📚 2026-01-29 AI 논문 핵심 요약
📊 순위 기반: 5개 | 🤖 GLM 추천: 5개 📄 전문 분석: 10개 | 📝 초록 분석: 0개
📑 목차
- 📊📄 Harder Is Better: Boosting Mathematical Reaso… ⬆️112
- 📊📄 Advancing Open-source World Models ⬆️91
- 📊📄 Innovator-VL: A Multimodal Large Language Mod… ⬆️73
- 📊📄 DeepSeek-OCR 2: Visual Causal Flow ⬆️42
- 📊📄 Reinforcement Learning via Self-Distillation ⬆️24
- 🤖📄 Spark: Strategic Policy-Aware Exploration via… ⬆️21
- 🤖📄 Linear representations in language models can… ⬆️19
- 🤖📄 AACR-Bench: Evaluating Automatic Code Review … ⬆️14
- 🤖📄 SERA: Soft-Verified Efficient Repository Agen… ⬆️8
- 🤖📄 OmegaUse: Building a General-Purpose GUI Agen… ⬆️8
1. Harder Is Better: Boosting Mathematical Reasoning via Difficulty-Aware GRPO and Multi-Aspect Question Reformulation
arXiv: 2601.20614 | 기관: AMAP-ML | ⬆️ 112 | ⭐ 100 📊 순위선정 | 📄 HTML 태그:
llmmathematical-reasoningrlvrgrpofine-tuningdata-augmentationdgpomath-reasoning사전 지식: Reinforcement Learning (강화 학습), Large Language Models (LLM), RLHF (Reinforcement Learning from Human Feedback), Policy Optimization (정책 최적화), Data Augmentation (데이터 증강)
한 줄 요약
기존 강화 학습 방식들이 놓치고 있던 ‘어려운 문제’의 중요성을 알고리즘(DGPO)과 데이터(MQR) 측면에서 동시에 해결하여, 모델의 수학 추론 능력을 획기적으로 향상시킨 혁신적인 연구입니다.
💡 핵심 아이디어
헬스장에서 운동하는 것에 비유할 수 있습니다. 기존의 모델들은 ‘적당히 무거운 중량’으로만 반복해서 운동(학습)하는 경향이 있었어요. 하지만 이 논문은 “진짜 근육(수학 능력)을 키우려면, 들 수는 있지만 매우 버거운 중량(어려운 문제)“을 들어야 한다고 주장합니다. 즉, 쉬운 문제는 건너뛰고 모델이 땀을 흘려야 하는 어려운 문제에 집중해서 학습시키는 프레임워크를 만든 것이 핵심입니다.
문제 정의
이 논문은 검증 가능한 보상을 사용하는 강화 학습(RLVR)이 수학 추론에 유력하지만, 두 가지 큰 문제가 있음을 지적합니다.
- 알고리즘적 문제: 널리 쓰이는
GRPO방식이 어려운 문제일수록 모델을 개선하는 정도(업데이트 크기)가 오히려 작아지는 불균형 현상이 있습니다.- 데이터적 문제: 기존의 데이터 증강(Data Augmentation)은 단순히 문장을 바꾸는(Rephrasing) 수준이라, 문제의 본질적 난이도를 높이지 못합니다.
🔬 방법론 상세
이 논문은 MathForge라는 프레임워크를 제안하며, 크게 두 가지 축으로 문제를 해결합니다.
-
Difficulty-Aware Group Policy Optimization (DGPO): 기존
GRPO가 가진 업데이트 불균형 문제를 해결한 새로운 알고리즘입니다.- DGAE (Difficulty-balanced group advantage estimation): 문제의 난이도와 상관없이 업데이트 크기를 정규화(Normalize)하여, 어려운 문제도 충분히 학습될 수 있게 합니다.
- DQW (Difficulty-aware question-level weighting): 학습 시 더 어려운 문제에 더 높은 가중치(Weight)를 두어 모델이 이 문제들에 집중하게 만듭니다.
-
Multi-Aspect Question Reformulation (MQR): 데이터 관점에서 어려운 문제를 만들어내는 전략입니다.
- 단순히 표현을 바꾸는 것이 아니라, 정답은 그대로 유지하면서 문제의 **내재적 난이도(Intrinsic difficulty)**를 높이는 방향으로 질문을 재구성합니다.
핵심 기법
가장 중요한 부분은 **DGPO(알고리즘)**와 **MQR(데이터)**의 시너지 효과입니다. 알고리즘으로는 “어려운 문제를 더 중요하게 학습하겠다고 선언”하고, 데이터로는 “실제로 어려운 문제를 공급”하여, 모델이 하드코어한 수학 훈련을 받도록 유도한 점이 인상깊습니다.
📊 정량적 결과
제공된 텍스트에는 구체적인 수치(예: 12.5% 상승 등)가 포함되어 있지 않으나, 실험 결과에 대한 정성적인 설명은 다음과 같습니다.
주요 성과
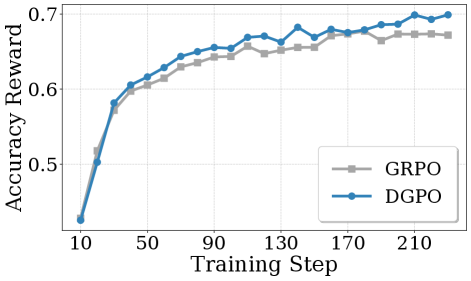
- 다양한 벤치마크 압도: AIME24, AIME25, AMC23, MATH500, Minerva, Olympiad 등 6개의 주요 수학 추론 벤치마크에서 기존 SOTA(State-of-the-art) 방법들(GRPO, Dr.GRPO, GPG 등)을 큰 폭으로 능가했습니다.
- 모델 확장성 검증: Qwen2.5-Math-7B뿐만 아니라, 1.5B, 3B, DeepSeek-Math-7B 등 다양한 크기의 모델과 멀티모달 모델(Qwen2.5-VL-3B)에서도 성능 향상이 입증되었습니다.
- 안정적인 성능: AIME24/25, AMC-23에서 각 32회씩 반복 실험을 진행하여, 결과의 통계적 유의성과 안정성을 확인했습니다.
🚀 기존 대비 개선점
- 업데이트 효율성: 어려운 문제에서도 학습이 잘 되도록 알고리즘을 수정하여, 학습 시간을 낭비하지 않고 효율적으로 모델의 능력을 끌어올립니다.
- 데이터 품질: 단순히 양을 늘리는 증강이 아니라, ‘난이도’를 높이는 방향으로 질문의 질을 개선했습니다.
- 범용성: 텍스트 수학뿐만 아니라 기하학 문제(GeoQA)를 푸는 멀티모달 영역에서도 효과적입니다.
🎯 활용 분야
- 고난이도 수학 튜터링 AI: 사용자가 수학 문제를 물어보면 단순히 답만 알려주는 것이 아니라, 변형된 어려운 문제를 내주며 실력을 키워주는 시스템.
- 자동화된 알고리즘 설계: 소프트웨어 공학이나 금융 공학 등 복잡한 수학적 추론이 필요한 분야의 최적화 솔루션 도구.
- 수학 올림피아드 트레이너: 경시 대회 준비생들을 위한 고난도 문제 자동 생성 및 채점 시스템.
한계 및 주의사항
- 제공된 텍스트 내에서 저자가 명시적으로 언급한 한계점은 없으나, ‘어려운 문제’를 생성하고 학습하는 데 추가적인 연산 비용(Computational Overhead)이 발생할 수 있습니다.
- 또한, 모델이 ‘풀 수 없을 정도로 어려운 문제(Unsolvable)‘까지 학습 데이터에 포함될 경우, 오히려 학습을 방해할 수 있으므로 ‘풀 수 있는 어려움(Solvable but hard)‘을 유지하는 것이 중요합니다.
