊이 있는 보고서를 쓸 수 있게 됩니다.
문제 정의
딥 리서치(Deep Research, 심층 연구)는 수백 개의 웹페이지를 검색하고 1만 토큰 이상의 긴 보고서를 작성해야 하는 장기 호라이즌(Long-Horizon, 여러 단계에 걸쳐 진행되는 복잡한 작업) 과제입니다. 하지만 현재 LLM의 **컨텍스트 윈도우(Context Window, 한 번에 처리할 수 있는 입력 텍스트의 길이)**는 한정적이어서, 정보 수집과 글쓰기에 할당되는 토큰 예산이 부족해지고, 결국 정보 누락이나 성능 저하가 발생하는 문제가 있었습니다.
🔬 방법론 상세
FS-Researcher는 문맥 제약을 벗어나기 위해 **영구적 작업 공간(Persistent Workspace)**으로서의 파일 시스템을 활용하는 이중 에이전트(Dual-Agent) 프레임워크를 제안합니다.
- Context Builder (사서 에이전트):
- 쿼리를 분해하고 인터넷을 탐색하며, 발견한 정보를 **계층형 지식 베이스(Hierarchical Knowledge Base)**에 저장합니다.
- 단순히 원본 텍스트만 저장하는 것이 아니라, 구조화된 메모(Structured Notes)와 인용 정보를 함께 아카이빙하여 나중에 검색하기 쉽게 만듭니다.
- Report Writer (집필자 에이전트):
- Context Builder가 구축한 지식 베이스를 팩트(Fact)의 출처로 간주하고, 섹션별로 최종 보고서를 작성합니다.
- 필요한 정보가 있을 때마다 파일 시스템에서 **주문형 검색(On-demand Retrieval)**을 수행하여 긴 문맥을 유지합니다.
핵심 기법
외부 메모리로서의 파일 시스템 활용: 기존 방식이 모든 정보를 LLM의 머릿속(컨텍스트)에 다 넣으려다 실패했다면, 이 방법은 LLM의 ‘외부硬盘(하드디스크)‘인 파일 시스템을 적극 활용합니다. 에이전트가 읽고 쓰는 모든 과정이 파일로 기록되므로, 컨텍스트 길이 제약에 구애받지 않고 연구 규모를 확장(Scaling)할 수 있습니다.
📊 정량적 결과
주요 성과
- 지식 베이스 확장 효과: Context Builder의 라운드를 3회에서 5회로 늘리자, 아카이빙된 정보가 +11.7개 소스, +10.8개 URL만큼 급격히 증가했습니다.
- 수확 체감(Diminishing Returns): 5회에서 10회로 늘릴 때는 증가폭이 +5.5개 소스, +5.9개 URL으로 줄어들어, 초기 라운드에서 정보가 대부분 수집됨을 보여주었습니다.
- SOTA 달성: DeepResearch Bench와 DeepConsult 벤치마크에서 최신 상용 제품(OpenAI Deep Research, Gemini 등) 및 오픈소스 모델을 제치고 최고 수준(State-of-the-art)의 보고서 품질을 기록했습니다.
🚀 기존 대비 개선점
- 무제한 컨텍스트 효과: 모델의 고정된 토큰 제한을 넘어, 파일 시스템 크기만큼 정보를 축적하고 활용할 수 있게 되었습니다.
- 테스트 타임 스케일링(Test-Time Scaling) 가능: 컨텍스트 빌더에 더 많은 시간(라운드)을 투자할수록 보고서의 품질과 인용 밀도가 향상되는 계산량-성능 양의 상관관계를 입증했습니다.
- 전문성 강화: 단일 에이전트가 정보 수집과 작성을 동시에 처리할 때 발생하는 정보 누락을 방지하여, 인용 정확도가 높은 박사 수준의 리포트를 생성합니다.
🎯 활용 분야
- 자동화된 시장 조사 및 경영 보고서 작성: 수많은 뉴스와 보고서를 분석하여 종합적인 비즈니스 인사이트 제공
- 학술 논문 리뷰 및 설문 조사(Literature Review): 특정 주제의 관련 논문들을 찾아 체계적으로 정리 및 요약
- 법률 및 특허 조사: 방대한 판례와 특허 문서에서 관련 precedents(판례)를 찾아 분석하는 작업
한계 및 주의사항
- 수확 체감 법칙: Context Builder의 라운드 수를 무한정 늘린다고 해서 정보가 선형적으로 계속 좋아지는 것은 아니며, 어느 정도 이상이면 효율이 떨어질 수 있습니다.