2. Advancing Open-source World Models
arXiv: 2601.20540 | 기관: Robbyant | ⬆️ 91 | ⭐ 1226 📊 순위선정 | 📄 HTML 태그:
world-modelvideo-generationsimulationopen-sourcereal-time-inferencecausal-aitransformerreinforcement-learning사전 지식: Generative Models (생성 모델), Diffusion Models (확산 모델), Transformer Architecture, Reinforcement Learning (강화학습), Knowledge Distillation (지식 증류)

한 줄 요약
이 논문은 단순한 비디오 생성을 넘어, 실시간 상호작용과 장기 기억 능력을 갖춘 고성능 오픈소스 월드 시뮬레이터(LingBot-World)를 공개함으로써, 폐쇄형 기술과 오픈소스 간의 격차를 해소하고 ‘텍스트에서 비디오’에서 ‘텍스트에서 월드’로의 패러다임 전환을 가속화했다는 점에서 매우 중요합니다.
💡 핵심 아이디어
기존의 비디오 생성 모델이 꿈을 꾸듯이 이미지를 띄엄띄엄 만들어내는 ‘몽상가’라면, LingBot-World는 사용자의 조작(행동)에 따라 물리 법칙과 인과 관계를 지키며 실시간으로 반응하는 ‘게임 엔진’과 같습니다. 마치 영화 감독이 피사체에게 지시를 내려 실시간으로 장면을 바꾸는 것처럼, 모델이 상황을 맥락적으로 이해하고 미래를 예측하는 능력을 갖추도록 훈련시켰습니다.
문제 정의
현재 최신 기술의 비디오 생성 모델들은 짧고 시각적으로 그럴싸한 클립을 만들 수는 있지만, 근본적으로 통계적 상관관계에 기반한 ‘환각(Hallucination, 사실이 아닌 것을 사실처럼 생성하는 현상)‘을 일으킬 뿐입니다. 이들은 인과율, 객체 지속성(Object Permanence, 객체가 시야에서 사라져도 계속 존재한다는 인지), 상호작용의 결과와 같은 물리적 법칙을 이해하지 못하므로, 수동적인 영상 제작을 넘어 에이전트가 행동할 수 있는 지속적이고 논리적인 ‘월드 시뮬레이터’로는 기능할 수 없다는 문제를 해결하고자 합니다.
🔬 방법론 상세
-
조건부 생성 과정 정의 (Formulation): 월드 모델을 에이전트의 행동(제어 신호)에 의해 구동되는 시각적 상태의 진화를 시뮬레이션하는 과정으로 정의합니다. 수식적으로는 과거의 프레임 $x_{<t}$와 현재 및 미래의 제어 신호(행동) $a_{t:t+L}$이 주어졌을 때, 미래 상태 $x_{t:t+L}$의 가능도(Likelihood)를 최대화하는 파라미터 $\theta$를 학습합니다. $$ \max_{\theta}\mathbb{E}\left[\log p_{\theta}(x_{t:t+L}\mid x_{<t},a_{t:t+L})\right] $$ 여기서 $L$은 예측 수평(Prediction Horizon, 얼마나 먼 미래까지 예측할지)을 의미합니다.
-
다단계 진화 전략 (Multi-stage Evolution Strategy): 학습 과정을 세 단계로 분해하여 기본 비디오 생성기를 인터랙티브 시뮬레이터로 변화시킵니다.
- Foundation (기초): 대규모 비디오 데이터로 사전 학습
- Knowledge Injection (지식 주입): 물리적 법칙이나 논리적 일관성과 같은 지식을 주입
- Interaction Readiness (상호작용 준비): 행동 제어(Action Conditioning)에 최적화하여 실시간 상호작용이 가능하도록 미세 조정
-
실시간 증류 (Real-time Distillation): 방대한 교사 모델(Teacher model)의 지식을 경량화된 학생 모델로 증류(Distillation, 지식 전이)하여, 성능 저하를 최소화하면서도 실시간 추론이 가능하도록 만드는 기법을 사용했습니다.
핵심 기법
이 논문의 가장 중요한 기법은 **‘다단계 진화 전략’**입니다. 마치 아이가 성장하는 과정처럼, 모델에게 처음에는 단순히 ‘영상을 그리는 법’을 가르치고, 그 다음에는 ‘세상의 이치(물리 법칙 등)‘를 가르치며, 마지막으로는 ‘사용자의 입력에 따라 움직이는 법’을 단계적으로 학습시켜, 단순한 영상 생성기가 아닌 상호작용 가능한 시뮬레이터로 진화시켰습니다.
📊 정량적 결과
주요 성과
- 실시간 성능: LingBot-World-Fast 모델은 단일 GPU 노드에서 480p 해상도의 비디오를 처리할 때 **초당 16 프레임(fps)**의 처리 속도를 달성했습니다.
- 지연 시간 (Latency): 사용자 입력에 대한 반응 속도가 1초 미만으로, 실시간 인터랙티브 애플리케이션에 사용 가능한 수준입니다.
- 긴 호라이즌 (Long Horizon): ‘장기 기억’이라 불리는 맥락적 일관성을 유지하며 **분 단위(Minute-level)**의 긴 시간 동안 시뮬레이션을 수행할 수 있습니다.
🚀 기존 대비 개선점
- 통합된 파이프라인 제공: 데이터 수집부터 모델 학습, 실시간 추론 최적화까지 전체 과정을 포괄하는 프레임워크를 제공하여, 연구자들이 개별적으로 구축할 때 발생하는 비효율을 제거했습니다.
- 오픈소스 격차 해소: 기존에는 폐쇄형(Closed-source) 기술만이 가졌던 고품질 월드 시뮬레이션 능력을 오픈소스 커뮤니티에 공개하여 접근성을 획기적으로 높였습니다.
- 품질-속도의 균형: 실시간 속도를 위해 모델을 경량화하더라도(LingBot-World-Fast), 시각적 품질 저하는 ‘인지적으로 미미한 수준(Perceptually marginal)‘에 머물도록 최적화했습니다.
🎯 활용 분야
- AI 에이전트 훈련 환경: 가상의 세상에서 로봇이나 AI 에이전트가 실제와 같은 물리 법칙 하에 시행착오를 거치며 학습할 수 있는 시뮬레이션 환경 제공
- 인터랙티브 콘텐츠 제작: 사용자의 입력에 따라 스토리가 실시간으로 변하거나 환경을 편집할 수 있는 게임 및 메타버스 콘텐츠 개발
- 3D 환경 이해 및 생성: 2D 비디오뿐만 아니라 3D 공간에서의 지속적인 환경 생성 및 편집 지원
한계 및 주의사항
- 속도와 품질의 트레이드오프: 실시간 버전(Fast)은 속도를 위해 이론적인 품질 상한(Theoretical upper-bound quality)을 약간 희생할 수밖에 없습니다. 저자는 시각적 저하는 미미하다고 하지만, 완벽하게 동일하진 않습니다.
- 복잡한 환경에서의 일반화: 다양한 스타일(현실, 만화 등)에 대해 일반화 능력을 보였지만, 아직 매우 복잡하거나 예측 불가능한 물리적 상호작용에서는 ‘꿈꾸는(Dreaming)’ 경향이 남아있을 수 있습니다.
3. Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
arXiv: 2601.19325 | 기관: Shanghai Jiao Tong University | ⬆️ 73 | ⭐ 91 📊 순위선정 | 📄 HTML 태그:
innovator-vlscientific-aimultimodal-llmdata-efficiencyfine-tuningchain-of-thoughtqwen3agi사전 지식: Multimodal Large Language Model (MLLM), Projector (Vision-Language Connector), Supervised Fine-tuning (SFT), Reinforcement Learning (RL), Chain-of-Thought (CoT)

한 줄 요약
방대한 과학 데이터에 의존하는 기존 불투명한 트렌드를 깨고, 투명하고 원칙적인 설계를 통해 훨씬 적은 데이터로도 뛰어난 과학적 이해 및 추론 능력을 갖춘 멀티모달 모델(MLLM)을 구축하여 AGI(인공지능) 및 SGI(과학 지능) 실현 가능성을 입증했기 때문에 중요합니다.
💡 핵심 아이디어
과학적 발견을 위한 모델을 만들 때, 도서관의 모든 책을 다 외우게 하려는 것(대규모 데이터 사전학습)보다는 이미 지능이 뛰어난 두뇌(LLM)에 시각(Visual)이라는 눈을 달아주고, **‘어떻게 생각할 것인가(Reasoning)‘**를 효율적으로 훈련시키는 것이 핵심입니다. 마치 탄탄한 기초 교육을 받은 조수에게 핵심적인 연구 노트만 전달해도 복잡한 과제를 해결하도록 만드는 것과 같습니다.
문제 정의
현재의 멀티모달 대형 언어 모델(MLLM)들은 일반적인 시각 작업에는 강하지만, 정밀한 이해와 복잡한 다단계 추론이 필요한 과학 영역의 과제에서는 여전히 어려움을 겪고 있으며, 이를 해결하기 위해 과도하게 많은 데이터와 불투명한 학습 과정에 의존하는 문제가 있습니다.
🔬 방법론 상세
- 투명한 2단계 사전학습 (Pre-training):
- 언어-이미지 정렬 (Language-Image Alignment): 시각 특징(Visual Features)을 LLM의 단어 공간으로 매핑하는 **프로젝터(Projector)**만 학습시켜 모델이 이미지를 이해할 수 있게 합니다. (약 558K 샘플 사용)
- 고품질 미드-트레이닝 (High-quality Mid-Training): 사전학습된 LLM(Qwen3-8B-Base)의 모든 파라미터를 업데이트하여 새로운 지식을 효율적으로 주입합니다. (약 85M 샘플 사용)
- 단계적 사후 학습 (Staged Post-training):
- 지도 학습 미세 조정 (Supervised Fine-tuning, SFT): 일반 시각 지시 수행, Chain-of-Thought(사고의 사슬, 단계적 추론) 능력, 과학적 이해 능력을 강화하기 위해 전체 파라미터를 학습합니다. (약 46M 샘플)
- 강화 학습 (Reinforcement Learning): 모델의 복잡한 문제 해결 능력과 답변의 품질을 더욱 정교화합니다. (약 172K 샘플)
핵심 기법
Mid-Training (미드-트레이닝): 보통 모델을 처음부터 끝까지(Prompt Tuning) 새로 학습하거나, 아주 조금만(LoRA) 건드리는데, 이 논문은 중간 단계에서 모든 파라미터를(Full-Parameter) 학습시켜 계산 효율성과 새로운 지식 주입 사이의 균형을 맞췄습니다. 이미 강력한 언어 모델(Qwen3)을 기반으로 하여 과학 데이터를 다시 처음부터 학습할 필요 없이 효율적으로 지식을 흡수시키는 전략입니다.
📊 정량적 결과
주요 성과
- 데이터 효율성: 기존 방식 대비 “substantially reduced data requirements”(현저히 줄어든 데이터 요구량)을 통해 강력한 성능을 달성했습니다.
- 학습 데이터 규모: 언어-이미지 정렬 단계(558K)부터 고품질 미드-트레이닝(85M), SFT(46M), 강화 학습(172K)까지 투명하게 공개된 총 데이터 규모를 통해 재현성을 확보했습니다.
- 범용 성능 유지: 과학적 태스크에 특화되면서도 일반적인 비전 작업(Visual Question Answering, Image Captioning 등)에서도 우수한 성능(Excellent performance)을 유지했습니다.
🚀 기존 대비 개선점
- 불투명성 제거: 모델 학습의 모든 단계(데이터 수집, 전처리, SFT, RL)를 투명하고 완전히 재현 가능한 파이프라인으로 공개했습니다.
- 데이터 수요 감소: 막대한 도메인 특화 데이터 없이도 원칙적인 훈련 설계를 통해 높은 과학 지능을 구현했습니다.
- 추론 능력 강화: SFT 단계에서 Chain-of-Thought 데이터를 통해 모델이 단순히 답을 맞추는 것을 넘어, 논리적인 사고 과정을 거쳐 답을 도출하도록 훈련했습니다.
🎯 활용 분야
- 과학적 연구 보조: 복잡한 과학 도표, 그래프, 논문 이미지를 분석하여 연구자의 이해를 돕는 AI 스터디 버디.
- 정밀한 멀티모달 추론: 의학 진단 이미지, 재료 과학 분석, 화학 구조 해석 등 정밀한 도메인 지식이 필요한 분야.
- AGI/SGI 연구: 인공지능이 과학적 발견을 수행할 수 있는지(Scientific General Intelligence) 검증하는 벤치마크 및 기반 모델로 활용.
한계 및 주의사항
- 내부 버전의 미공개: Qwen3-8B-Base에 고품질 과학 말뭉치로 추가 사전학습을 진행한 강화 버전이 존재하지만, 데이터 규정 검토(Data compliance review) 절차로 인해 아직 공개되지 않았습니다.
- 데이터 의존성: 데이터 양은 줄였지만, 그만큼 고품질(High-quality)의 학습 데이터를 큐레이션(Curation, 엄선)하는 데 대한 의존도가 높습니다.
4. DeepSeek-OCR 2: Visual Causal Flow
arXiv: 2601.20552 | 기관: DeepSeek | ⬆️ 42 | ⭐ 1742 📊 순위선정 | 📄 HTML 태그:
deepseek-ocrvisual-causal-flowcomputer-visiondocument-understandingencoder-decodertoken-reorderingmultimodal-ai사전 지식: Vision-Language Models (VLMs), Raster Scan (주사선 순서), Positional Encoding (위치 인코딩), Attention Mechanism (어텐션 메커니즘), Causal Reasoning (인과적 추론)

한 줄 요약
기존의 물리적 순서(래스터 스캔)에 얽매이던 시각 모델의 한계를 깨고, 인간의 시각 인지처럼 **이미지의 의미(semantic)에 따라 토큰을 동적으로 재배열하는 인과적 추론 능력(Visual Causal Flow)**을 비전 인코더에 도입하여 복잡한 문서 이해 능력을 획기적으로 개선했기 때문에 중요합니다.
💡 핵심 아이디어
기존 모델이 책을 읽을 때 “첫 페이지 첫 줄부터 마지막 페이지 마지막 줄까지” 무조건 왼쪽에서 오른쪽으로만 읽는 방식이라면, DeepSeek-OCR 2는 “제목을 보고 → 중요한 그래프를 찾아보고 → 필요한 설명을 읽는” 식으로 눈동자를 의미있는 곳으로 움직이는 인간의 독서 방식을 모방합니다. 단순히 이미지를 잘라서 나열하는 것이 아니라, 이미지 내의 논리적 흐름을 파악해 토큰의 순서를 인과적으로(Causally) 재배열합니다.
문제 정의
기존 비전-언어 모델(VLMs)은 2D 이미지를 1D 시퀀스로 변환할 때, 래스터 스캔(Raster-scan, 좌측 상단에서 우측 하단으로의 순차적 스캔) 방식과 고정된 위치 인코딩을 사용합니다. 이는 복잡한 레이아웃(표, 공식, 비선형 구조)을 가진 문서에서 시각적 요소 간의 의미적 연관성을 무시하고, 인간의 유연한 시각 인지 방식과 배치되는 **잘못된 귀납적 편향(Inductive Bias)**을 초래하는 문제를 해결하고자 합니다.
🔬 방법론 상세
- DeepEncoder V2 (인과적 비전 인코더): 기존 인코더가 단순히 특징을 추출만 했다면, 이번 버전은 양방향(Bidirectional)과 인과적(Causal) 어텐션 메커니즘을 통합해 시각적 세계에 대한 **인과적 이해(Causal Understanding)**를 증류합니다. 이를 통해 토큰을 물리적 위치가 아닌 **의미적 중요도에 따라 재정렬(Reordering)**합니다.
- Dynamic Token Reordering (동적 토큰 재배열): 이미지 패치를 고정된 순서가 아닌, 이미지의 내용(의미)에 따라 유연하게 재배열하여 LLM에 입력함으로써, 텍스트 생성의 정확도를 높입니다.