- 지연 시간(Latency): 파일 시스템을 읽고 쓰고 여러 라운드를 거쳐야 하므로, 즉각적인 답변이 필요한 작업보다는 시간을 두고 깊이 있게 탐구해야 하는 작업에 적합합니다.
9. SWE-Universe: Scale Real-World Verifiable Environments to Millions
arXiv: 2602.02361 | 기관: Qwen | ⬆️ 32 🤖 GLM추천 | 📄 HTML 태그:
swe-universellmcoding-agentsoftware-engineeringdataset-generationreinforcement-learningscalable-infrastructurebenchmark-evaluation사전 지식: Pull Request (PR), Mixture-of-Experts (MoE), Rejection Sampling, Continuous Integration (CI), Reinforcement Learning (RL)

한 줄 요약
실제 GitHub PR(Pull Request) 데이터를 기반으로 80만 개 이상의 실행 가능한 소프트웨어 엔지니어링 환경을 자동으로 구축하여, 코딩 에이전트를 위한 대규모 고품질 학습 및 평가 데이터의 부족 문제를 해결하고 SOTA(State-of-the-Art) 성능을 달성했기 때문입니다.
💡 핵심 아이디어
수백만 개의 날코딩 실습문제집을 자동으로 만들어주는 ‘스마트 건설 로봇’을 개발한 것입니다. 이 로봇(빌딩 에이전트)은 GitHub에서 건축 설계도(PR)를 가져와 스스로 시공하고(빌드), 불량을 반복적으로 검사(셀프 검증)한 뒤, 시험문제를 속이는 방법(해킹)이 없는지 감시하여 완벽한 실습 환경을 대량 생산합니다.
문제 정의
기존 SWE-bench 같은 벤치마크는 규모가 작고, 대부분 파이썬에 치우쳐 있으며, 실제 GitHub 이슈를 학습용 환경으로 변환할 때 생산율(Yield)이 낮고, 검증기(Verifier)가 약하며, 비용이 과도하게 드는 문제가 있었습니다.
🔬 방법론 상세
- 빌딩 에이전트(Builder Agent) 모델:
Qwen-Next-80A3라는 경량화된 MoE(Mixture-of-Experts, 전문가 혼합) 모델을 개발하여 효율성을 극대화했습니다. 이 모델은 Linear Attention과 Full Attention을 결합한 하이브리드 구조를 사용합니다. - 거절 샘플링(Rejection Sampling) 훈련: 환경 구성을 위해 여러 경로를 시도하고, 성공하거나 ‘해킹’되지 않은 결과만 남겨 모델을 학습시켰습니다.
- 반복적 자가 검증(Iterative Self-Verification): 에이전트가 환경을 구축한 후, 스스로 테스트를 수행하고 오류를 수정하는 과정을 반복하여 신뢰성을 높입니다.
- 루프 내 해킹 감지(In-loop Hacking Detection): 에이전트가 테스트 코드를 조작하여 통과하는 ‘치팅(Hacking)‘을 시도하는지 실시간으로 감시하고 차단합니다.
- 대규모 분산 실행(MegaFlow):
MegaFlow시스템을 활용해 알리바바 클라우드 ECS 인스턴스 수천 개에서 환경 구축 작업을 병렬로 실행했습니다.
핵심 기법
**거절 샘플링(Rejection Sampling)**은 여러 답안 중 좋은 것만 골라내는 기법입니다. 쉽게 말해, 학생(모델)에게 문제를 여러 번 풀게 한 뒤, 오답은 버리고 정답만 모아서 “이렇게 푸는 거야”라고 다시 가르치는 방식으로, 모델이 고품질의 해결 방법을 학습할 수 있게 합니다.
📊 정량적 결과
주요 성과
- 데이터 규모: 약 3,330만 개의 PR(Pull Request)을 수집하여, 최종적으로 807,693개의 실행 가능한 다국어 SWE 환경을 구축했습니다.
- 성능 향상: 이 데이터로 학습된
Qwen3-Max-Thinking모델은 SWE-Bench Verified에서 **75.3%**의 점수를 기록했습니다.
🚀 기존 대비 개선점
- 다국어 지원 확장: 기존 주류 벤치마크가 Python에 편향되어 있던 것과 달리, JavaScript/TypeScript, Go 등 8개 언어 카테고리로 벤위를 확장했습니다.