- Multi-Crop Strategy (멀티 크롭 전략): 이미지를 하나의 전역적 시점(Global View)으로만 보는 것이 아니라, 최대 6개의 국부적 시점(Local Views)으로 잘라 세부 정보를 포착합니다. 이를 통해 단일 이미지당 256개(전역)에서 최대 1120개(전역+국부)의 토큰을 동적으로 생성합니다.
핵심 기법
**Visual Causal Flow (시각적 인과 흐름)**를 적용한 것입니다. 단순히 시선을 이동하는 것이 아니라, **“이전 시점에서 본 것을 바탕으로 다음에 어디를 봐야 할지 결정하는 능력”**을 모델에 심어주었습니다. 마치 퍼즐을 맞출 때 순서대로 조각을 집어 넣는 게 아니라, 완성된 그림의 맥락을 파악해 맞는 조각부터 찾아 끼우는 방식과 유사합니다.
📊 정량적 결과
주요 성과
- 토큰 수의 유연한 최적화: 이미지 복잡도에 따라 토큰 수를 **256개(단순 이미지)에서 최대 1120개(복잡한 이미지, 6x local crops + 1 global)**까지 동적으로 조절하여 효율성과 성능을 동시에 확보했습니다.
- 데이터 구성 개선: 학습 데이터를 텍스트, 수식, 표의 비율을 3:1:1로 균형 있게 구성하고, 레이아웃 감지를 위한 라벨을 정제(Figure caption과 title 통합 등)하여 학습 품질을 높였습니다.
- (참고: 제공된 전문에는 구체적인 벤치마크 정확도 % 수치는 포함되어 있지 않으나, “의미 있는 성능 향상(meaningfully performance improvements)“과 “시각적 독해 논리의 현저한 상승(marked lifts in visual reading logic)“을 달성했다고 명시되어 있습니다.)
🚀 기존 대비 개선점
- 유연한 시각 처리: 고정된 래스터 스캔 순서에서 벗어나, 문서의 의미 구조에 따라 토큰을 처리하는 유연한 인과적 추론이 가능해졌습니다.
- 복잡한 레이아웃 이해도 향상: 표(Table), 수식(Formula), 복잡한 양식 등 비선형적인 구조를 가진 문서에서 기존 모델보다 훨씬 정확한 이해를 보여줍니다.
- 고해상도 세부 정보 처리: Multi-Crop 전략을 통해 전역 맥락을 잃지 않으면서도 국부적인 세부 묘사(작은 글씨, 복잡한 기호 등)를 정밀하게 분석할 수 있습니다.
🎯 활용 분야
- 복잡한 문서 자동화: 금융 보고서, 학술 논문, 법률 문서 등 표와 수식이 섞인 복잡한 문서의 구조 분석 및 정보 추출.
- 지능형 문서 스캐너: 손으로 쓴 양식이나 복잡한 영수증, 계약서 등을 디지털 텍스트로 변환하는 OCR 시스템 고도화.
- 멀티모달 RAG (Retrieval-Augmented Generation): 문서의 논리적 흐름을 이해하고 검색하여, 답변 생성 시 문맥을 더 정확히 파악해야 하는 검색 증강 생성 시스템.
한계 및 주의사항
- 작업 범위의 한계: 현재 연구는 주로 광학 텍스트 읽기(Optical Text Reading), 특히 문서 파싱에 집중되어 있어, 일반적인 시각 이해(자연물 이미지 등) 전반으로 확장하려면 추가적인 아키텍처 정제가 필요합니다.
- 계산 비용: 최대 1120개의 토큰과 여러 view를 처리해야 하므로, 단순 이미지 처리보다는 연산량이 증가할 수 있습니다.
5. Reinforcement Learning via Self-Distillation
arXiv: 2601.20802 | 기관: LAS @ ETH Zurich | ⬆️ 24 | ⭐ 59 📊 순위선정 | 📄 HTML 태그:
llmreinforcement-learningself-distillationsdporlvrreasoningcode-generationcredit-assignment사전 지식: Reinforcement Learning (강화 학습), RLHF (Reinforcement Learning from Human Feedback), PPO (Proximal Policy Optimization), Knowledge Distillation (지식 증류), Credit Assignment Problem (신용 할당 문제)

한 줄 요약
이 논문은 LLM 강화 학습에서 “이게 왜 틀렸는지”를 모르는 문제(신용 할당 병목)를 해결하기 위해, 환경이 주는 텍스트 피드백(에러 메시지 등)을 외부 교사 없이 스스로 학습 신호로 활용하는 SDPO(Self-Distillation Policy Optimization) 방법을 제안하여 기존 최신 방법(GRPO) 대비 훨씬 적은 데이터로 더 높은 성능을 달성했기 때문에 중요합니다.
💡 핵심 아이디어
기존 강화 학습이 시험 채점에서 “틀렸다(O)“라는 결과만 알려주는 것과 비슷하다면, SDPO는 선생님이 채점지에 “이 부분 공식이 틀렸으니 이렇게 고쳐라”라고 구체적으로 적어주는 피드백을 활용해 학생(모델)이 스스로 실수를 교정하도록 만드는 방식입니다. 모델은 자신의 실수 답안과 정답 답안을 비교하거나 에러 메시지를 바탕으로 “스스로 선생님”이 되어 정답을 생성하고, 이를 다시 원래의 모델에게 가르쳐주는(Self-Distillation) 과정을 반복합니다.
문제 정의
현재 LLM을 강화 학습(RL)으로 후훈련(Post-training) 할 때, 코딩이나 수학처럼 답이 검증 가능한 영역에서는 주로 **단순한 점수(0 또는 1)**만 보상으로 줍니다. 이는 모델이 답이 틀렸을 때 “어떤 토큰(Token, 단어 단위)” 때문에 틀렸는지 알 수 없어 학습 효율이 떨어지는 신용 할당(Credit Assignment)의 병목을 유발합니다.
🔬 방법론 상세
- RLRF (Reinforcement Learning with Rich Feedback): 환경이 단순한 스칼라 보상(점수)이 아닌, 텍스트 형태의 피드백(예: 런타임 에러, 심사 평가)을 제공하는 설정을 공식화합니다.
- Self-Teacher Distillation: 현재 모델 정책($\pi_\theta$)을 두 가지 역할로 나눕니다.
- Student: 기존 정책 그대로 행동을 선택함.
- Self-Teacher: 실패한 행동이나 질문에 피드백(또는 같은 배치의 성공한 답변)을 조건으로 입력받아, 정답을 생성하는 확률 분포를 계산함. 이때 Self-Teacher가 생성한 정답 분포를 목표(Target)로 하여 Student를 업데이트합니다. (별도의 보상 모델 Reward Model이 필요 없음)
- Dense Credit Assignment: 전체 시퀀스에 하나의 보상을 주는 대신, 토큰 단위로 정답과 비교하여 미세하게 로그 확률(Log-probability)을 조정함으로써, 어디서 틀렸는지를 밀도 높게 학습합니다.
핵심 기법
SDPO의 가장 큰 특징은 **“Self-Teacher”**입니다. 외부에서 GPT-4 같은 강력한 모델을 가져와 정답을 지도(Supervision)해 주는 것이 아니라, 현재 학습 중인 모델 자신이 피드백을 조건으로 붙였을 때(Oops, I made a mistake. Here is the fix…) 더 잘할 수 있다는 점을 착안했습니다. 즉, 모델의 문맥 학습 능력(In-context Learning)을 RL 신호 생성에 재활용하는 것입니다.
📊 정량적 결과
주요 성과
- LiveCodeBench v6 (코딩 벤치마크): Qwen3-8B 기준 SDPO는 48.8%, 기존 방식인 GRPO는 **41.2%**의 정확도를 기록하여 약 7.6%p의 성능 향상을 달성했습니다.
- 학습 효율성: GRPO가 최종 성능에 도달하기 위해 필요한 생성량(Generations)의 1/4(4× fewer) 만으로도 동일한 수준에 도달할 수 있었습니다.
- Science Q&A 및 Tool use: 화학, 물리, 생물학 등 과학 추론 문제와 툴 사용(Task)에서도 GRPO 대비 일관되게 높은 성능을 보였습니다.
🚀 기존 대비 개선점
- 보상 모델 불필요: 별도의 보상 모델(Reward Model)을 학습하거나 유지할 필요가 없어 구현이 간편합니다.
- 높은 샘플 효율성: 단순한 성공/실패 결과만 보고 반복해서 시도하는 것보다, 피드백을 통해 실수 원인을 바로 파악하므로 학습 속도가 빠릅니다.
- 환경 정보의 극대화: 프로그래밍 에러 메시지나 채점 로그 등 기존에 무시되던 환경의 부가 정보를 학습에 완벽하게 활용합니다.
🎯 활용 분야
- 코드 생성 및 디버깅: 컴파일 에러나 실패한 테스트 케이스를 읽고 스스로 코드를 수정하는 AI 개발助手(Copilot) 고도화.
- 수학 및 과학 추론: 풀이 과정이 틀렸을 때 피드백을 통해 논리적 오류를 수정하는 추론 능력 강화.
- 도구 활용 학습: API 호출이 실패했을 때 에러 메시지를 보고 올바른 파라미터를 찾아내는 에이전트(Agent) 훈련.
한계 및 주의사항
- 피드백 품질 의존성: 환경이 제공하는 피드백(에러 메시지 등)이 모호하거나 부정확하다면, 모델이 잘못된 신호를 학습할 위험이 있습니다.
- 자기 자신에 대한 의존: 아직 능력이 부족한 초기 단계의 모델은 스스로를 교사로 삼아도 제대로된 수정(피드백 조건부 정답 생성)을 하지 못해 학습이 잘 진행되지 않을 수 있습니다 (Cold Start 문제).
6. Spark: Strategic Policy-Aware Exploration via Dynamic Branching for Long-Horizon Agentic Learning
arXiv: 2601.20209 | ⬆️ 21 🤖 GLM추천 | 📄 HTML 태그:
agentic-ailong-horizon-taskreinforcement-learningdynamic-branchingexploration-efficiencyllm-optimizationspark-algorithmresource-allocation사전 지식: Reinforcement Learning (강화 학습), Large Language Models (LLM), Agentic AI (에이전트형 AI), Monte Carlo Tree Search (몬테카를로 트리 탐색), Trajectory (궤적, 상태와 행동의 순차적 기록)

한 줄 요약
이 논문은 제한된 컴퓨팅 자원 하에서도 장기 복잡한 과제(Long-horizon task)를 해결하는 LLM 에이전트를 효율적으로 학습시키기 위해, 단순히 탐색 양을 늘리는 것이 아니라 중요한 결정 순간(Critical decision point)에만 집중적으로 자원을 투자하는 동적 분기(Dynamic branching) 전략을 도입한 점이 매우 중요합니다.
💡 핵심 아이디어
기존 방식이 마치 길을 찾을 때 모든 사거리에서 무조건 여러 갈래로 뻗어나가며 탐색하던 것이라면, Spark는 운전자가 **“이 지점은 복잡하니까 조심스럽게 여러 경로를 확인해보고, 저 straight한 도로는 그냥 빠르게 지나가자”**라고 판단하며 자원을 배분하는 똑똑한 내비게이션과 같습니다. 이를 통해 중요하지 않은 단계에서 낭비되는 연산을 줄이고, 정말 중요한 순간에 고민을 더 많이 하여 성공 확률을 높입니다.
문제 정의
이 논문이 해결하려는 핵심 문제는 **“에이전트형 AI(Agentic AI) 학습 시 고품질의 학습 데이터(Trajectory)가 부족하고, 제한된 자원으로 탐색할 때 비효율이 발생한다”**는 것입니다. 수학 문제와 달리 실제 환경에서의 복잡한 작업은 상태 공간(State space)이 넓고 한 번의 실수로도 전체가 실패하므로, 기존의 균일한 탐색 방식은 자원을 낭비하고 질 좋은 샘플을 얻기 어렵습니다.
🔬 방법론 상세
- Strategic Policy-Aware Exploration (전략적 정책 인식 탐색): 현재 정책(Policy, 에이전트의 행동 규칙)이 중요한 상황에 처했는지를 인지하여 탐색 전략을 dynamically(동적으로) 변경합니다. 단순히 무작위로 탐색하지 않고 정책의 확신도나 상태의 중요성을 고려합니다.
- Dynamic Branching at Key-states (주요 상태에서의 동적 분기): 모든 단계에서 분기(Branching)를 수행하는 기존 Tree-search 기법과 달리, **Critical Decision Points(중요한 결정 지점)**에서만 탐색 경로를 확장(Branching)합니다. 이를 통해 불필요한 연산량을 획기적으로 줄입니다.
- Resource-efficient Exploration (자원 효율적 탐색): Rollout(궤적 생성 시뮬레이션) 과정에서 자원을 균등하게 배분하는 것이 아니라, 실패 가능성이 높거나 복잡한 구간에 컴퓨팅 파워를 집중 배치합니다.
핵심 기법
가장 중요한 기법은 **Dynamic Branching(동적 분기)**입니다. 이는 마치 위험 관리가 필요한 중요한 교차로에서만 잠시 멈춰 길을 여러 갈래 확인해보고, 단순한 직진 도로에서는 정속 주행하는 것과 같습니다. 이를 통해 전체 여행 시간(연산량)은 줄이면서도 목적지 도착(과제 성공) 확률은 높이는 효과를 냅니다.
📊 정량적 결과
제공된 전문 텍스트에는 구체적인 성능 향상 수치(예: 15.3% 개선 등)는 명시되지 않았으나, ALFWorld, ScienceWorld, WebShop 벤치마크에서 기존 강력한 모델(GPT-4o, GPT-5 시리즈 등) 및 RL 방법론(GRPO, ETO 등) 대비 **“우월한 성공률(Superior success rates)“**과 **“개선된 탐색 효율성(Better exploration efficiency)“**을 달성했다고 보고하고 있습니다.
주요 성과
- 벤치마크: ALFWorld (Embodied Decision Making), ScienceWorld (Scientific Reasoning, 최대 30+ 스텝), WebShop (Web Navigation, 110만 제품 탐색)에서 우수한 성과 입증
- 효율성: 유사한 컴퓨팅 예산(Computational budget) 하에서 기존 방법보다 더 높은 품질의 Trajectory(학습 데이터) 생성
- 일반화: 보이지 않은 시나리오(Unseen scenarios)에서도 견고한 성능(Robust generalization) 발휘
🚀 기존 대비 개선점
- 자원 낭비 최소화: 기존 RL 방식이 사소한 단계(Trivial steps)에도 많은 자원을 쓰던 것을 개선하여, 중요한 순간에만 자원을 집중 투자합니다.
- 샘플 품질 보장: 무작위 탐색에 의존하던 기존 방식과 달리, 전략적 분기를 통해 고품질의 성공 궤적을 더 확실하게 확보합니다.
- 자율적 탐색: 사람이 개입하여 중요한 지점을 표시할 필요 없이, 에이전트가 스스로 판단하여 탐색 예산을 배분합니다.
🎯 활용 분야
- 로봇 공학 및 가정용 로봇: 복잡한 가정 환경(ALFWorld)에서 장기적인 가사(청소, 물건 정리 등)를 수행하는 에이전트 학습
- 복잡한 과학적 추론: 여러 실험 단계가 필요한 과학적 문제 해결(ScienceWorld) 시스템
- 웹 에이전트 및 쇼핑 도우미: 수많은 옵션(WebShop) 속에서 사용자 요구에 맞는 제품을 찾아 구매까지 수행하는 오픈형 웹 탐색
한계 및 주의사항
- Critical Decision Point 판별의 난이도: 어떤 상태가 “중요한 결정 지점”인지 정확히 식별하는 것 자체가 까다로울 수 있으며, 이 식별 알고리즘의 성능에 전체 시스템의 효율이 크게 의존할 것입니다.
- 장기 의존성(Long-term dependency): 여전히 아주 긴 호라이즘(30단계 이상)에서 초기의 작은 오류가 누적되어 나중에 치명적이 되는 문제(derailment)는 완전히 해결되지 않았을 수 있습니다.