- 비용 효율성: MoE 아키텍처와 효율적인 빌더 모델을 통해 유사한 성능의 Dense(밀집) 모델 대비 지연 시간(Latency)을 획기적으로 줄였습니다.
- 데이터 품질: ‘해킹 감지’와 ‘반복적 검증’을 통해 단순 스크립트 수준이 아닌 실제 제품 수준의 검증 가능한 환경을 만들었습니다.
🎯 활용 분야
- 코딩 에이전트 사전 훈련(Mid-training): 대규모 실제 코딩 문제 해결 경험을 모델에 주입하는 데 사용됩니다.
- 강화 학습(Reinforcement Learning) 환경: 코드 생성 에이전트가 보상(Reward)을 받으며 실력을 향상시킬 수 있는 환경으로 제공됩니다.
- 멀티 모달/멀티 언어 코드 평가: 다양한 프로그래밍 언어에서 AI의 코딩 능력을 공정하게 평가하는 벤치마크로 활용됩니다.
한계 및 주의사항
- 엄격한 필터링 조건: 반드시 GitHub Issue와 연결된 PR이고, 테스트 패치가 포함된 경우만 우선 고려하여 데이터 소스가 제한적일 수 있습니다.
- 하드웨어 의존성: 수십만 개의 환경을 구축하기 위해 MegaFlow와 같은 대규모 분산 클라우드 인프라가 필수적입니다.
10. Wiki Live Challenge: Challenging Deep Research Agents with Expert-Level Wikipedia Articles
arXiv: 2602.01590 | 기관: muset.ai | ⬆️ 30 | ⭐ 4 🤖 GLM추천 | 📄 HTML 태그:
deep-research-agentwikipediabenchmarkllm-evaluationfact-checkinghallucinationnlpwiki-live-challenge사전 지식: Deep Research Agent (DRA, 자율적 연구를 수행하는 AI 에이전트), Hallucination (할루시네이션, AI가 사실이 아닌 정보를 사실인 것처럼 생성하는 현상), Good Article (GA, 위키백과의 우수 문서 지위), RAG (Retrieval-Augmented Generation, 검색 증강 생성), LLM-as-a-Judge (LLM을 평가자로 활용하는 기법)

한 줄 요약
기존 LLM 기반 평가의 신뢰성 한계를 극복하기 위해, 인간 전문가가 엄격히 검증한 **위키백과 우수 문서(Good Articles)**를 금자석(Gold Standard)으로 삼아 Deep Research Agent(DRA, 심층 연구 에이전트)의 실제 연구 및 작문 능력을 객관적이고 정밀하게 평가할 수 있는 새로운 벤치마크를 제시했기 때문입니다.
💡 핵심 아이디어
최근의 AI 연구 에이전트들을 평가하는 것은 마치 ‘요리 실력’을 시험하는 것과 같습니다. 기존 방식은 다른 AI가 만든 요리(기존 레퍼런스)를 보고 “맛있다”고 평가하거나, 단순히 재료가 들어갔는지만 확인하는 수준이었습니다. 반면, 이 논문은 **미슐랭 셰프가 검증한 완벽한 요리(위키백과 우수 문서)**를 정답으로 제시하고, AI가 그와 동등한 수준의 요리를 만들 수 있는지 레시피의 구성, 맛의 균형, 그리고 재료의 정확성까지 39가지 세부 기준으로 검증하는 ‘마스터셰프 경연 대회’를 만든 것과 같습니다.
문제 정의
최근 Deep Research Agent(DRA, 자율적으로 정보를 수집하고 리포트를 작성하는 AI 시스템)가 급격히 발전하고 있지만, 이를 평가하는 기존 방식들은 신뢰성과 객관성이 부족합니다. 주로 다른 LLM이 생성한 글을 참고로 하거나, AI 스스로를 평가하게 하여 할루시네이션(Hallucination, AI가 그럴싸하지만 사실이 아닌 내용을 생성하는 현상)이나 편향성을 제대로 잡아내지 못한다는 문제가 있습니다.
🔬 방법론 상세
이 논문은 **Wiki Live Challenge (WLC)**라는 실시간 벤치마크와 Wiki Eval라는 평가 프레임워크를 제안합니다.