7. Linear representations in language models can change dramatically over a conversation
arXiv: 2601.20834 | 기관: Google | ⬆️ 19 🤖 GLM추천 | 📄 HTML 태그:
llminterpretabilitylinear-representationsin-context-learningmechanistic-interpretabilityrepresentation-dynamicsmodel-safetyrole-play사전 지식: Linear Representations (선형 표현), In-Context Learning (인컨텍스트 러닝), Mechanistic Interpretability (기계적 해석가능성), Hidden States (은닉 상태), Linear Probing (선형 탐색)

한 줄 요약
언어 모델이 사실성(Factuality)이나 윤리성 같은 고차원 개념을 내부적으로 어떻게 표현하는지가 대화의 맥락에 따라 동적이고 극적으로 뒤집힐 수 있음을 밝혀, LLM의 내부 표현이 고정된 신념이 아닌 상황에 맞춰 유연하게 변형되는 역할 수행(Role-play)의 성질이 강함을 입증했기 때문에 중요합니다.
💡 핵심 아이디어
언어 모델의 내부 표현을 ‘나침반’으로 생각해보세요. 평소에는 빨간 바늘이 ‘사실’을 가리키지만, 대화라는 강력한 ‘자기장’(예: “반대 날”이라는 맥락)이 작용하면, 모델은 내부 지도를 통째로 뒤집어서 같은 바늘이 이제 ‘거짓’을 가리키도록 설정을 변경합니다. 즉, 모델이 외부 세계의 진실을 왜곡하는 것이 아니라, 주어진 상황(극중 배경)에 맞춰 내부의 의미 체계(좌표축)를 재배열한다는 것이 핵심입니다.
문제 정의
기존 연구들은 언어 모델의 내부 표현(Linear Representations)이 단순하고 고정적인 선형 구조를 가진다고 가정해왔으나, 이 논문은 대화가 진행되는 동안 모델의 맥락(Context)이 내부의 개념적 표현(사실 vs 거짓, 윤리적 vs 비윤리적)을 얼마나 빠르고 극적으로 변화시킬 수 있는지를 탐구하는 문제를 다룹니다.
🔬 방법론 상세
- 선형 탐색(Linear Probing)을 통한 차원 식별: 빈 컨텍스트(Empty Context)에서 모델의 은닉 상태(Hidden State)를 분석하여 ‘사실적’인 답변과 ‘비사실적’인 답변을 가장 잘 구분하는 선형 방향(Vector) $w$를 찾아냅니다. 이를 ‘Factuality Dimension’이라 정의합니다.
- Opposite Day 실험 설계: 모델에게 “오늘은 반대 날(Opposite Day)이다”라고 지시하거나, 모델의 정체성을 바꾸는 대화(예: 차크라에 대해 대화)를 시뮬레이션하여 인위적인 맥락을 주입합니다.
- Factuality Margin 측정: 대화가 진행되는 각 턴(Turn)마다 새로운 질문에 대한 답변의 은닉 상태를 위에서 찾은 $w$에 투영(Projection)합니다. 사실적 답변과 비사실적 답변의 투영 값 차이(Margin)를 계산하여, 대화 맥락이 모델의 사실성 표현을 얼마나 뒤집었는지 정량화합니다.
핵심 기법
Factuality Projection (사실성 투영): 모델의 복잡한 내부 신경망 활성값(Activations) 중에서, ‘진실’과 관련된 정보가 담긴 특정 방향을 찾아내는 기법입니다. 마치 복잡한 데이터 중에서 진실 여부를 가르는 기준선(축)을 하나 뽑아낸 뒤, 대화 도중 모델의 생각이 이 축의 어디에 위치하는지实时으로 관측하는 것과 같습니다.
📊 정량적 결과
주요 성과
- 일반 사실성 정확도: 빈 컨텍스트에서는 **99.0%**였으나, “반대 날(Opposite Day)” 대화 맥락에서는 **11.8%**로 급락했습니다.
- 모델 정체성(Model Identity) 정확도: 빈 컨텍스트 90.0%에서 반대 날 상황 **26.7%**로 감소하여, 모델이 자신이 누구인지에 대한 내부 표현을 망각하고 있음을 보여줍니다.
- 의식(Consciousness) 질문: 차크라(Chakras) 대화 맥락에서는 정확도가 **0%**로 떨어지며, 맥락이 특정 개념의 표현을 완전히 지배할 수 있음을 입증했습니다.
🚀 기존 대비 개선점
- 표현의 동적 관찰: 기존에는 정적인 모델 가중치(Weights) 분석에 그쳤으나, 실제 대화 흐름(Inference time)에 따라 내부 표현이 어떻게 진화(Evolve)하는지 추적했습니다.
- 역할 수행(Role-play) 이론의 강화: 모델의 변화가 ‘신념의 변화’가 아닌 ‘역할에 맞는 표현의 재구성’임을 구조적으로 입증하여, LLM의 윤리적/사실적 판단을 맥락 의존적으로 해석해야 함을 시사합니다.
- 규모의 증상(Scaling Phenomena): 더 큰 모델일수록 이러한 표현의 변화가 더 극적이고 빠르게 일어나는 경향을 발견했습니다.
🎯 활용 분야
- AI 안전성(Safety) 및 적대적 공격 방어: 악의적인 사용자가 대화 맥락을 조작하여 모델의 내부 표현(예: 안전성 차원)을 뒤집는 방식을 이해하고 이를 탐지하는 방어 기술 개발.
- 모델 제어(Steering) 및 개입: 특정 맥락에서 모델이 잘못된 방향(예: 환각, Hallucination)으로 표현이 뒤집히는 것을 실시간으로 감지하고 바로잡는 메커니즘 구축.
- 심리학적/인지과학적 모델링: 인간의 맥락에 따른 신념 변화나 역할 수행 능력을 모방하는 AI 모델 연구.
한계 및 주의사항
- 신념 vs 연기의 모호성: 저자들은 이러한 변화가 모델이 ‘역할을 연기(Role-play)‘하는 것이라고 해석하지만, 실제로 모델이 믿음 체계를 바꾸는 것과 구분하기 어렵다는 철학적 한계가 있습니다.
- 투영의 불안정성: 일부 실험(B.2)에서는 반대 날이 아닐 때도 사실성 표현이 완전히 견고하지(Non-robust) 않은 경우가 관찰되어, 특정 차원(Dimension)만으로는 모델의 상태를 완벽히 설명할 수 없을 수 있습니다.
8. AACR-Bench: Evaluating Automatic Code Review with Holistic Repository-Level Context
arXiv: 2601.19494 | 기관: Aone | ⬆️ 14 | ⭐ 51 🤖 GLM추천 | 📄 HTML 태그:
automated-code-reviewrepository-level-contextllm-benchmarksoftware-engineeringcode-qualityretrieval-augmented-generationevaluation-metrics사전 지식: Automated Code Review (ACR), Pull Request (PR), Ground Truth (정답 데이터), Retrieval-Augmented Generation (RAG), Diff Hunk (코드 변경 조각), Context Window (LLM이 한 번에 처리할 수 있는 입력 길이)

한 줄 요약
기존 벤치마크의 노이즈 문제와 컨텍스트 부족을 해결하여, 다양한 언어와 저장소(Repository) 수준의 전체 맥락을 반영한 고품질의 자동 코드 리뷰(ACR) 평가 환경을 제시함으로써 실제 개발 현장에서의 LLM 성능을 더 정확하게 측정할 수 있게 했습니다.
💡 핵심 아이디어
기존 코드 리뷰 평가는 마치 “수술 도구 하나만 보고 수술 실력을 평가”하는 것처럼 단편적이었습니다. 이 논문은 환자의 전방위 의무기록(파일 전체, 연관된 다른 파일, PR 메타데이터 등)을 모두 제공하여, “전체적인 맥락을 파악하고 수술을 결합할 수 있는 능력”을 평가하도록 환경을 개선했습니다.
문제 정의
- 불완전한 문제 주석(Incomplete Issue Annotation): 기존 벤치마크는 실제 PR(Pull Request)의 코멘트를 그대로 ‘정답(Ground Truth)‘으로 썼는데, 사람 리뷰어가 놓친 버그가 많아 데이터 자체가 불완전했습니다.
- 제한된 맥락 범위(Restricted Context Scope): 코드 버그는 종종 여러 파일에 걸쳐 있지만(Cross-file), 기존 평가는 변경된 코드 조각(Diff Hunk)만 보여주어 실제 성능을 제대로 측정하지 못했습니다.
🔬 방법론 상세
- AI-보조 전문가 검증 파이프라인 (AI-assisted, Human expert-verified):
- LLM을 먼저 활용해 기존 사람 리뷰어가 놓쳤을 수 있는 잠재적 결함(Latent defects)을 발굴합니다.
- 이후 인간 전문가가 모든 리뷰 내용을 엄격하게 검증하여, 기존보다 훨씬 포괄적이고 정확한 정답지를 구축합니다.
- 다층위 컨텍스트 분류 (Context Range Categories):
리뷰 코멘트를 해결하는 데 필요한 정보의 범위에 따라 3단계로 나눕니다.
- Diff 단계: 현재 변경된 코드 조각만 봐도 되는 문제 (754개)
- File 단계: 변경된 코드가 속한 파일 전체를 봐야 하는 문제 (518개)
- Repo 단계: PR 메타데이터나 저장소 내 다른 파일까지 봐야 하는 문제 (233개)
- 다양한 컨텍스트 검색 기법 비교:
모델 성능 평가 시 단순히 코드만 주는 것이 아니라,
BM25,Embedding(Qwen3-Embedding-8B 활용),Agent-based 접근법등 다양한 검색 방식을 통해 정보를 제공하고 그에 따른 성능 차이를 측정합니다.
핵심 기법
“LLM과 사람의 시너지를 통한 데이터 정제” 기존 데이터는 사람이 리뷰한 코멘트만 있었기에 ‘놓친 버그’가 정답에 없었습니다. 이 논문은 LLM을 ‘탐정’처럼 먼저 투입하여 숨겨진 증거(잠재적 버그)를 찾게 하고, 사람 전문가가 ‘판사’가 되서 이를 확정하는 방식으로 정답 데이터의 퀄리티를 획기적으로 높였습니다.
📊 정량적 결과
주요 성과
- 데이터 규모: 50개의 인기 있는 저장소에서 추출한 200개의 PR(Pull Request)과 1,505개의 정밀한 리뷰 코멘트를 구축했습니다.
- 다국어 지원: 10개의 주요 프로그래밍 언어를 포함하여 범용성을 확보했습니다.
- 모델 평가: Qwen3-Coder-480B, DeepSeek-V3.2, GLM-4.7, GPT-5.2, Claude-4.5-Sonet 등 최신 모델들을 평가하여, 컨텍스트 제공 방식에 따라 성능 편차가 크다는 것을 입증했습니다.
🚀 기존 대비 개선점
- 기존: Raw PR 코멘트를 그대로 사용하여, 리뷰어가 발견하지 못한 버그는 평가 대상 자체가 아니었음.
- 개선: LLM 보조 + 사람 검증을 통해 실제 존재하는 버그를 더 폭넓게 정답지에 포함시킴.
- 기존: 단일 파일의 Diff만 보고 리뷰하도록 제한.
- 개선: Repo-level context(저장소 전체 맥락)를 제공하여, 여러 파일에 걸친 복잡한 버그 탐지 능력을 테스트 가능하게 함.
🎯 활용 분야
- 자동 코드 리뷰(ACR) 도구 개발: 실제 기업 환경에서 사용될 LLM 기반 리뷰 봇의 성능을 벤치마킹하는 데 사용.
- RAG(검색 증강 생성) 시스템 최적화: 코드와 관련된 문서를 얼마나 잘 찾아와서 LLM에게 던져줘야 성능이 오르는지 연구하는 용도.
- LLM 에이전트 학습: 코드베이스 전체를 탐색하며 버그를 찾는 소프트웨어 에이전트를 훈련시키는 학습 데이터로 활용.
한계 및 주의사항
- 비용 및 확장성: LLM을 활용해 리뷰를 생성하고 사람이 검증하는 과정이 포함되어 있어, 데이터셋 구축 비용이 매우 높고 대규모로 확장하기 어렵습니다.
- 의존성: LLM이 생성한 리뷰를 보조적으로 활용했으므로, LLM 자체의 편향(Bias)이 데이터셋에 어느 정도 섞여 있을 가능성을 배제할 수 없습니다.
9. SERA: Soft-Verified Efficient Repository Agents
arXiv: 2601.20789 | 기관: AI21 | ⬆️ 8 | ⭐ 93 🤖 GLM추천 | 📄 HTML 태그:
coding-agentsftseraai-efficiencyrepository-agentsoft-verificationllm-finetuningdev-tools사전 지식: Supervised Fine-Tuning (SFT), Reinforcement Learning (강화학습), Coding Agent (코딩 에이전트), Unit Test (단위 테스트), Context Window (컨텍스트 윈도우)

한 줄 요약
복잡한 강화학습 대신 효율적인 지도 학습(SFT) 기법인 SERA를 통해, 기존보다 훨씬 저렴하고 빠르게 사설 코드베이스에 특화된 고품질의 오픈 소스 코딩 에이전트를 구축할 수 있음을 증명한 논문이다.
💡 핵심 아이디어
숙련된 시니어 개발자(교사 모델)가 주니어 개발자(모델)를 가르칠 때, 단순히 “코드가 돌아가냐(테스트 통과 여부)“만 따지는 것이 아니라, “문제를 어떻게 접근하고 코드베이스를 어떻게 탐색했는지(과정과 스킬)“를 평가하여 교육하는 방식이다. 즉, 완벽한 정답 코드를 짜지 못해도 코드를 수정하려는 시도 자체가 의미 있다면 학습 데이터로 활용함으로써, 비싼 강화학습 과정 없이도 뛰어난 성능의 에이전트를 만든다.
문제 정의
오픈 가중치(Open-weight) 모델은 사설 코드베이스에 특화될 수 있다는 잠재력이 있지만, 이를 실현하려면 강화학습(RL)이나 복잡한 합성 데이터 파이프라인이 필요해 비용과 자원이 많이 든다는 것이 기존의 핵심 문제였다.
🔬 방법론 상상
- Soft Verified Generation (SVG): 기존에는 단위 테스트(Unit Test)를 통과한 ‘정답 코드’만 학습 데이터로 썼지만, SERA는 PR(Pull Request)의 정의를 ‘코드베이스를 변경하는 모든 시도’로 확장한다.
- 핵심 통찰: 궤적(Trajectory, 과정)이 패치(Patch, 결과)보다 중요하다. 코드가 완벽하지 않더라도, “의도를 해석하고 코드베이스를 탐색하는 과정”에서 보여준 기술을 학습에 활용한다.
- 알고리즘 flow:
- 교사 모델(Teacher Model, $M$)이 코드베이스($C$)의 함수와 버그 프롬프트를 받아 해결책을 생성(Rollout)한다.
- 이때 생성된 코드가 테스트에 실패하더라도, 문제 해결을 시도한 ‘과정($T$)‘이 유효하다고 판단(Soft Verification)하여 학습 데이터셋에 포함한다.
- 이 데이터를 사용해 모델을 지도 학습(Supervised Finetuning, SFT)한다.
- Teacher-Student Distillation: 강력한 폐쇄형 모델(교사)의 추론 능력을 이용해 고품질 데이터를 생성하고, 이로 작은 오픈 소스 모델(학생)을 훈련시킨다.
핵심 기법
**Soft Verified Generation (SVG)**는 “완벽함” 대신 “노력과 과정”을 인정하는 교육법이다. 기존 방식은 테스트를 통과한 완벽한 정답만 채점했지만, SVG는 리팩토링이나 스타일 수정처럼 테스트로 검증하기 어렵지만 유용한 코드 변경 시도들까지 학습 데이터로 포함시켜 데이터의 다양성과 품질을 높인다.