- 데이터 구축 (Data Construction): 위키백과의 **Good Articles (GAs, 우수 문서)**를 사용합니다. GAs는 중립성, 포괄성, 검증 가능성 등 엄격한 기준을 통과한 문서들로, 이를 ‘전문가 수준의 참조(Reference)‘로 활용하여 100개의 최신 우수 문서를 15개 카테고리에서 수집했습니다.
- Wiki Eval 프레임워크: 단순히 비슷한 단어를 세는 것이 아니라, 위키백과의 편집 가이드라인을 기반으로 평가합니다.
- Wiki Writing (작문 평가): 총 39개의 세부 기준(예: 서술의 중립성, 구조의 논리성, 인용의 적절성 등)을 정의하여, **Judge LLM(판사 AI, Gemini-2.5-pro)**이 AI가 작성한 글과 인간이 작성한 GA 문서를 비교하여 승자를 가립니다.
- Wiki Fact (사실 평가): **Fact LLM(검증 AI, Gemini-2.5-flash)**을 사용하여 AI가 생성한 글에서 사실(Fact)을 추출하고, 이가 위키백과의 사실을 얼마나 잘 **커버(Coverage)**했는지, 인용문을 통해 검증(Verifiability) 가능한지를 측정합니다.
핵심 기법
Wiki Good Article Criteria 기반의 39가지 평가 기준을 LLM에게 적용한 점이 핵심입니다. 단순히 “이 글이 좋니?”라고 묻는 대신, “이 글은 중립적인 어조를 유지하고 있니?”, “핵심 내용에 대한 신뢰할 수 있는 출처가 있니?”와 같이 위키백과 편집자가 사용하는 디테일한 체크리스트를 LLM이 사용하도록 만들어, AI의 글쓰기 품질을 인간의 기준에 가깝게 평가했습니다.
📊 정량적 결과
주요 성과
- 데이터 규모: 15개 카테고리에 걸친 100개의 완전한 위키백과 우수 문서를 수집하여 평가 기반을 마련했습니다.
- 평가 세분화: 작문 품질 평가를 위해 **39개의 세부 기준(Wiki GA-based criteria)**을 수립하여 정밀한 분석을 가능하게 했습니다.
- 모델 갭 발견: OpenAI o3, Gemini 2.5 Pro, GPT-5 등 최신 모델들을 포함한 다양한 Deep Research Agent를 평가한 결과, **현재 최신 에이전트들과 인간이 작성한 위키백과 문서 사이에 여전히 ‘상당한 격차(Substantial gap)‘**가 존재함을 밝혀냈습니다.
🚀 기존 대비 개선점
- 전문가 수준의 참조 데이터: 기존에 다른 LLM이 생성하거나 웹에서 수집한 저품질 데이터를 쓰던 것과 달리, 인간 전문가의 검증을 거친 고품질 데이터를 사용하여 평가의 신뢰도를 획기적으로 높였습니다.
- 다차원적 평가: 글의 유사도만 보는 것이 아니라, **작문 스타일(중립성 등)**과 **사실 관계(인용 및 검증 가능성)**를 분리하여 측정함으로써 AI의 구체적인 약점을 파악할 수 있게 되었습니다.
🎯 활용 분야
- RAG(검색 증강 생성) 시스템 검증: 방대한 외부 지식을 검색하여 글을 쓰는 AI 시스템의 성능을 평가하는 표준으로 사용될 수 있습니다.
- 팩트 체크(Fact-check) 도구 개발: AI가 생성한 콘텐츠의 사실 여부를 판단하는 알고리즘을 훈련시키거나 검증하는 데이터셋으로 활용됩니다.
- AI 연구 에이전트 튜닝: 연구 및 리포트 작업을 자동화하는 AI 에이전트를 개발할 때, 성능 향상을 위한 목표 지표로 활용됩니다.
한계 및 주의사항
- 평가 비용: Fact LLM과 Judge LLM을 사용하여 정밀한 평가를 수행하므로, 평가 과정에서 상당한 양의 **토큰(Token, 처리되는 텍스트 단위)**이 소모되어 비용이 많이 듭니다.
- 정적 벤치마크의 위험: 위키백과 문서는 시간이 지남에 따라 수정될 수 있으므로, “Live” 벤치마크라는 이름에도 불구하고 특정 시점(2025년 12월 15일 수집 기준)의 데이터를 고정해서 쓰면 최신성이 떨어질 수 있습니다.
📅 생성일: 2026-02-03 | 🤖 GLM-4.7