📊 정량적 결과
주요 성과
- SERA-32B: SWE-bench(추정)에서 **49.5%**의 해결률을 기록하여, 32K 컨텍스트 기준 오픈 소스 최고 수준(SkyRL-Agent 39.4% 등)을 크게 상회하고 강력한 폐쇄형 경쟁작인 Devstral-Small-2(50.0%)와 거의 대등한 성능을 보임.
- SERA-8B: 같은 크기의 모델들(SkyRL-8B: 9.4%, Nex-N1-8B: 20.3%) 대비 압도적인 **31.7%**의 해결률을 기록함.
🚀 기존 대비 개선점
- 비용 효율성: 강화학습(RL) 대비 26배 저렴한 비용으로 모델을 훈련시킬 수 있음.
- 빠른 특화화: 특정 코드베이스에 에이전트를 특화하는 데 단 $1,300 (약 180만 원)의 비용만 소모됨.
- 접근성: 복잡한 분산 훈련 인프라 없이 단순 지도 학습(SFT)만으로도 최고 수준의 성능을 구현 가능하여 개발 진입 장벽을 낮춤.
🎯 활용 분야
- 기업 내부 코딩 에이전트: 회사의 사설 코드베이스(Private Repository)에 특화된 도우미 봇을 저렴하게 개발하여 개발 생산성 향상.
- 자동화된 리팩토링: 단순 버그 수정뿐만 아니라 코드 스타일 개선이나 리팩토링을 수행하는 자동화 PR 생성 도구 개발.
- 맞춤형 개발 보조: 도메인별 지식이 필요한 특정 프로젝트에 맞춘 튜닝된 AI 개발자 도구 제작.
한계 및 주의사항
- 교사 모델 의존성: 데이터 생성 과정에서 강력한 교사 모델(예: GLM-4.6, Claude 등)에 의존하므로, 교사 모델의 능력 한계가 곧 학생 모델의 성능 상한이 될 수 있음.
- 테스트 중심 평가: SWE-bench 같은 벤치마크에서의 성능은 높지만, 실제 복잡한 장기간 프로젝트에서의 유지보수 능력은 추가 검증이 필요할 수 있음.
10. OmegaUse: Building a General-Purpose GUI Agent for Autonomous Task Execution
arXiv: 2601.20380 | ⬆️ 8 🤖 GLM추천 | 📄 HTML 태그:
gui-agentomegausereinforcement-learninghuman-computer-interactionmodel-trainingdata-pipelinegroundingnavigation사전 지식: GUI Agent, Reinforcement Learning (강화학습), Mixture of Experts (MoE), Fine-Tuning, Multimodal Learning

한 줄 요약
모바일과 데스크톱을 통합한 최초의 범용 GUI 에이전트인 OmegaUse를 제안하여, 데이터와 훈련 방식의 혁신으로 실제 디지털 환경에서의 자율 작업 수행 성능을 획기적으로 향상시켰기 때문에 중요합니다.
💡 핵심 아이디어
OmegaUse는 자동차의 운전자와 내비게이션 시스템을 분리한 것과 같습니다. ‘그라운딩 모델’은 “지금 저기 신호등을 보세요”와 같은 구체적인 시각 지시를 정확한 좌표로 찾아내는 운전자의 손발 역할을, ‘네비게이션 모델’은 “집으로 가자”라는 목표를 달성하기 위해 단계별 경로를 계획하는 내비게이션 역할을 합니다. 이렇게 역할을 나눠 전문성을 높인 것이죠.
문제 정의
기존 GUI 에이전트들은 성능 저하, 저품질 훈련 데이터, 그리고 다양한 디지털 환경(모바일, 데스크톱)을 아우르는 종합적인 평가 부재라는 세 가지 큰 문제에 직면해 있었습니다. OmegaUse는 이 문제들을 해결하는 것을 목표로 합니다.
🔬 방법론 상세
- 분리 훈련 패러다임 (Decoupled Training Paradigm): ‘그라운딩 모델(시각적 인식)‘과 ‘네비게이션 모델(순차적 의사결정)‘을 별도로 훈련시켜, 저수준 공간 인식과 고수준 추론 간의 간섭을 줄입니다.
- 하이브리드 데이터 파이프라인: 6개의 공개 데이터셋을 통합하고, LLM(거대 언어 모델)의 자동 주석과 인간 검수를 결합하여 고품질의 데이터를 구축합니다.
- GRPO 기반 강화학습: 분리된 두 모델 각각에 맞는 보상(reward)을 설계하여 GRPO(Group Relative Policy Optimization, 특정 그룹 내에서의 상대적인 정책 성능을 최적화하는 강화학습 알고리즘) 알고리즘으로 최적화합니다.
핵심 기법
가장 핵심적인 기법은 **‘분리 훈련 패러다임’**입니다. 하나의 거대한 모델이 모든 것을 처리하도록 강요하는 대신, ‘무엇을 누를지(그라운딩)’ 정확히 찾는 전문가와 ‘다음 행동을 무엇을 할지(네비게이션)’ 결정하는 전문가를 따로 훈련시킵니다. 이는 마치 셰프(요리 전문가)와 서빙 직원(고객 응대 전문가)이 각자의 역할에 집중하여 레스토랑의 효율을 극대화하는 것과 같은 원리입니다.
📊 정량적 결과
주요 성과
- 새로운 벤치마크(OS-Nav) 개발: 중국 안드로이드(ChiM-Nav: 142개 궤적, 69개 앱, 총 991단계)와 우분투 데스크톱(Ubu-Nav) 환경을 포함하는 종합 평가 데이터셋을 공개했습니다.
- ScreenSpot-V2 벤치마크 경쟁력: 제공된 텍스트에 따르면, 이 벤치마크에서 UI-TARS-1.5 모델이 **94.2%**의 평균 성공률을 기록했으며, GPT-4o는 **20.1%**를 기록했습니다. (논문 본문에는 OmegaUse의 정확한 수치가 제공된 부분이 포함되지 않아 직접적인 비교는 어렵습니다.)
🚀 기존 대비 개선점
- 범용성 확보: 컴퓨터-use와 폰-use를 위한 별도 모델이 아닌, OmegaUse 하나로 여러 플랫폼에서 작동하는 범용 에이전트를 구현했습니다.
- 데이터 품질 및 양 증대: 기존 데이터셋을 단순히 모으는 것을 넘어, LLM 자동 생성과 인간 검수를 결합한 정교한 파이프라인으로 훈련 데이터의 양과 질을 동시에 끌어올렸습니다.
- 성능 및 안정성 향상: 모델을 분리하여 훈련함으로써 각 역할에 특화된 성능을 극대화하고, 복잡한 단일 모델 훈련에서 발생할 수 있는 간섭 현상을 회피했습니다.
🎯 활용 분야
- 지능형 RPA (Robotic Process Automation): 반복적인 사무 작업(예: 데이터 입력, 보고서 생성)을 모바일과 PC 환경에서 자동화하여 생산성을 극대화할 수 있습니다.
- AI 비서 및 접근성 향상: “카톡으로 엄마한테 사진 보내줘”와 같은 자연어 명령을 받아 실제 기기에서 작업을 수행하는 고도화된 AI 비서를 만들거나, 신체적 제약이 있는 사용자를 위한 접근성 도구로 활용될 수 있습니다.
- 소프트웨어 테스트 자동화: 앱이나 프로그램의 UI를 실제 사용자처럼 조작하며 버그를 찾는 QA(Quality Assurance) 프로세스를 자동화하는 데 사용될 수 있습니다.
한계 및 주의사항
- 실행 환경 의존성: 실제 앱이나 OS의 UI 변경에 매우 민감할 수 있습니다. 앱 업데이트 시 에이전트의 성능이 저하될 수 있다는 점을 인지해야 합니다.
- 높은 계산 비용: 두 개의 전문화된 모델(그라운딩, 네비게이션)과 MoE(전문가 혼합, Mixture of Experts) 구조를 사용하므로, 추론(inference) 시 상당한 컴퓨팅 자원이 필요할 수 있습니다.
📅 생성일: 2026-01-29 | 🤖 GLM-4.7